Standalone运行方式 –master spark://sparkmaster:7077
采用Spark自带的资源管理器进行集群资源管理
//standalone运行,指定--master spark://sparkmaster:7077
//采用本地文件系统,也可采用HDFS
//没有指定deploy-mode,默认为client deploy mode
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master spark://sparkmaster:7077
--class SparkWordCount --executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar
file:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
file:/SparkWordCountResult2

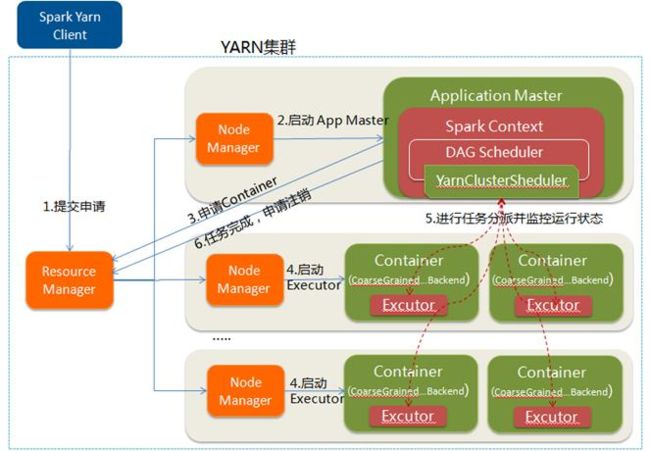
Yarn运行方式
采用Yarn作为底层资源管理器
//Yarn Cluster
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master yarn-cluster
--class org.apache.spark.examples.SparkPi
--executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar
//Yarn Client
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master yarn-client
--class org.apache.spark.examples.SparkPi
--executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar
