![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第1张图片](http://img.e-com-net.com/image/info10/c5a05dcf4b5b4c679f12a2f10ae21fb4.jpg)
本文介绍的论文是:《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》
关于召回阶段的算法,以youtube DNN为代表的向量化召回方式是目前的主流算法之一,但是目前的大多数算法仅仅将用户的兴趣表示成单个的Embedding,这是不足以表征用户多种多样的兴趣的,同时容易造成头部效应。因此本文提出了MIND,同时生成多个表征用户兴趣的Embedding,来提升召回阶段的效果,一起来学习一下。
1、背景
在天猫的推荐过程中,推荐系统也被拆分为召回和排序阶段。
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第2张图片](http://img.e-com-net.com/image/info10/bb9d7ee0ec924360ae3e3dbe3b73d9ae.jpg)
本文重点关注召回阶段的算法。召回阶段的目标是得到数千个跟用户兴趣紧密相关的商品候选集。在天猫场景下,用户每天都要与成百上千的商品发生交互,用户的兴趣表现得多种多样。如下图所示,不同的用户之间兴趣不相同,同时同一个用户也会表现出多样的兴趣:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第3张图片](http://img.e-com-net.com/image/info10/b1af68a4ca424827b7e3c024efef9397.jpg)
因此,对于用户兴趣的建模显得至关重要。目前召回阶段主流的算法是协同过滤和向量化召回。协同过滤面临稀疏性的问题。而向量化召回方法如youtube dnn,将用户的兴趣表示成一个固定长度的向量。
但在天猫场景下,对于用户多样化的兴趣,一个Embedding往往是不够的,除非这个Embedding的长度足够大,具有足够的表征能力。除此之外,只有一个Embedding会造成一定的头部效应,召回的结果往往是比较热门领域的商品(头部问题),对于较为小众领域的商品,召回能力不足。
解决上述问题的方法也很简单,搞多个用户Embedding就好了嘛,而本文要介绍的MIND,正是通过生成多个表征用户兴趣的Embedding,来提升召回阶段的效果,一起来学习一下。(昨天听了俊林老师的讲座,这个方向也是他比较看好的)
2、MIND
2.1 问题概述
召回阶段的目标是对于每个用户u∈U的请求,从亿级的商品池I中,选择成百上千的符合用户兴趣的商品候选集。每条样本可以表示成三元组(Iu,Pu,Fi),其中Iu是用户u历史交互过的商品集合,Pu是用户画像信息,比如年龄和性别,Fi是目标商品的特征,如商品ID、商品品类ID。
那么MIND的核心任务是将用户相关的特征转换成一系列的用户兴趣向量:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第4张图片](http://img.e-com-net.com/image/info10/8ba7b0fe9b74448090fb0f1b5a1e7875.jpg)
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第5张图片](http://img.e-com-net.com/image/info10/d8adda30c7e3476aac3d78f08e7ab498.jpg)
而目标商品向量Fi也被转换为一个Embedding:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第6张图片](http://img.e-com-net.com/image/info10/52968d01551749539d53284a74f1400d.jpg)
当得到用户和商品的向量表示之后,通过如下的score公式计算得到topN的商品候选集:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第7张图片](http://img.e-com-net.com/image/info10/ba64142afca84a9092317434da251e37.jpg)
整个MIND的框架如下:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第8张图片](http://img.e-com-net.com/image/info10/fa8808f8b67d4eb5bd859d277abdb119.jpg)
接下来,详细介绍MIND中的各部分。
2.2 Embedding Layer
如上图,MIND的输入中包含三部分,用户的画像信息Pu、用户历史行为Iu和目标商品Fi。每个部分都包含部分的类别特征,类别特征会转换为对应的embedding。对用户画像信息部分来说,不同的embedding最终拼接在一起。而对于用户历史行为Iu中的商品和目标商品Fi来说,商品ID、品牌ID、店铺ID等转换为embedding后会经过avg-pooling layer来得到商品的embedding表示。
2.3 Multi-Interest Extractor Layer
接下来是最为关键的 Multi-Interest Extractor Layer,这里借鉴的是Hiton提出的胶囊网络。有关胶囊网络,下面的图可以帮助你快速理解(图片来源于知乎:https://zhuanlan.zhihu.com/p/68897114):
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第9张图片](http://img.e-com-net.com/image/info10/e41bd1082dd54e8cb02329e0f7057791.jpg)
可以看到,胶囊网络和传统的神经网络较为类似。传统神经网络输入一堆标量,首先对这堆标量进行加权求和,然后通过非线性的激活函数得到一个标量输出。而对胶囊网络来说,这里输入的是一堆向量,首先对这组向量进行仿射变换,然后进行加权求和,随后通过非线性的"squash"方程进行变换,得到另一组向量的输出。
而MIND中的Multi-Interest Extractor Layer,与胶囊网络主要有两个地方不同:
1)在胶囊网络中,每一个输入向量和输出向量之间都有一个单独的仿射矩阵,但是MIND中,仿射矩阵只有一个,所有向量之间共享同一个仿射矩阵。主要原因是用户的行为数量长度不同,使用共享的仿射矩阵不仅可以减少参数,同时还能对应另一处的改变,即不同用户输出向量的个数K是基于他历史行为长度自适应计算的:
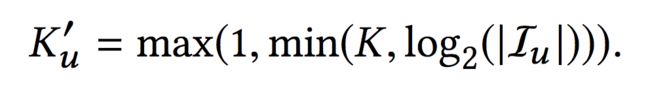
上面基于用户历史行为长度自适应计算输出向量个数K'的策略,对于那些交互行为较少的用户来说,可以减少这批用户的存储资源。
2)为了适应第一个改变,胶囊网络中权重的初始化由全部设置为0变为基于正太分布的初始化。
下图是整个Multi-Interest Extractor Layer的过程:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第10张图片](http://img.e-com-net.com/image/info10/865fb972112c46648021018a2e8606ae.jpg)
通过Multi-Interest Extractor Layer,得到了多个用户向量表示。接下来,每个向量与用户画像embedding进行拼接,经过两层全连接层(激活函数为Relu)得到多个用户兴趣向量表示。每个兴趣向量表征用户某一方面的兴趣。
2.4 Label-aware Attention Layer
在上一步得到用户兴趣向量之后,由于不同用户的兴趣向量个数不同,通过Label-aware Attention Layer对这些向量进行加权(只应用于训练阶段),类似DIN中的做法:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第11张图片](http://img.e-com-net.com/image/info10/f9ded9079ed643d38f43b8ecbf1f2aac.jpg)
而计算公式为:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第12张图片](http://img.e-com-net.com/image/info10/a6544f616fe241909806c615ee4bcee2.jpg)
上图中的Q相当于目标商品的embedding,K和V都是用户的兴趣向量。值得注意的一点是,在softmax的时候,对得到的attention score,通过指数函数进行了一定的缩放。当p接近0时(这里应该是假设了向量的内积大于1吧),对softmax是一种平滑作用,使得各attention score大小相近,当p>1且不断增加时,对softmax起到的是一种sharpen作用,attention score最大那个兴趣向量,在sofamax之后对应的权重越来越大,此时更类似于一种hard attention,即直接选择attention score最大的那个向量。实验表明hard attention收敛速度更快。
2.5 Training & Serving
在训练阶段,使用经过Label-aware Attention Layer得到的用户向量和目标商品embedding,计算用户u和商品i交互的概率(这里和youtube DNN相似,后文中说也进行了采样):
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第13张图片](http://img.e-com-net.com/image/info10/e8de160b30b64074b58a9242dab6e856.jpg)
而目标函数(而非损失函数)为:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第14张图片](http://img.e-com-net.com/image/info10/9ca4048b2cdc47f28632cd327e6b2740.jpg)
而在线上应用阶段,只需要计算用户的多个兴趣向量,然后每个兴趣向量通过最近邻方法(如局部敏感哈希LSH)来得到最相似的候选商品集合。同时,当用户产生了一个新的交互行为,MIND也是可以实时响应得到用户新的兴趣向量的。
3、实验结果
接下来看下实验结果。
对于离线实验,文中使用MIND和BASE模型(如youtube DNN)等进行了对比,结果如下:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第15张图片](http://img.e-com-net.com/image/info10/3b0addde117d40ebb4174f86c5947e0d.jpg)
而在线上实验时,为了进行对比,不同的召回模型都使用同样的排序模型作为下游,并比较了一周内不同实验组的CTR:
![推荐系统遇上深度学习(七十四)-[天猫]MIND:多兴趣向量召回_第16张图片](http://img.e-com-net.com/image/info10/b5feb21a64974630b3c1c72b4007899a.jpg)
可以看到,无论是线上还是线下实验,MIND都取得了不错的效果。
4、总结
目前召回阶段,有几个值得不错的方向,比如MIND中的用户兴趣多Embedding拆分和基于Graph的召回,大伙不妨可以尝试一下。