所以代码附上GitHub:https://github.com/GreenArrow2017/DataStructure_Java/tree/master/out/production/DataStructure_Java/ApplicationOfAlgorithm
排序可视化
SelectionSort
选择排序很简单,所有的排序算法在前面的博客都有讲解:
https://www.jianshu.com/p/7fbf8671c742
选择排序很简单,遍历所有元素,查看一下他们的之后最小的元素和当前元素交换即可。模板函数使用上面的swing模板。为了更清楚显示出排序的过程,可以用不同颜色代表排好序和未排好序的。
int w = canvasWidth / data.N();
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.LightBlue);
for (int i = 0; i < data.N(); i++) {
if (i < data.orderIndex) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Red);
} else {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Grey);
}
if (i == data.currentIndex) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Indigo);
}
if (i == data.currentComperent) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.LightBlue);
}
AlgorithmHelper.fillRectangle(graphics2D, i * w, canvasHeight - data.get(i), w - 1, data.get(i));
}
}
Frame的画图函数主要构成部分,其余的都是模板,为了抽象性,所以把selection的数据集中起来形成一个新的类,包括了生成数据等等。
public class SelectionSortData {
private int[] numbers;
public int orderIndex = -1;
public int currentIndex = -1;
public int currentComperent = -1;
public SelectionSortData(int N, int randomBound) {
numbers = new int[N];
for (int i = 0; i < N; i++) {
numbers[i] = (int) (Math.random() * randomBound) + 1;
//System.out.println(numbers[i]);
}
}
public void setData(int orderIndex, int currentComperent, int currentIndex){
this.currentIndex = currentIndex;
this.currentComperent = currentComperent;
this.orderIndex = orderIndex;
}
public int N(){
return numbers.length;
}
public int get(int index){
if (index < 0 || index >= numbers.length){
throw new IllegalArgumentException("index is illgel!");
}
return numbers[index];
}
public void swap(int i, int j){
int t = numbers[i];
numbers[i] = numbers[j];
numbers[j] = t;
}
}
在这个数据类里面有三个属性,分别是已经排好序的索引,当前最小值,当前正在比较的索引。在渲染过程中需要改变就是这几个颜色了。所以动态的效果主要来源就是通过改变着几个值即可。
private void run() {
data.setData(0,-1,-1);
frame.render(data);
AlgorithmHelper.pause(DELAY);
for (int i = 0; i < data.N(); i++) {
int midIndex = i;
data.setData(i, -1, midIndex);
frame.render(data);
AlgorithmHelper.pause(DELAY);
for (int j = i+1; j < data.N(); j++) {
data.setData(i, j, midIndex);
frame.render(data);
AlgorithmHelper.pause(DELAY);
if (data.get(j) < data.get(midIndex)){
midIndex = j;
data.setData(i, j, midIndex);
frame.render(data);
AlgorithmHelper.pause(DELAY);
}
}
data.swap(i, midIndex);
data.setData(i+1, -1, -1);
frame.render(data);
AlgorithmHelper.pause(DELAY);
}
data.setData(data.N(), -1,-1);
frame.render(data);
AlgorithmHelper.pause(DELAY);
}
查看一下效果:
InsertionSort
插入排序也很简单,没有涉及到递归操作等等。每遍历一个元素,看看这个元素和之前比较过的位置是在那里,像打牌的时候插排一样。和之前的查找一样,已经排好序的位置就直接用红色表示,当前对比位置用蓝色表示。首先是画图paintComponent:
int w = canvasWidth / data.N();
for (int i = 0; i < data.N(); i++) {
if (i < data.orderIndex){
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Red );
}else {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Grey);
}
if (i == data.currentIndex){
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.LightBlue);
}
AlgorithmHelper.fillRectangle(graphics2D, i * w, canvasHeight - data.get(i), w - 1, data.get(i));
}
}
和上面的选择排序差不多。
private void run() {
setData(-1, -1);
for (int i = 0; i < data.N(); i++) {
setData(i, i);
for (int j = i; j > 0 && data.get(j) < data.get(j - 1); j--) {
data.swap(j, j - 1);
setData(i+1, j-1);
}
setData(i, -1);
}
setData(data.N(), -1);
}
private void setData(int orderIndex, int currentIndex){
data.orderIndex = orderIndex;
data.currentIndex = currentIndex;
frame.render(data);
AlgorithmHelper.pause(DELAY);
}
都是常规操作。
MergeSort
归并排序本身的思路,面对一个数组想要让他排序,首先把数组分成两部分,用同样的算法把两边排序,最后归并两边。在划分的时候,划分到不能再划分为止。首先同样要有一个归并的数据类:
public class MergeData {
private int[] numbers;
public int l, r;
public int mergeIndex;
public MergeData(int N, int randomBound) {
numbers = new int[N];
for (int i = 0; i < N; i++) {
numbers[i] = (int) (Math.random() * randomBound) + 1;
//System.out.println(numbers[i]);
}
}
public int N(){
return numbers.length;
}
public int get(int index){
if (index < 0 || index >= numbers.length){
throw new IllegalArgumentException("index is illgel!");
}
return numbers[index];
}
public void set(int index, int num){
if (index < 0 || index >= numbers.length){
throw new IllegalArgumentException("index is illgel!");
}
numbers[index] = num;
}
public void swap(int i, int j){
int t = numbers[i];
numbers[i] = numbers[j];
numbers[j] = t;
}
}
用l和r来表示正在归并的数组范围,mergeIndex表示已经进行归并了的集合。归并整个过程前面的博客有写,不再复述了。
private void run() {
setData(-1, -1, -1 );
Merge(0, data.N()-1);
setData(0, data.N()-1, -1);
}
private void Merge(int l, int r) {
if (l >= r) {
return;
}
setData(l, r, -1);
int mid = (l + r) / 2;
Merge(l, mid);
Merge(mid + 1, r);
merge(l, r, mid);
}
private void merge(int l, int r, int mid) {
int[] array = new int[r - l + 1];
for (int i = l; i <= r; i++) {
array[i - l] = data.get(i);
}
int i = l, j = mid + 1;
int index = l;
while (i <= mid && j <= r) {
if (array[i - l] < array[j - l]) {
data.set(index, array[i - l]);
i++;
index++;
} else {
data.set(index, array[j - l]);
j++;
index++;
}
setData(l, r, index);
}
if (i <= mid) {
for (int k = i; k <= mid; k++) {
data.set(index, array[k - l]);
index++;
setData(l, r, index);
}
} else if (j <= r) {
for (int k = j; k <= r; k++) {
data.set(index, array[k - l]);
index++;
setData(l, r, index);
}
}
}
效果:

QuickSort
快速排序,快速排序是在平均情况下比较快的算法了。每一次把第一个元素作为标定的位置,把这个位置放到合适的位置即可。首先还是需要一个快拍数据类:
public class QuickSortData {
private int[] numbers;
public int l, r;
public int Index;
public QuickSortData(int N, int randomBound) {
numbers = new int[N];
for (int i = 0; i < N; i++) {
numbers[i] = (int) (Math.random() * randomBound) + 1;
//System.out.println(numbers[i]);
}
}
public int N(){
return numbers.length;
}
public int get(int index){
if (index < 0 || index >= numbers.length){
throw new IllegalArgumentException(index + "index is illgel!");
}
return numbers[index];
}
public void set(int index, int num){
if (index < 0 || index >= numbers.length){
throw new IllegalArgumentException("index is illgel!");
}
numbers[index] = num;
}
public void swap(int i, int j){
int t = numbers[i];
numbers[i] = numbers[j];
numbers[j] = t;
}
}
和前面的归并排序一样,l和r用不同的颜色。
private void run() {
setData(-1, -1, -1);
QuickSort(0, data.N() - 1);
setData(0, data.N() - 1, -1);
}
private void QuickSort(int l, int r) {
if (l >= r) {
return;
}
setData(l, r, -1);
int mid = partition(l, r);
QuickSort(l, mid - 1);
QuickSort(mid + 1, r);
frame.render(data);
AlgorithmHelper.pause(DELAY);
}
private int partition(int l, int r) {
int v = data.get(l);
int i = l + 1;
int j = r;
setData(l, r, l);
while (true) {
while (i <= r && data.get(i) < v) {
i++;
}
while (j >= l + 1 && data.get(j) > v) {
j--;
}
if (i > j) {
break;
}
data.swap(i, j);
setData(l, r, l);
i++;
j--;
}
data.swap(j, l);
setData(l, r, j);
return j;
}

走迷宫
显示迷宫
迷宫生成等等再提,先看一下迷宫的读取和显示。
第一行是行数和列数,代表有101行101列,这个迷宫后面可以使用最小生成树生成。读进一个迷宫:
public class MazeData {
private char[][] maze;
private int N, M;
public static final char ROAD = '#';
public static final char WALL = ' ';
public MazeData(String fileName) {
if (fileName == null) {
throw new IllegalArgumentException("filename can't be null!");
}
Scanner scanner = null;
try {
File file = new File(fileName);
if (!file.exists()) {
throw new IllegalArgumentException("File is not exist!");
}
FileInputStream fileInputStream = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fileInputStream), "UTF-8");
String nm = scanner.nextLine();
String[] nmC = nm.trim().split("\\s+");
N = Integer.parseInt(nmC[0]);
M = Integer.parseInt(nmC[1]);
maze = new char[N][M];
for (int i = 0; i < N; i++) {
String line = scanner.nextLine();
if (line.length() != M) {
throw new IllegalArgumentException("Message of file is not completed!");
}
for (int j = 0; j < M; j++) {
maze[i][j] = line.charAt(j);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}
}
public char getMaze(int i, int j) {
if (!inArea(i, j)) {
throw new IllegalArgumentException("out of range!");
}
return maze[i][j];
}
public boolean inArea(int x, int y) {
return x >= 0 && x < N && y >= 0 && y < M;
}
public int N() {
return N;
}
public int M() {
return M;
}
}
使用File来获得当前文件,如果没有就要抛出异常。scanner获得输入流之后可以通过读取下一行获得每一行的内容,列数在前面已经提到了,所以要检查每一行是不是M列,不是就没得读了。#就是墙,空格是路,可以设置两个静态变量表示。同时还需要各种辅助函数,比如是否是在整区域里面的,返回当前区域的值等等。然后就是显示函数了:
int w = canvasWidth / data.M();
int h = canvasHeight / data.N();
for (int i = 0; i < data.N(); i++) {
for (int j = 0; j < data.M(); j++) {
if (data.getMaze(i, j) == MazeData.ROAD){
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.LightBlue);
}else {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.White);
}
AlgorithmHelper.fillRectangle(graphics2D, j * w, i * h, w, h);
}
}

迷宫问题
白色方块是可以走的路径,红色的就是墙。迷宫的本质就是一个图结构。可以把整个迷宫当成是一个图,而走迷宫的过程就可以等价成是图的遍历。从起始点开始遍历,直到遍历到了某一个终止点即可。如果遍历了所有点都没有得到结果,那么就可以确认无解了。
图的遍历可以分成两种遍历。深度优先遍历和广度优先遍历,一种遍历是按照深度,先往一个方向深了走,没有路了再回头,而广度是先广度走一遍再一层一层下去。首先固定了每一个迷宫的出口和入口位置,从一开始,就需要从相邻的四个方向走迷宫,如果可以就继续,不能就回头,其实就是递归实现。
深度优先
首先还是递归实现,递归比较方便,首先要准备递归函数,和上述的一样,走四个方向,一个一个尝试,如果下一个格子是在这个图里面,是一条路,而且还没有被访问过,那么久可以继续走,否则就需要返回。
private boolean go(int x, int y) {
if (!data.inArea(x, y)) {
throw new IllegalArgumentException("Paramenter is illgel!");
}
data.visited[x][y] = true;
setData(x, y, true);
if (x == data.getExitX() && y == data.getExitY()) {
return true;
} else {
for (int i = 0; i < 4; i++) {
int nexX = x + direction[i][0];
int nexY = y + direction[i][1];
if (data.inArea(nexX, nexY) &&
data.getMaze(nexX, nexY) == MazeData.ROAD &&
!data.visited[nexX][nexY]) {
if (go(nexX, nexY)) {
return true;
}
}
}
setData(x, y, false);
return false;
}
}
如果四个点都尝试过了,都是走不了的,那么还需要消除画的格子。相对来说还是比较简单的。再消除格子上这个步骤对于递归来说是相对方便,因为再回溯的过程中是有保留之前的点的信息的,所以相对简单。

这就是生成的结果了。
如果是非递归,用栈就可以模拟,因为递归本身就是用栈实现的。对于删除无用路径的情况,其实有点难,因为无用的路径是直接丢弃的,先前的递归可以是因为递归的栈保留了更加多的内容,而这里只是保留了点而已。
private boolean go_iteration() {
Stack stack = new Stack<>();
Position entrance = new Position(data.getEntanceX(), data.getEntanceY());
stack.push(entrance);
data.visited[entrance.getX()][entrance.getY()] = true;
while (!stack.isEmpty()) {
Position position = stack.pop();
setData(position.getX(), position.getY(), true);
for (int i = 0; i < 4; i++) {
int newX = position.getX() + direction[i][0];
int newY = position.getY() + direction[i][1];
if (newX == data.getExitX() && newY == data.getExitY()) {
setData(newX, newY, true);
return true;
}
Position newPosition = new Position(newX, newY, position);
if (data.inArea(newPosition.getX(), newPosition.getY()) &&
data.getMaze(newPosition.getX(), newPosition.getY()) == MazeData.ROAD
&& !data.visited[newPosition.getX()][newPosition.getY()]) {
stack.push(newPosition);
data.visited[newPosition.getX()][newPosition.getY()] = true;
}
}
}
return false;
}

广度优先
广度和深度在搜索策略上是不同的。深度是走到死路才回头,广度是对于每一次都是齐头并进。和遍历的深度优先的区别就是在于他们的数据结构不一样,一个是队列,一个是栈,其他的基本差不多。
private boolean go_level() {
Queue queue = new LinkedList<>();
Position position = new Position(data.getEntanceX(), data.getEntanceY());
queue.add(position);
data.visited[position.getX()][position.getY()] = true;
while (!queue.isEmpty()) {
Position position1 = queue.poll();
setData(position1.getX(), position1.getY(), true);
for (int i = 0; i < 4; i++) {
int newX = position1.getX() + direction[i][0];
int newY = position1.getY() + direction[i][1];
if (newX == data.getExitX() && newY == data.getExitY()) {
findPath(position1);
setData(newX, newY, true);
return true;
}
Position newPosition = new Position(newX, newY, position1);
if (data.inArea(newPosition.getX(), newPosition.getY()) &&
data.getMaze(newPosition.getX(), newPosition.getY()) == MazeData.ROAD
&& !data.visited[newPosition.getX()][newPosition.getY()]) {
queue.add(newPosition);
data.visited[newPosition.getX()][newPosition.getY()] = true;
}
}
}
return false;
}

如果迷宫有很多个解,深度优先遍历那么久只会搜索到第一个碰到的解,搜索到的解那么就是一个随缘排序出来,广度优先就是会查找最短的路径。广度优先可以找到无全图的最短路径。深度和广度的非递归差不多,只是使用的数据结构不同而已。
生成迷宫
刚刚是走迷宫,刚刚生成的那个用例其实就是生成的迷宫。对于一个迷宫,只有一个入口一个出口,为了简单化,入口就是第二行的第一个口,出口是倒数第二行的第一个口。而且只有一个解,并且路径是连续的,有些游戏里面的迷宫是有传送点的,改变起来也很简单。
首先迷宫其实就是一棵树,每一个点都会有分支,任何一个叶子或者是节点都可以作为是一个入口,生成一个迷宫其实就是一个生成树的过程。之前在数据结构有提到过一个最小生成树,但是由于是一个随机的迷宫,所以应该是随机生成树。无论是什么树,都是基于树的。而图的遍历结果就是一颗树,每一个节点只是访问一次,且没有环,深度优先遍历的结果是一颗深度优先树,广度优先的结果是广度优先树。可以先把一张画布分成很多很多小格子,然后每隔一个格子就挖空一个点,没有挖空点的都是墙,用一种遍历方法来遍历这些点所生成的树就是一个迷宫了。但是这样的迷宫其实带有偏见的,随机性不高,所以可以在选择点的进行遍历的时候进行随机选择。
@@@@@
@ _@ _ @
@@@@@
@ _ @ _@
@@@@@
可以看的出无论怎么看,行和列一定要是基数,限制还是蛮多的。深度优先生成迷宫其实和之前的差不多,没有上面打的差别。首先是要得到一个格子布。然后通过深度遍历把格子全部连接起来。递归实现:
private void run() {
setData(-1, -1);
go(data.getEntranceX(), data.getEntranceY() + 1);
setData(-1, -1);
}
private void go(int x, int y) {
if (!data.inArea(x, y)) {
throw new IllegalArgumentException("x or y is illegal!");
}
data.visited[x][y] = true;
for (int i = 0; i < 4; i++) {
int newX = x + direction[i][0] * 2;
int newY = y + direction[i][1] * 2;
if (data.inArea(newX, newY) &&
!data.visited[newX][newY]) {
setData(x + direction[i][0], y + direction[i][1]);
go(newX, newY);
}
}
}
这里要注意每两个格子之间的差距是2,因为中间都隔着一堵墙。go的参数是开始的参数,开始不能直接从入口开始,因为入口是我们新加的,不符合迷宫节点的规矩,比如每一个格子相差两个点,但是出口和第一个点差一个而已。
int newX = x + direction[i][0] * 2;
int newY = y + direction[i][1] * 2;
乘上2的原因就是因为两个格子之间相差了2。而渲染都放在了setData里面处理。渲染的点就不是我们newX和newY了,因为那两个点本来就是road,渲染的应该是两个点之间的墙,所以是加1的。和前面深度搜索对比区别就是,这里没有终止点,不是到了exit就退出,事实上是不一定有解的。因为我们这里是要全部生成而不是生成到了终点就停止,所以是无终止条件的。但是for循环里面是隐含了的。还有一个就是条件确认是不是一条路,这个决策是不必要的,因为就要生成路的。但是这样导致的迷宫很无随机性:
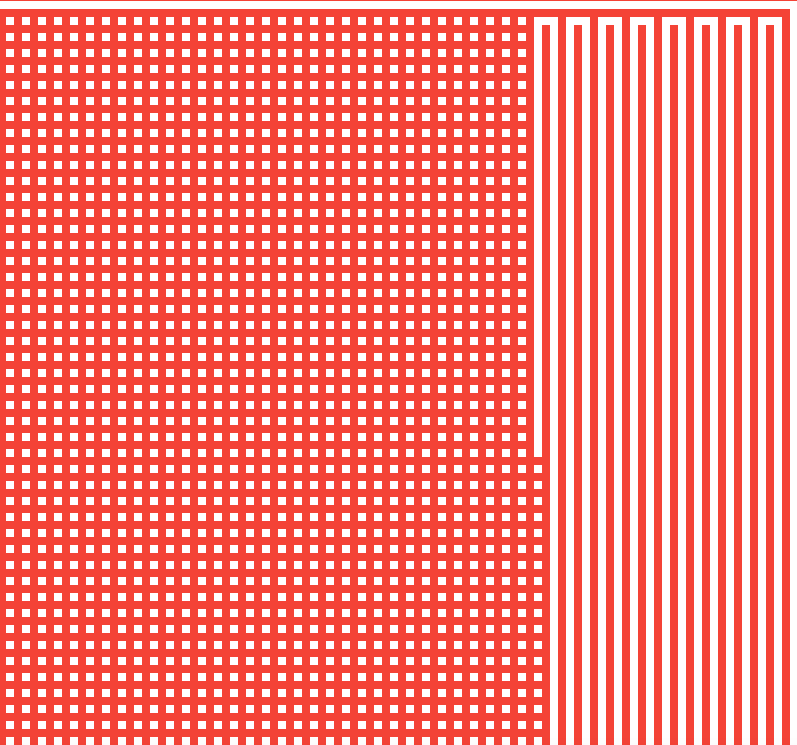
这是递归方法, 非递归方法:
private void go_iterator(){
Stack stack = new Stack<>();
Position firstPosition = new Position(data.getEntranceX(), data.getEntranceY() + 1);
stack.push(firstPosition);
data.visited[firstPosition.getX()][firstPosition.getY()] = true;
while (!stack.isEmpty()){
Position position = stack.pop();
for (int i = 0; i < 4; i++) {
int newX = position.getX() + direction[i][0] * 2;
int newY = position.getY() + direction[i][1] * 2;
if (data.inArea(newX, newY) &&
!data.visited[newX][newY]) {
setData(position.getX() + direction[i][0], position.getY() + direction[i][1]);
stack.push(new Position(newX, newY));
data.visited[newX][newY] = true;
}
}
}
}

广度遍历:之前提到过了和深度遍历差不多:
private void go_level(){
LinkedList stack = new LinkedList<>();
Position firstPosition = new Position(data.getEntranceX(), data.getEntranceY() + 1);
stack.addLast(firstPosition);
data.visited[firstPosition.getX()][firstPosition.getY()] = true;
while (stack.size() != 0){
Position position = stack.removeFirst();
for (int i = 0; i < 4; i++) {
int newX = position.getX() + direction[i][0] * 2;
int newY = position.getY() + direction[i][1] * 2;
if (data.inArea(newX, newY) &&
!data.visited[newX][newY]) {
setData(position.getX() + direction[i][0], position.getY() + direction[i][1]);
stack.addLast(new Position(newX, newY));
data.visited[newX][newY] = true;
}
}
}
}

生成的图像都很规则。 一个很重要的原因的因为我们在数据结构的选择过程中都是栈和队列,可预期性太强了。我们只需要在数据结构中加上随机性就好了。出队或者是删除都是随机队列。
public class RandomQueue {
private ArrayList queue;
public RandomQueue() {
queue = new ArrayList<>();
}
public void add(E e) {
queue.add(e);
}
public E remove() {
if (queue.size() == 0) {
throw new IllegalArgumentException("no elements!");
}
int randomIndex = (int) (Math.random() * queue.size());
E Ele = queue.get(randomIndex);
queue.set(randomIndex, queue.get(queue.size() - 1));
queue.remove(queue.size() - 1);
return Ele;
}
public boolean isEmpty(){
return queue.isEmpty();
}
}

这样就有一定的随机性了。可以看到在很多空白的小格子很容易让别人猜到我们是怎么生成的。所以可以加上如果没有遍历到的格子全部变黑色。
private void go_level(){
RandomQueue stack = new RandomQueue<>();
Position firstPosition = new Position(data.getEntranceX(), data.getEntranceY() + 1);
stack.add(firstPosition);
data.openMinst(firstPosition.getX(), firstPosition.getY());
data.visited[firstPosition.getX()][firstPosition.getY()] = true;
while (!stack.isEmpty()){
Position position = stack.remove();
for (int i = 0; i < 4; i++) {
int newX = position.getX() + direction[i][0] * 2;
int newY = position.getY() + direction[i][1] * 2;
if (data.inArea(newX, newY) &&
!data.visited[newX][newY]) {
data.openMinst(newX, newY);
setData(position.getX() + direction[i][0], position.getY() + direction[i][1]);
stack.add(new Position(newX, newY));
data.visited[newX][newY] = true;
}
}
}
}

但是其实还有一个问题,很多时候这个迷宫的路径顺序是都是斜向下的趋势,所以有时候是可以猜到怎么走的。可以通过改进随机队列:
public void add(E e) {
if (Math.random() < 0.5){
queue.addFirst(e);
}else {
queue.addLast(e);
}
}
public E remove() {
if (queue.size() == 0) {
throw new IllegalArgumentException("no elements!");
}
// int randomIndex = (int) (Math.random() * queue.size());
// E Ele = queue.get(randomIndex);
// queue.set(randomIndex, queue.get(queue.size() - 1));
// queue.remove(queue.size() - 1);
// return Ele;
if (Math.random() < 0.5){
return queue.removeFirst();
}else {
return queue.removeLast();
}
}
这个时候随机性就更强了:

扫雷
开始的时候,会展开一片区域,这片区域随机找一个点点开,如果没有雷,那么就会展开一片区域,雷的个数是固定的。有些展开的地方会有数字,那么就表面这个地方的周围八个格子里面有多少个雷。
格子和雷都使用图片表示。
public static void putImage(Graphics2D graphics2D, int x, int y, String imageURL) {
ImageIcon imageIcon = new ImageIcon(imageURL);
Image image = imageIcon.getImage();
graphics2D.drawImage(image, x, y, null);
}
在frame面版画上:
int w = canvasWidth / data.getM();
int h = canvasHeight / data.getN();
for (int i = 0; i < data.getN(); i++) {
for (int j = 0; j < data.getM(); j++) {
if (data.isMine(i, j)){
AlgorithmHelper.putImage(graphics2D, j * w, i * h, MineSweeperData.mineImageURL);
}else {
AlgorithmHelper.putImage(graphics2D, j * w, i * h, MineSweeperData.blockImageURL);
}
}
}
}

测试一下。
随机雷区
首先是如何在扫雷区域中随机分布若干个雷。我们要做的事情是要在雷区里面随机分配雷。做法很简单,就是x,y随机即可。
private void generateMines(int number) {
for (int i = 0; i < number; i++) {
while (true) {
int x = (int) (Math.random() * N);
int y = (int) (Math.random() * M);
if (!mines[x][y]) {
mines[x][y] = true;
break;
}
}
}
}

这样其实是比较可行的,但是因为有一个死循环,如果盘面小,而且雷多的话,生成时间可能会很慢,因为生成相同区域的雷区就会很密集。为了避免出现这种情况,可以先生成,再排序。
for (int i = 0; i < number; i++) {
int x = i / M;
int y = i % M;
mines[x][y] = true;
}
int swapTime = 100;
for (int j = 0; j < swapTime; j++) {
int x1 = (int) (Math.random() * N);
int y1 = (int) (Math.random() * M);
int x2 = (int) (Math.random() * N);
int y2 = (int) (Math.random() * M);
swap(x1, y1, x2, y2);
}

首先有一个问题,就是如何验证一个算法足够乱。可以使用蒙特卡洛方法来验证,使用大样本的结果来验证。
有一种等概论的方法,首先使用随机算法从54张牌抽一张放在第一个位置,然后继续余下步骤。如果要维护每一个元素的抽取的可能性是等价的,就需要保留已经抽取元素的位置,这样如果剩下的元素少了,那么抽取到的可能性就会很低。
Fisher-Yates算法
首先把所以的元素都放在一个空间里,然后随机一个元素,把随机出来的这个元素和第一个元素交换位置,那么第一个元素就完成了;接着在剩下的位置继续选择,然后和第二个位置继续交换,以此类推。
int swapTime = N * M;
for (int j = swapTime - 1; j >= 0; j--) {
int x1 = j / M;
int y1 = j % M;
int rangeNumber = (int) (Math.random() * (j + 1));
int x2 = rangeNumber / M;
int y2 = rangeNumber % M;
swap(x1, y1, x2, y2);
}
在这里需要把一维坐标转换成二维坐标,其他的就和上述一样。这个时候得到的结果随机性不减,而且没有死循环,时间上快了不少。
交互
加入鼠标交互,只需要在控制层添加鼠标左右键判断即可。
private class AlgoMouseListener extends MouseAdapter {
@Override
public void mouseClicked(MouseEvent event) {
event.translatePoint(-(int) (frame.getBounds().width - frame.getCanvasWidth()), -(int) (frame.getBounds().height - frame.getCanvasHeight()));
Point point = event.getPoint();
int w = frame.getCanvasWidth() / data.getM();
int h = frame.getCanvasHeight() / data.getN();
int x = point.y / h;
int y = point.x / w;
if (SwingUtilities.isLeftMouseButton(event)) {
System.out.println(x + " " + y);
setData(true, x, y);
} else if (SwingUtilities.isRightMouseButton(event)) {
setData(false, x, y);
}
}
}
private void setData(boolean isLeft, int x, int y) {
if (data.inArea(x, y)) {
if (isLeft) {
data.open[x][y] = true;
} else {
data.flags[x][y] = !data.flags[x][y];
}
}
frame.render(data);
AlgorithmHelper.pause(DELAY);
}
现在点击只是会展开一个点,但实际上一个展开一片区域的。但是这个区域是不规则的,它的边界是数字区域,也就是说如果当前的区域是数字,那么就停止了,如果不是,那么就会向外扩展。
FloodFill算法
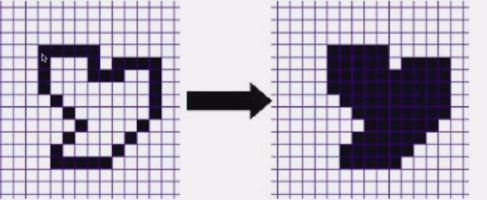
比如现在有一个图形,从某一点开始扩张直到边界为止。这个填充方法其实就很像深度遍历或者广度遍历这样。
public void open(int x, int y) {
if (inArea(x, y) && !isMine(x, y)) {
open[x][y] = true;
if (numbers[x][y] > 0) {
return;
} else {
for (int i = x - 1; i <= x + 1; i++) {
for (int j = y - 1; j <= y + 1 ; j++) {
if (inArea(i, j) && !open[i][j] && !mines[i][j]){
open(i, j);
}
}
}
}
}
}
对上下左右斜方向的八个格子进行遍历搜索。

基本的扫雷核心操作就全部完成了。
分形图的绘制
首先,分形图指在这个图案上右自相似的部分。

每一个分支和树本身是很相似的,可以看的出其实就是一个递归结构。
Vicsek Fractal
正方形的九宫格分形。每一次切分只对中间和四个角落的正方形做绘制,这样递归绘制下去。模板还是使用之前的swing绘画。
public class FractalData {
private int depth;
public FractalData(int depth){
this.depth = depth;
}
public int getDepth(){
return depth;
}
}
所有的绘画逻辑都在frame绘画里面。
public void drawFractal(Graphics2D graphics2D, int x, int y, int w, int h, int depth) {
if (depth == data.getDepth()) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Indigo);
AlgorithmHelper.fillRectangle(graphics2D, x, y, w, h);
return;
}
if (w <= 1 || h <= 1) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Indigo);
AlgorithmHelper.fillRectangle(graphics2D, x, y, Math.max(w, 1), Math.max(h, 1));
return;
}
int w_3 = w / 3;
int h_3 = h / 3;
drawFractal(graphics2D, x, y, w_3, h_3, depth + 1);
drawFractal(graphics2D, x + 2 * w_3, y, w_3, h_3, depth + 1);
drawFractal(graphics2D, x + w_3, y + h_3, w_3, h_3, depth + 1);
drawFractal(graphics2D, x, y + 2 * h_3, w_3, h_3, depth + 1);
drawFractal(graphics2D, x + 2 * w_3, y + 2 * h_3, w_3, h_3, depth + 1);
}
这段代码加入到frame的paintComponent即可。可以看到递归绘画里面只有边界条件才画,也就是说只有当分到了不可再分的时候才会画,所以无论是多少层都是画一些小点点。

这样看不出主要的效果,我们需要的是固定窗口大小,然后正方形的大小与窗口所一致。
所以需要改变一下,传入的参数就是最大的深度,通过键盘来调整深度即可。其实画的正方形有多大是有那几个边界条件觉定的:
if (depth == data.getDepth()) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Indigo);
AlgorithmHelper.fillRectangle(graphics2D, x, y, w, h);
return;
}
if (w <= 1 || h <= 1) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Indigo);
AlgorithmHelper.fillRectangle(graphics2D, x, y, Math.max(w, 1), Math.max(h, 1));
return;
}
所以只需要改变深度即可。
private class AlgoKeyListener extends KeyAdapter {
@Override
public void keyReleased(KeyEvent keyEvent) {
if (keyEvent.getKeyChar() >= '0' &&
keyEvent.getKeyChar() <= '9') {
int depth = keyEvent.getKeyChar() - '0';
setData(depth);
}
}
}

可以根据想要的形状调整frame的画图函数即可:

Sierpinski carpet
这种分形和前面的性质有所不同,第一层是有一个大的正方形,第二层就会出现小正方形包围着大正方形,下一层就会出现更小的正方形。

其他的都不用变,只需要改一下frame的paint函数即可。
int w_3 = w / 3;
int h_3 = h / 3;
if (depth == data.getDepth()) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Amber);
AlgorithmHelper.fillRectangle(graphics2D, x + w / 3, y + h / 3, w / 3, h / 3);
return;
}
if (w <= 1 || h <= 1) {
return;
}
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
if (i == 1 && j == 1) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Amber);
AlgorithmHelper.fillRectangle(graphics2D, x + w / 3, y + h / 3, w / 3, h / 3);
} else {
drawFractal(graphics2D, x + i * w_3, y + j * h_3, w_3, h_3, depth + 1);
}
}
}
特殊情况,到了递归层数之后就不需要画小正方形了,只需要画中间的大正方形即可,如果长和宽太小画不下去,那么不需要画,因为就算是画中间的大正方形也看不见,因为是要整数。接下来的两层循环,1,1的情况就是大正方形中间的情况,直接画,其他的就递归画周边小的即可。

把正方形换成其他形状也是可以的。
Siepinski Triangle
把一个大三角形分成四个,中间的一个三角形不做绘制。

其实和之前是一样的,只是绘画方式不一样:
public void drawFractal_Triangle(Graphics2D graphics2D, int Ax, int Ay, int size, int depth) {
if (size <= 1) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Lime);
AlgorithmHelper.fillRectangle(graphics2D, Ax, Ay, 1, 1);
return;
}
int Bx = Ax + size;
int By = Ay;
int h = (int) (Math.sin(60.0 * Math.PI / 180.0) * size);
int Cx = Ax + size / 2;
int Cy = Ay - h;
if (depth == data.getDepth()) {
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Cyan);
AlgorithmHelper.fillTriangle(graphics2D, Ax, Ay, Bx, By, Cx, Cy);
return;
}
int AB_centerX = (Ax + Bx) / 2;
int AB_centerY = (Ay + By) / 2;
int AC_centerX = (Ax + Cx) / 2;
int AC_centerY = (Ay + Cy) / 2;
int BC_centerX = (Bx + Cx) / 2;
int BC_centerY = (By + Cy) / 2;
drawFractal_Triangle(graphics2D, Ax, Ay, size / 2, depth + 1);
drawFractal_Triangle(graphics2D, AC_centerX, AC_centerY, size / 2, depth + 1);
drawFractal_Triangle(graphics2D, AB_centerX, AB_centerY, size / 2, depth + 1);
}
首先是求出高,用高来求得这三个点的左边,A点是三角形的左下角的坐标,然后逆时针依次是ABC。

Koch Snowflake
绘出雪花形状的分形图。

public void drawSnow(Graphics2D graphics2D, double x1, double y1, double side, double angle, int depth) {
if (side <= 0) {
return;
}
if (depth == data.getDepth()) {
double x2 = x1 + side * Math.cos(angle * Math.PI / 180.0);
double y2 = y1 - side * Math.sin(angle * Math.PI / 180.0);
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.DeepOrange);
AlgorithmHelper.drawLine(graphics2D, x1, y1, x2, y2);
return;
}
double side_3 = side / 3;
double x2 = x1 + side_3 * Math.cos(angle * Math.PI / 180.0);
double y2 = y1 - side_3 * Math.sin(angle * Math.PI / 180.0);
drawSnow(graphics2D, x1, y1, side_3, angle, depth + 1);
double x3 = x2 + side_3 * Math.cos((angle + 60.0) * Math.PI / 180.0);
double y3 = y2 - side_3 * Math.sin((angle + 60.0) * Math.PI / 180.0);
drawSnow(graphics2D, x2, y2, side_3, angle + 60, depth + 1);
double x4 = x3 + side_3 * Math.cos((angle - 60.0) * Math.PI / 180.0);
double y4 = y3 - side_3 * Math.sin((angle - 60.0) * Math.PI / 180.0);
drawSnow(graphics2D, x3, y3, side_3, angle - 60, depth + 1);
drawSnow(graphics2D, x4, y4, side_3, angle, depth + 1);
return;
}
分别求出起始点即可,不需要求终点,因为side就是长度,可以求得终点。
最后的效果:
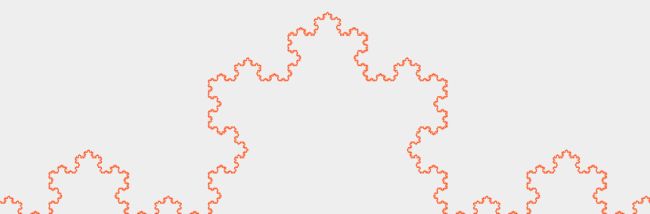
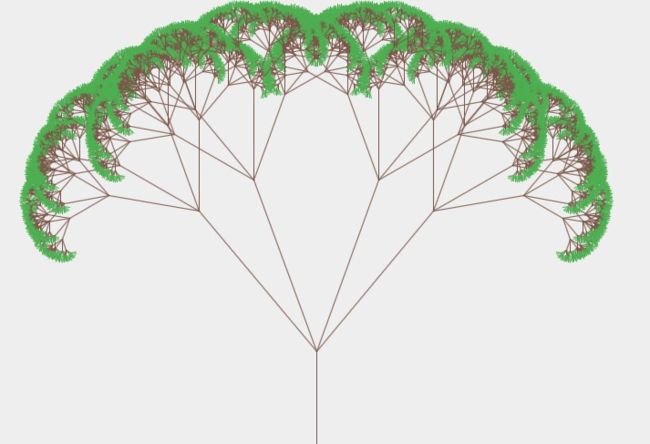
draw a tree
画出的树肯定是有一定规律的树了,首先是从一条竖直的直线展开,然后一层一层按照某种角度展开,最后形成一条直线。整体上,第一层就是绘制一条直线;来到第一层的时候就会分叉,下半部分不变,上半部分再次分叉。
再分叉的过程中,两边对称的话,左边就是a度,右边就是-a度。
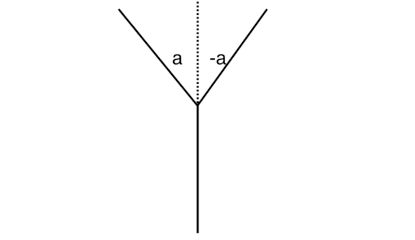
可以看的出,这棵树是由两部分组成的,树干和树,所以绘画肯定不能再递归终止条件里面的了。
double side_2 = side / 2;
if (side_2 <= 0) {
return;
}
if (depth == data.getDepth()) {
double x2 = x1 - side * Math.cos(angle * Math.PI / 180.0);
double y2 = y1 - side * Math.sin(angle * Math.PI / 180.0);
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Green);
AlgorithmHelper.drawLine(graphics2D, x1, y1, x2, y2);
return;
}
递归终止条件,就是画叶子的了,按照一定的角度展开,angle是上面传过来的参数。之后就是正式递归:
double x2 = x1 - side / 2 * Math.cos(angle * Math.PI / 180.0);
double y2 = y1 - side / 2 * Math.sin(angle * Math.PI / 180.0);
AlgorithmHelper.setColor(graphics2D, AlgorithmHelper.Brown);
AlgorithmHelper.drawLine(graphics2D, x1, y1, x2, y2);
画树干,和上面的其实是一样的,但是颜色不同而已。
drawTree(graphics2D, x2, y2, side / 2, angle + data.splitAngle / 2, depth + 1);
drawTree(graphics2D, x2, y2, side / 2, angle - data.splitAngle / 2, depth + 1);
之后就是画分支的递归了,分支递归的角度是有一定变化的,左边变化多少,右边多少可以自己指定,然后层数加一。上面的公式在和上图给出的角度不太一样,是因为上图的是垂直角度,而在计算的时候是水平角度。可以依照这个原理画一些其他的树。