我们都知道神经网络训练是由许多超参数决定的,例如网络深度,学习率,卷积核大小等等。
而我们有四种主要的策略可用于搜索最佳配置。
- 照看(babysitting,又叫试错)
- 网格搜索
- 随机搜索
- 贝叶斯优化
照看法
照看法被称为试错法或在学术领域称为研究生下降法。这种方法 100% 手动,是研究员、学生和业余爱好者最广泛采用的方法。
该端到端的工作流程非常简单:学生设计一个新实验,遵循学习过程的所有步骤(从数据收集到特征图可视化),然后她按顺序迭代超参数,直到她耗尽时间(通常是到截止日期)或动机。

网格搜索
取自命令式指令「Just try everything!」的网格搜索——一种简单尝试每种可能配置的朴素方法。
工作流如下:
- 定义一个 n 维的网格,其中每格都有一个超参数映射。例如 n = (learning_rate, dropout_rate, batch_size)
- 对于每个维度,定义可能的取值范围:例如 batch_size=[4,8,16,32,64,128,256 ]
- 搜索所有可能的配置并等待结果去建立最佳配置:例如 C1 = (0.1, 0.3, 4) -> acc = 92%, C2 = (0.1, 0.35, 4) -> acc = 92.3% 等...
随机搜索
网格搜索和随机搜索之间唯一真正的区别在于策略周期的第 1 步 - 随机搜索从配置空间中随机选取点。
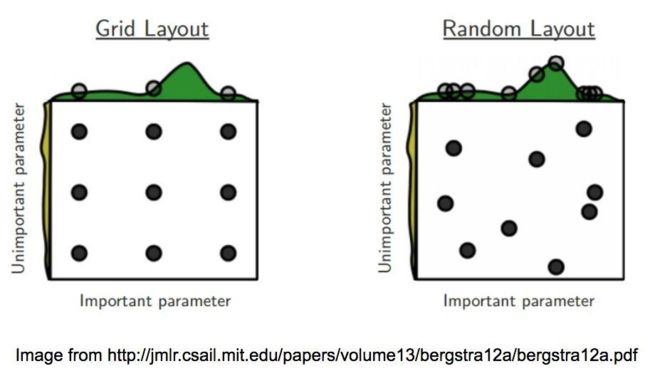
- 网格搜索 vs 随机搜索
图像通过在两个超参数空间上搜索最佳配置来比较两种方法。它还假设一个参数比另一个参数更重要。这是一个安全的假设,因为开头提到的深度学习模型确实充满了超参数,并且研究员/科学家/学生一般都知道哪些超参数对训练影响最大。
从每个图像布局顶部的曲线图可以看出,我们使用随机搜索可以更广泛地探索超参数空间(特别是对于更重要的变量)。这将有助于我们在更少的迭代中找到最佳配置。
总结:如果搜索空间包含 3 到 4 个以上的维度,请不要使用网格搜索。相反,使用随机搜索,它为每个搜索任务提供了非常好的基准。
- 通常使用 2 的幂作为批大小的值,并在对数尺度上对学习率进行采样。
贝叶斯优化(输入调参x,输出效果y,根据后验概率推算最优y对应的x)
贝叶斯优化在不知道目标函数(黑箱函数)长什么样子的情况下,通过猜测黑箱函数长什么样,来求一个可接受的最大值。和网格搜索相比,优点是迭代次数少(节省时间),粒度可以到很小,缺点是不容易找到全局最优解。
此搜索策略构建一个代理模型,该模型试图从超参数配置中预测我们关注的指标。
在每次新的迭代中,代理人将越来越自信哪些新的猜测可以带来改进。就像其他搜索策略一样,它也有相同的终止条件。
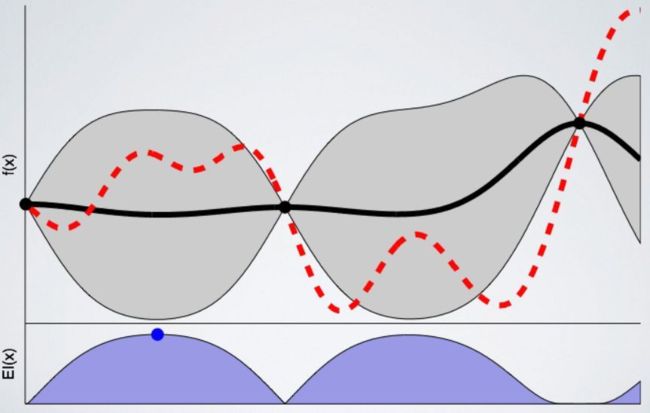
我们训练的模型越多,代理人对下一个有希望采样的点就越有信心。以下是模型经过 8 次训练后的图表:

贝叶斯优化的目的是找到当x等于某个值的时候y得到最大. 我们随机选取的10个点x=1..10里很可能没有包含那个值(对y=x*x来说就是0),那么我们需要找下一个点x, 获得其对应的采样点y. 这“下一个x”,是基于我们对前面10个点的多变量高斯分布的假设以及最大化AF而得到的,现目前为止我们认为的y的最大值最可能出现的位置
- 例:
比如现在我们找到x=0.8为“下一个x”, 那么现在我们就有11个采样点,x=0.8,1,2...10 和他们对应的y值。这时候这11个点服从多变量高斯分布,我们再次最大化AF(每一次最大化AF,都需要多变量高斯分布的信息),得到"下一个x",如x=0.5,经过一定数量的迭代,我们可能可以得到y最大点在x=0.1之类。
采集函数 (Acquisition Function,AC)
常见的采集函数有下面三种,UCB,PI,EI,先介绍最好理解的UCB。
- UCB (Upper confidence bound)
,k为调节参数,直观地理解为上置信边界。
- PI (probability of improvement)
超参数用于调节exploitation与exploitation,更倾向于收敛到附近,表示正态累计分布函数, 表示现有的最大值。
其原理就是找到未知点的函数值比大的概率,取这些点中概率最大的点,具体比大多少不考虑,这里通过Z-scores标准化法,让每个未知点函数值大于的概率可以进行比较。
Z-scores标准化法,,x为观察点,为所有观察点的均值,为所有观察点标准差,的概率密度函数符合标准正态分布。
- EI (Expected improvement)
为正态累计分布函数,为正态概率密度函数,表示现有的最大值。EI函数解决了PI未考虑未知点,比已知最大点大多少的问题,EI函数求的是未知点函数值比大的期望
- 输入:
target:黑箱函数
x:自变量取值范围
Y:可以接受的黑箱函数因变量取值
- 输出:
x:贝叶斯优化器猜测的最大值的x值
target(xnew):贝叶斯优化器猜测的最大值的函数值
def BayesianOptimization(target,x,Y):
IF 初始化?
Yes:
xold为已知的所有点中目标函数取得最大值的自变量值
IF target(xold)>Y?
Yes: return xold,target(xold) #撞了大运,还没开始迭代就结束了
No: Pass
No: 随机初始化
While target(xnew)但是,跟所有工具一样,它们也有缺点:
- 根据定义,该过程是有顺序的
- 它只能处理数值参数
- 即使训练表现不佳,它也不提供任何停止训练的机制
提前终止:优化训练时间
提前终止不仅是一项著名的正则化技术,而且在训练错误时,它还是一种能够防止资源浪费的机制。
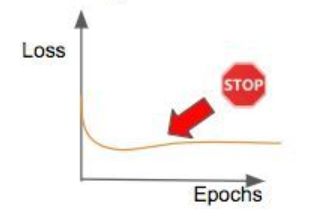
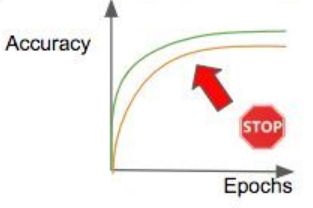
- 下面是最常用的终止训练标准的图表:
- 训练时间久了过拟合了,反而损失更高了

- 训练效果稳定了,训练再多也是浪费
- 表现比基准差
- 训练数个小时就结束

前三个标准显而易见,所以我们把注意力集中在最后一个标准上。
通常情况下,研究人员会根据实验类别来限定训练时间。这样可以优化团队内部的资源。通过这种方式,我们能够将更多资源分配给最有希望的实验。
Keras 提供了一个很好的提前终止功能,甚至还有一套回调组件。由于 Keras 最近已经整合到 Tensorflow 中,你也可以使用 Tensorflow 代码中的回调组件。
Tensorflow 提供了训练钩子,这些钩子可能不像 Keras 回调那样直观,但是它们能让你对执行状态有更多的控制。
Pytorch 还没有提供钩子或回调组件,但是你可以在论坛上查看 TorchSample 仓库。我不太清楚 Pytorch 1.0 的功能列表(该团队可能会在 PyTorch 开发者大会上发布一些内容),这个功能可能会随新版本一起发布。