原英文:https://rviews.rstudio.com/2017/09/25/survival-analysis-with-r/,有删改。想要细致地研究,不妨读一读。
导入数据
第一个代码块导入所需要的包以及survival包中的数据集veteran,包含两种肺癌治疗的随机试验。
library(survival)
library(ranger)
library(ggplot2)
library(dplyr)
library(ggfortify)
#------------
data(veteran)
head(veteran)
## trt celltype time status karno diagtime age prior
## 1 1 squamous 72 1 60 7 69 0
## 2 1 squamous 411 1 70 5 64 10
## 3 1 squamous 228 1 60 3 38 0
## 4 1 squamous 126 1 60 9 63 10
## 5 1 squamous 118 1 70 11 65 10
## 6 1 squamous 10 1 20 5 49 0
变量说明:
-
trt: 1=standard 2=test -
celltype: 1=squamous, 2=small cell, 3=adeno, 4=large -
time: survival time in days -
status: censoring status -
karno: Karnofsky performance score (100=good) -
diagtime: months from diagnosis to randomization -
age: in years -
prior: prior therapy 0=no, 10=yes
Kaplan Meier 分析
第一件要做的事情是使用Surv()构建一个标准的生存对象。变量time记录生存时间;status显示是否病人已经死亡(status=1)或截尾(status=0)。注意打印输出时间后的+表示截尾。
# Kaplan Meier Survival Curve
km <- with(veteran, Surv(time, status))
head(km,80)
## [1] 72 411 228 126 118 10 82 110 314 100+ 42 8 144 25+
## [15] 11 30 384 4 54 13 123+ 97+ 153 59 117 16 151 22
## [29] 56 21 18 139 20 31 52 287 18 51 122 27 54 7
## [43] 63 392 10 8 92 35 117 132 12 162 3 95 177 162
## [57] 216 553 278 12 260 200 156 182+ 143 105 103 250 100 999
## [71] 112 87+ 231+ 242 991 111 1 587 389 33
我们先使用 Surv(futime, status) ~ 1 和 survfit() 函数生成随时间变化的生存概率Kaplan-Meier 估计。summary()函数的``time`参数可以控制要打印的时间。
km_fit <- survfit(Surv(time, status) ~ 1, data=veteran)
summary(km_fit, times = c(1,30,60,90*(1:10)))
## Call: survfit(formula = Surv(time, status) ~ 1, data = veteran)
##
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 1 137 2 0.985 0.0102 0.96552 1.0000
## 30 97 39 0.700 0.0392 0.62774 0.7816
## 60 73 22 0.538 0.0427 0.46070 0.6288
## 90 62 10 0.464 0.0428 0.38731 0.5560
## 180 27 30 0.222 0.0369 0.16066 0.3079
## 270 16 9 0.144 0.0319 0.09338 0.2223
## 360 10 6 0.090 0.0265 0.05061 0.1602
## 450 5 5 0.045 0.0194 0.01931 0.1049
## 540 4 1 0.036 0.0175 0.01389 0.0934
## 630 2 2 0.018 0.0126 0.00459 0.0707
## 720 2 0 0.018 0.0126 0.00459 0.0707
## 810 2 0 0.018 0.0126 0.00459 0.0707
## 900 2 0 0.018 0.0126 0.00459 0.0707
#plot(km_fit, xlab="Days", main = 'Kaplan Meyer Plot') #基本绘图方式
autoplot(km_fit)
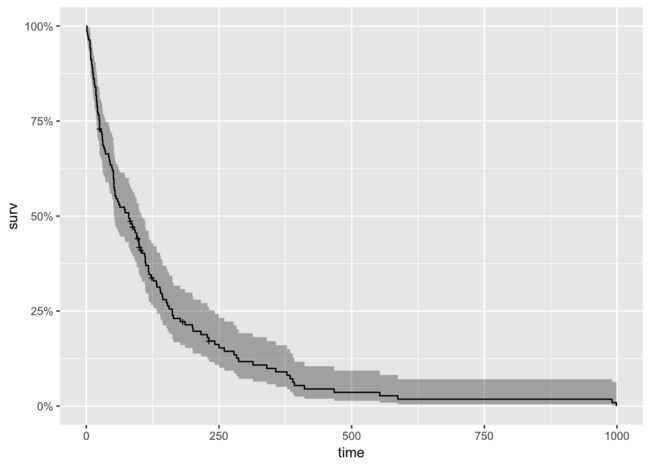
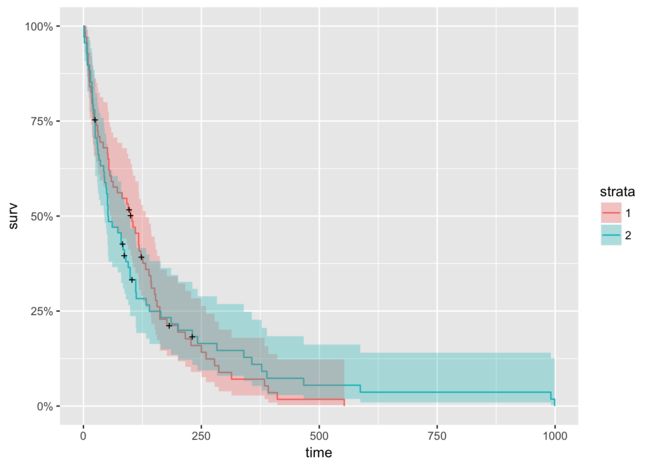
接下来,我们查看按治疗方式分组的生存曲线。
km_trt_fit <- survfit(Surv(time, status) ~ trt, data=veteran)
autoplot(km_trt_fit)
下面做些更精细的处理,将年龄也分为两种,治疗变量设为因子类型。
vet <- mutate(veteran, AG = ifelse((age < 60), "LT60", "OV60"),
AG = factor(AG),
trt = factor(trt,labels=c("standard","test")),
prior = factor(prior,labels=c("N0","Yes")))
km_AG_fit <- survfit(Surv(time, status) ~ AG, data=vet)
autoplot(km_AG_fit)
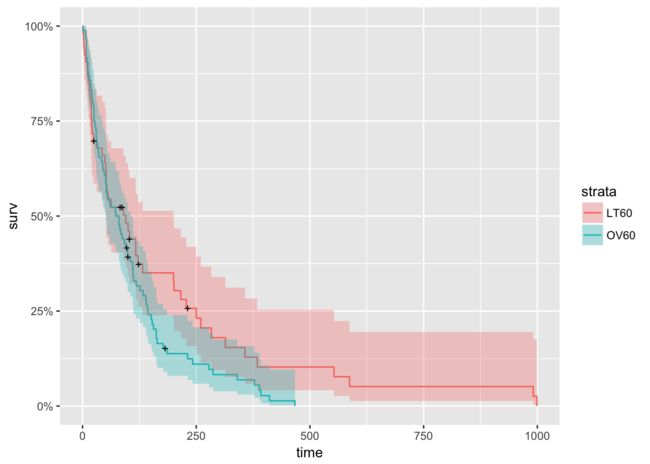
虽然两条曲线在开始50天是重叠的,但接下来的曲线走向说明更年轻的病人活得更久。
Cox 比例风险模型
接下来我将使用使用Cox Proportional Hazards Model用来将数据集中所有的协变量拟合进模型。
# Fit Cox Model
cox <- coxph(Surv(time, status) ~ trt + celltype + karno + diagtime + age + prior , data = vet)
summary(cox)
## Call:
## coxph(formula = Surv(time, status) ~ trt + celltype + karno +
## diagtime + age + prior, data = vet)
##
## n= 137, number of events= 128
##
## coef exp(coef) se(coef) z Pr(>|z|)
## trttest 2.946e-01 1.343e+00 2.075e-01 1.419 0.15577
## celltypesmallcell 8.616e-01 2.367e+00 2.753e-01 3.130 0.00175 **
## celltypeadeno 1.196e+00 3.307e+00 3.009e-01 3.975 7.05e-05 ***
## celltypelarge 4.013e-01 1.494e+00 2.827e-01 1.420 0.15574
## karno -3.282e-02 9.677e-01 5.508e-03 -5.958 2.55e-09 ***
## diagtime 8.132e-05 1.000e+00 9.136e-03 0.009 0.99290
## age -8.706e-03 9.913e-01 9.300e-03 -0.936 0.34920
## priorYes 7.159e-02 1.074e+00 2.323e-01 0.308 0.75794
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## trttest 1.3426 0.7448 0.8939 2.0166
## celltypesmallcell 2.3669 0.4225 1.3799 4.0597
## celltypeadeno 3.3071 0.3024 1.8336 5.9647
## celltypelarge 1.4938 0.6695 0.8583 2.5996
## karno 0.9677 1.0334 0.9573 0.9782
## diagtime 1.0001 0.9999 0.9823 1.0182
## age 0.9913 1.0087 0.9734 1.0096
## priorYes 1.0742 0.9309 0.6813 1.6937
##
## Concordance= 0.736 (se = 0.03 )
## Rsquare= 0.364 (max possible= 0.999 )
## Likelihood ratio test= 62.1 on 8 df, p=2e-10
## Wald test = 62.37 on 8 df, p=2e-10
## Score (logrank) test = 66.74 on 8 df, p=2e-11
cox_fit <- survfit(cox)
#plot(cox_fit, main = "cph model", xlab="Days")
autoplot(cox_fit)
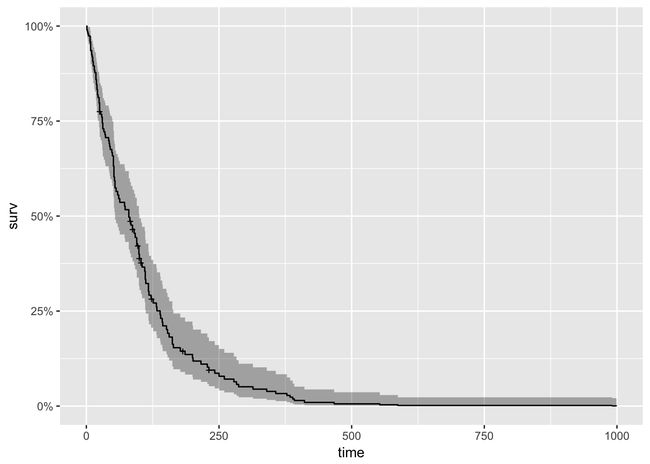
注意模型结果标记了几种细胞类型统计显著。然而,在解释这些结果是需要留心。虽然Cox比例风险模型被认为是鲁棒的,然后细心的分析应该检查模型的假设。例如,Cox模型假设协变量不随时间变化。survival包的手册( vignette)说明了karno变量是随时间变化的,因为不满足模型假设。
我们可以利用Aalen模型观察变量随时间的变化,注意下面karno变量陡峭的斜率以及之后斜率突然的变化。
aa_fit <-aareg(Surv(time, status) ~ trt + celltype +
karno + diagtime + age + prior ,
data = vet)
aa_fit
## Call:
## aareg(formula = Surv(time, status) ~ trt + celltype + karno +
## diagtime + age + prior, data = vet)
##
## n= 137
## 75 out of 97 unique event times used
##
## slope coef se(coef) z p
## Intercept 0.083400 3.81e-02 1.09e-02 3.490 4.79e-04
## trttest 0.006730 2.49e-03 2.58e-03 0.967 3.34e-01
## celltypesmallcell 0.015000 7.30e-03 3.38e-03 2.160 3.09e-02
## celltypeadeno 0.018400 1.03e-02 4.20e-03 2.450 1.42e-02
## celltypelarge -0.001090 -6.21e-04 2.71e-03 -0.229 8.19e-01
## karno -0.001180 -4.37e-04 8.77e-05 -4.980 6.28e-07
## diagtime -0.000243 -4.92e-05 1.64e-04 -0.300 7.65e-01
## age -0.000246 -6.27e-05 1.28e-04 -0.491 6.23e-01
## priorYes 0.003300 1.54e-03 2.86e-03 0.539 5.90e-01
##
## Chisq=41.62 on 8 df, p=1.6e-06; test weights=aalen
#summary(aa_fit) # provides a more complete summary of results
autoplot(aa_fit)

随机森林模型
最后,我们使用随机森林模型研究一下数据集。ranger()函数为数据集中的每个观测构建模型。下面的代码块使用跟Cox模型相同的变量,绘制20条随机曲线,和一条总体平均线。
# ranger model
r_fit <- ranger(Surv(time, status) ~ trt + celltype +
karno + diagtime + age + prior,
data = vet,
mtry = 4,
importance = "permutation",
splitrule = "extratrees",
verbose = TRUE)
# Average the survival models
death_times <- r_fit$unique.death.times
surv_prob <- data.frame(r_fit$survival)
avg_prob <- sapply(surv_prob,mean)
# Plot the survival models for each patient
plot(r_fit$unique.death.times,r_fit$survival[1,],
type = "l",
ylim = c(0,1),
col = "red",
xlab = "Days",
ylab = "survival",
main = "Patient Survival Curves")
#
cols <- colors()
for (n in sample(c(2:dim(vet)[1]), 20)){
lines(r_fit$unique.death.times, r_fit$survival[n,], type = "l", col = cols[n])
}
lines(death_times, avg_prob, lwd = 2)
legend(500, 0.7, legend = c('Average = black'))
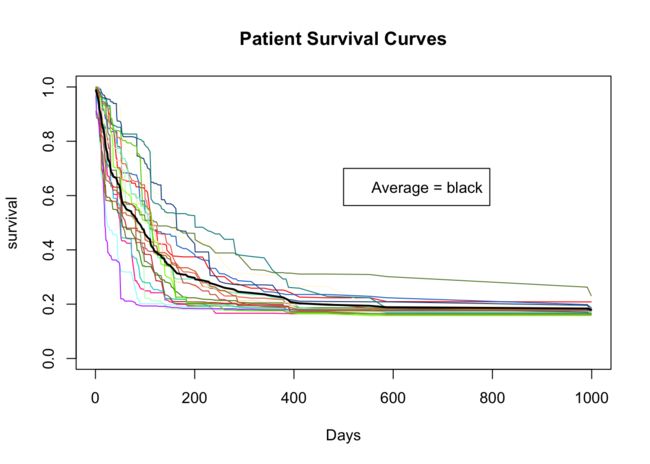
下面的代码块使用ranger() 为变量的重要性排序。
vi <- data.frame(sort(round(r_fit$variable.importance, 4), decreasing = TRUE))
names(vi) <- "importance"
head(vi)
## importance
## karno 0.0903
## celltype 0.0323
## diagtime -0.0012
## trt -0.0013
## prior -0.0027
## age -0.0037
注意ranger()函数标记了karno和celltype是最重要的两个,这跟Cox最小2个p值变量是相同的。同样注意这里给出的是变量名而不是因子水平名字。
ranger() 计算Harrell’s c-index ,它跟Concordance统计量相似。ROC曲线值可以由下面代码计算:
cat("Prediction Error = 1 - Harrell's c-index = ", r_fit$prediction.error)
## Prediction Error = 1 - Harrell's c-index = 0.3087233
0.68对于第一次尝试来说还可以了,不过这里还是没有解决随时间变化的系数问题,2011年文章有提到
However, in the context of survival trees, a further difficulty arises when time–varying effects are included. Hence, we feel that the interpretation of covariate effects with tree ensembles in general is still mainly unsolved and should attract future research.
我相信基于树的生存模型都是用来处理非常大的数据集。
最后,提供3种生存曲线的直观比较,把它们画到同一个图上。
# Set up for ggplot
kmi <- rep("KM",length(km_fit$time))
km_df <- data.frame(km_fit$time,km_fit$surv,kmi)
names(km_df) <- c("Time","Surv","Model")
coxi <- rep("Cox",length(cox_fit$time))
cox_df <- data.frame(cox_fit$time,cox_fit$surv,coxi)
names(cox_df) <- c("Time","Surv","Model")
rfi <- rep("RF",length(r_fit$unique.death.times))
rf_df <- data.frame(r_fit$unique.death.times,avg_prob,rfi)
names(rf_df) <- c("Time","Surv","Model")
plot_df <- rbind(km_df,cox_df,rf_df)
p <- ggplot(plot_df, aes(x = Time, y = Surv, color = Model))
p + geom_line()
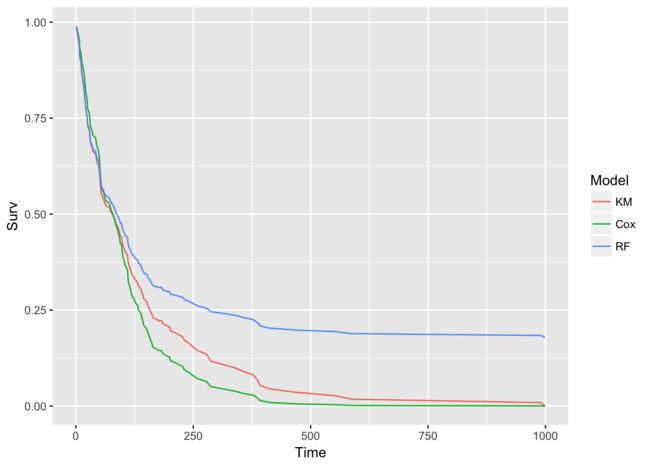
对于这个数据集,我个人倾向Cox模型。ranger()表现不是特别好,可能的原因是变量和样本量都不多。