1.小明设置了这个场景,从30开始,每分钟+10个VUSER,压测出了如下tps曲线,大家觉得是否有问题,理由是什么?
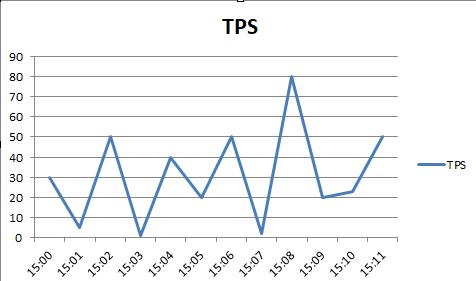
有问题,性能曲线一般是稳定的 坡度不大的抛物线,如下图 TPS要符合紫色的曲线
上图的锯齿可能是因为 中间件的线程少 导致tps小
2.小明在性能测试过程中,监控到CPU的使用率达到80%,他觉的可以认定为有性能瓶颈,判断依据是网上说CPU的使用率不能超过80%,这种做法是否合理,理由是什么?
考察点:性能测试过程中关于定性和定量的博弈
如果像OA系统 CPU 达到 80% 需要看内存 IO 是否同样处于高位,如果同样处于高位说明当前资源有被正常使用,20%完全足够用来对一些冗余的应对
电商集中爆发性质、上下班高峰打卡之类的、有明显波峰波谷的使用场景的CPU使用率一般在50%左右 这样有足够冗余来应对
如果CPU使用率最高90%,内存使用率50%,可以认为CPU存在瓶颈吗
当所有资源都瓶颈 但是某个资源特别高 是存在瓶颈的
3.小明在编写性能测试脚本的过程中,每个事务都增加了对应的检查点。但是他的同事小关说不需要做检查点,因为这样会增加响应时间。你觉的是小明的做法正确还是小关的想法是正确的?理由是什么?
检查点 需要在核心位置做就可以 不用太多 也不会增加响应时间 会影响负载机的资源
因为很多的检查点都是后置,就是成交返回来之后我们才去做检查点的验证。
所以这个时候跟服务器已经没有太直接的关系了。所以消耗的是我们的业务资源,消耗的是我们负载机的资源。
4.小王在一次性能测试过程中,编写了测试脚本,也针对脚本做了参数化和检查点,于是他认为这样的脚本就是符合要求的脚本。但是架构师看完之后说还不够。不能满足实际的脚本需求。那你们觉的符合要求的性能测试脚本应该包含哪些因素?
性能测试脚本的要求并不只是跑通脚本
脚本的有效性从以下4点来保证:
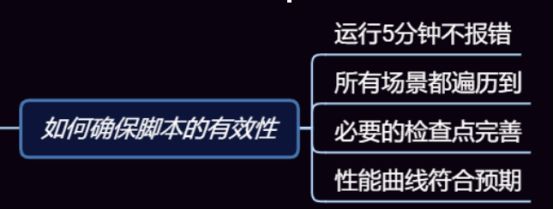
脚本正确性 参数化 唯一数据 关联等
5.有一天,性能测试小组的成员小王发现小明在学习基础的性能监控命令(比如TOP\vmstat),他和小明说:现在没有必要学习这些东西了,有好多现成的监控工具,都做的很完善了。针对小王和小明的说法,你觉的哪个有道理,理由是什么呢?
都有道理
学工具(使用 封装好的快速集成一些监控内容)/工具的实现原理/改造和使用
6.小明了解到某个性能场景的业务为:有100用户登录论坛,90个用户查看帖子,10个用户发贴。他在Jmeter中的设置如下图,请问是否可行,是否合理?
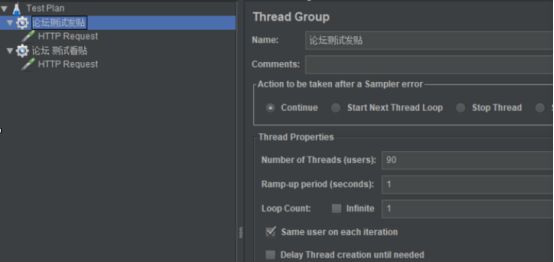
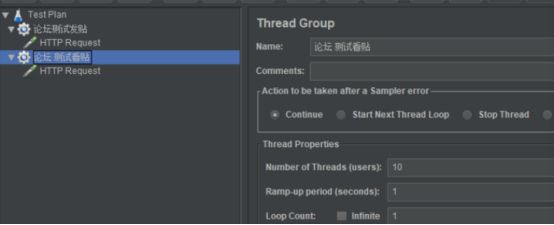
场景如何规划问题
通过 线程 来模拟当前访问,事务的响应时间不一致的话 会导致业务比例失效
线程当中可以增加计数器来 控制业务比例