在上一篇文章中, 我着重介绍了 Swift中指针的使用, 这篇文章主要围绕以下几点:
- HandyJSON 的优势.
- HandyJSON 解析数据的原理.
- Mirror 的原理.
HandyJSON 的优势
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式, 应用广泛. 在 App 的使用过程中, 服务端给移动端发送的大部分都是 JSON 数据, 移动端需要解析数据才能做进一步的处理. 在解析JSON数据这一块, 目前 Swift 中流行的框架基本上是 SwiftyJSON, ObjectMapper, JSONNeverDie, HandyJSON 这么几种.
我们应该如何选择呢?
首先我们应该先明白解析 JSON 的原理. 目前有两个方向.
保持 JSON 语义, 直接解析 JSON.
SwiftyJSON 就是这样的. 本质上仍然需要根据 JSON 结构去取值.预定义 Model 类, 将 JSON 反序列化类的实例, 再使用这些实例.
这种方式和 OC 中的 MJExtension 的思路是一致的. 在 Swift 中,ObjectMapper,JSONNeverDie, 以及HandyJSON做的都是将 JSON 文本反序列化到 Model 类上.
第二种思路是我们熟悉和比较方便的. 和服务端定义好数据结构, 写好 Model 就可以直接解析.
第二种思路有三种实现方式:
- 完全沿用 OC 中的方式, 让 Model 类继承自
NSObject, 通过class_copyPropertyList方法拿到 Model 的各种属性, 从 JSON 中拿到对应的 value, 再通过 OC 中 利用runtime机制 实现的KVC方法为属性赋值. 如JSONNeverDie. - 支持纯
Swift类, 但要求开发者实现mapping函数, 使用重载的运算符进行赋值, 如ObjectMapper. - 获取到 JSON 数据后, 直接在内存中为实例的属性赋值.
HandyJSON就是这样实现的.
- 第一种方式的缺点在于需要强制继承
NSObject, 这不适用于struct定义的 Model. 因为struct创建的 Model 不能通过 KVC 为其赋值. - 第二种方式的缺点在于自定义
mapping函数, 维护比较困难. - 第三种方式在使用上和
MJExtension基本差不多, 比较方便. 是我们所推荐的.
HandyJSON 解析数据的原理.
如何在内存上为实例的属性赋值呢?
在上一篇文章里, 我们介绍了 struct 实例 和 class 实例在内存上结构的不同. 为属性赋值, 我们需要以下步骤:
- 获取到属性的名称和类型.
- 找到实例在内存中的 headPointer, 通过属性的类型计算内存中的偏移值, 确定属性在内存中的位置.
- 在内存中为属性赋值.
在 Swift 中实现反射机制的类是 Mirror, 通过 Mirror 类可以获取到类的属性, 但是不能为属性赋值, 它是可读的. 但是我们可以直接在内存中为实例赋值. 这是一种思路. 另外一种思路是不利用 Mirror, 直接在内存中获取到属性的名称和类型, 这也是可以的. 目前 HandyJSON 就是利用的第二种方式.
Mirror 的原理
虽然 HandyJSON 的核心实现上并没有依赖于 Mirror, Mirror 的性能不好. 但是这个类还是挺有意思的. 如果没使用过 Mirror, 看看这篇文章.
class LCPerson {
var name: String?
}
Mirror(reflecting: LCPerson()).children.forEach { (child) in
print(child.label ?? "", child.value)
child.value = "lili" // error,不能直接赋值
}
下面的内容极大的借鉴了一个牛人写的 how-mirror-works, 所以也算是我的学习笔记.
要从源码角度剖析 Mirror, 我们需要拿到 Swift 的源码, 可以从 Apple 的 官方 github clone 源代码到本地. 我们需要真正关注的是 stdlib 和 include 这两个文件夹, 前者是 Swift 的标准库的源码, 后者是支持文件.

反射的 API 有一部分是用 Swift 实现的, 另一部分是 C++ 实现的. 分别在 ReflectionMirror.swift 和 ReflectionMirror.mm. 这两者通过一小组暴露给 Swift 的 C++ 函数进行通信.
比如在 ReflectionMirror.swift 中的.
@_silgen_name("swift_reflectionMirror_subscript")
internal func _getChild(
of: T,
type: Any.Type,
index: Int,
outName: UnsafeMutablePointer?>,
outFreeFunc: UnsafeMutablePointer
) -> Any
与其在 ReflectionMirror.mm 中的实现是下面
SWIFT_CC(swift) SWIFT_RUNTIME_STDLIB_INTERFACE
AnyReturn swift_reflectionMirror_subscript(OpaqueValue *value, const Metadata *type,
intptr_t index,
const char **outName,
void (**outFreeFunc)(const char *),
const Metadata *T) {
return call(value, T, type, [&](ReflectionMirrorImpl *impl) {
return impl->subscript(index, outName, outFreeFunc);
});
}
注意:
-
ReflectionMirror.swift中的_getChild()函数用于获取对应索引值的子元素信息. -
@_silgen_name修饰符会通知 Swift 编译器将这个函数映射成swift_reflectionMirror_subscript符号,而不是 Swift 通常对应到的_getChild方法名修饰. 也就是说, 在 Swift 中直接调用_getChild函数, 实际上就是调用 C++ 实现的swift_reflectionMirror_subscript函数. -
SWIFT_CC(swift)会告诉编译器这个函数使用的是 Swift 的调用约定,而不是 C/C++ 的.SWIFT_RUNTIME_STDLIB_INTERFACE标记这是个函数. - C++ 的参数会去特意匹配在 Swift 中声明的函数调用. 当 Swift 调用
_getChild时, C++ 会用包含的 Swift 值指针的value, 包含类型参数的type, 包含目标索引值的index, 包含标签信息的outname, 包含释放目标字符串内存的方法outFreeFunc, 包含类型相应的范型的 T的函数参数来调用此函数.
Mirror 的在 Swift 和 C++ 之间的全部接口由以下函数组成:
获取标准化类型
@_silgen_name("swift_reflectionMirror_normalizedType")
internal func _getNormalizedType(_: T, type: Any.Type) -> Any.Type
获取子元素数量
@_silgen_name("swift_reflectionMirror_count")
internal func _getChildCount(_: T, type: Any.Type) -> Int
获取子元素信息
@_silgen_name("swift_reflectionMirror_subscript")
internal func _getChild(
of: T,
type: Any.Type,
index: Int,
outName: UnsafeMutablePointer?>,
outFreeFunc: UnsafeMutablePointer
) -> Any
// Returns 'c' (class), 'e' (enum), 's' (struct), 't' (tuple), or '\0' (none)
获取对象的展示类型
@_silgen_name("swift_reflectionMirror_displayStyle")
internal func _getDisplayStyle(_: T) -> CChar
@_silgen_name("swift_reflectionMirror_quickLookObject")
internal func _getQuickLookObject(_: T) -> AnyObject?
判断一个类是不是另一个类的子类, 类似于 NSObject 中的 isKindOfClass
@_silgen_name("_swift_stdlib_NSObject_isKindOfClass")
internal func _isImpl(_ object: AnyObject, kindOf: AnyObject) -> Bool
动态派发
元组、结构、类和枚举都需要不同的代码去完成这些繁多的任务,比如说查找子元素的数量, 比如针对 OC, Swift 做不同的处理. 所有的函数因为需要不同的类型的检查而需要派发不同的实现代码.
为了解决这个问题, Swift采用了一种类似动态派发的方式, 利用一个单独的函数将 Swift 类型映射成一个 C++ 类的实例. 在一个实例上调用方法然后派发合适的实现.
映射的函数是 call().
template
auto call(OpaqueValue *passedValue, const Metadata *T, const Metadata *passedType,
const F &f) -> decltype(f(nullptr)) { ... }
参数:
-
passedValue是实际需要传入的Swift的值的指针. -
T是该值的静态类型. 对应 Swift 中的范型参数. -
passedType是被显式传递进 Swift 侧并且会实际应用在反射过程中的类型(这个类型和在使用 Mirror 作为父类的实例在实际运行时的对象类型不一样). -
f参数会传递这个函数查找到的会被调用的实现的对象引用.
返回值:
这个函数会返回当这个 f 参数调用时的返回值.
call 的内部实现 主要有两部分:
针对 Swift
auto call = [&](ReflectionMirrorImpl *impl) { ... }
针对 OC
auto callClass = [&] { ... }
以及通过 Switch 处理各种不同类型的实现.
callClass 内部也会调用 call, 因为 call 内部用一个 ReflectionMirrorImpl 的子类实例去结束调用 f,然后会调用这个实例上的方法去让真正的工作完成.
auto call = [&](ReflectionMirrorImpl *impl) {
impl->type = type;
impl->value = value;
auto result = f(impl);
SWIFT_CC_PLUSONE_GUARD(T->vw_destroy(passedValue));
return result;
};
重点关注下 ReflectionMirrorImpl 的实现.
// Abstract base class for reflection implementations.
struct ReflectionMirrorImpl {
const Metadata *type; 类型信息
OpaqueValue *value; 值指针
virtual char displayStyle() = 0; 显示方式
virtual intptr_t count() = 0; 子元素数量
子元素信息
virtual AnyReturn subscript(intptr_t index, const char **outName,
void (**outFreeFunc)(const char *)) = 0;
virtual const char *enumCaseName() { return nullptr; }
#if SWIFT_OBJC_INTEROP
virtual id quickLookObject() { return nil; }
#endif
virtual ~ReflectionMirrorImpl() {}
};
关键: 作用在 Swift 和 C++ 组件之间的接口函数就会用 call 去调用相应的方法.
比如前面提到的: swift_reflectionMirror_subscript, 获取子元素信息. 内部就会调用
call(value, T, type, [&](ReflectionMirrorImpl *impl) {
return impl->subscript(index, outName, outFreeFunc);
});
大概有以下 5 种:

Tuple, Struct, Enum 等类型都有对应的 ReflectionMirrorImpl 的实现.
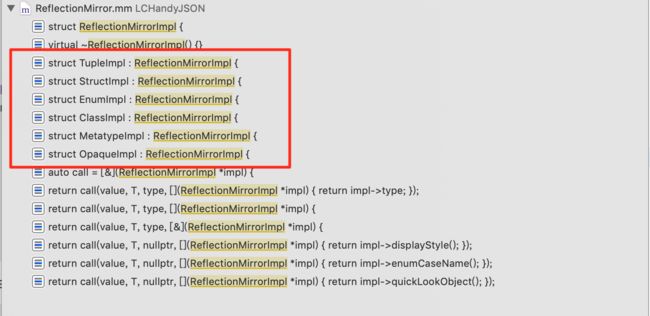
下面会依次介绍元组的反射, 结构体的反射, 类的反射, 枚举的反射, 其他种类.
元组的反射
元组的反射的实现
总体概览:
struct TupleImpl : ReflectionMirrorImpl {
// 显示方式, 元组是 't'
char displayStyle() { ... }
// 子元素的数量
intptr_t count() { ... }
// 子元素信息
AnyReturn subscript(intptr_t i, const char **outName,
void (**outFreeFunc)(const char *)) { ... }
}
接下来从上往下看:
char displayStyle() {
return 't';
}
返回 't' 的显示样式来表明这是一个元组.
intptr_t count() {
auto *Tuple = static_cast(type);
return Tuple->NumElements;
}
count() 方法返回子元素的数量. type 由原来的 MetaType 类型的指针转为 TupleTypeMetadata 类型的指针. TupleTypeMetadata 类型有一个记录元组的元素数量的字段 NumElements, 由此取值.
注意: TupleTypeMetadata 类型实际是 TargetTupleTypeMetadata 类型, 这是一个 struct, 内部包含字段 NumElements.
using TupleTypeMetadata = TargetTupleTypeMetadata;
subscript() 方法比较复杂.
auto *Tuple = static_cast(type);
- 获取
type的TupleTypeMetadata类型的指针.
if (i < 0 || (size_t)i > Tuple->NumElements)
swift::crash("Swift mirror subscript bounds check failure");
- 防止调用者请求了不存在的元组的索引.
i 的作用在于 可以检索元素和对应的名字.
- 对于元组而言, 这个名字是该元素在元组中的label, 若没有label, 默认就是一个 .0 的数值指示器.
- 对于结构体或者类来说, 这个名字是属性名.
bool hasLabel = false;
if (const char *labels = Tuple->Labels) {
const char *space = strchr(labels, ' ');
for (intptr_t j = 0; j != i && space; ++j) {
labels = space + 1;
space = strchr(labels, ' ');
}
// If we have a label, create it.
if (labels && space && labels != space) {
*outName = strndup(labels, space - labels);
hasLabel = true;
}
}
- 查找元组中第 i 个位置的
label.label是以空格为间隔存储在Tuple中的labels字段里.
strchr(s, 'c') 可以查找字符串 s 中首次出现字符 c 的位置.
返回首次出现 'c' 的位置的指针, 返回的地址是被查找字符串指针开始的第一个与 'c' 相同字符的指针.
strndup(labels, space - labels)
将字符串拷贝到新建的位置处, 若不需要返回的字符串, 需要手动调用 free 将其释放.
if (!hasLabel) {
// The name is the stringized element number '.0'.
char *str;
asprintf(&str, ".%" PRIdPTR, i);
*outName = str;
}
- 如果没有
label, 则创建一个以.i为名字的字符串为label. 类似下面这样
let tuple = ("jack", "lily", "lucy")
print(tuple.0) // jack
*outFreeFunc = [](const char *str) { free(const_cast(str)); };
-
outFreeFunc用于调用者手动调用此函数来释放返回的label. 对应前面的strndup.
strdup() 在内部调用了 malloc() 为变量分配内存, 不需要使用返回的字符串时, 需要用 free() 释放相应的内存空间, 否则会造成内存泄漏.
// Get the nth element.
auto &elt = Tuple->getElement(i);
auto *bytes = reinterpret_cast(value);
auto *eltData = reinterpret_cast(bytes + elt.Offset);
- 利用
getElement(i)获取Tuple元数据的相关信息,elt是一个Element类型的结构体实例.
struct Element {
/// The type of the element.
ConstTargetMetadataPointer Type;
/// The offset of the tuple element within the tuple.
StoredSize Offset;
OpaqueValue *findIn(OpaqueValue *tuple) const {
return (OpaqueValue*) (((char*) tuple) + Offset);
}
};
elt 包含了一个 offset 字段, 表示该元素在元组中的偏移值, 可以应用在元组值上, 去获得元素的值指针.
Any result;
result.Type = elt.Type;
auto *opaqueValueAddr = result.Type->allocateBoxForExistentialIn(&result.Buffer);
result.Type->vw_initializeWithCopy(opaqueValueAddr,
const_cast(eltData));
-
elt还包含了元素的类型, 通过类型和值的指针,去构造一个包括这个值新的Any对象.
return AnyReturn(result);
- 通过
AnyReturn包装, 返回子元素信息.AnyReturn是一个struct. 它可以保证即使在任何将在寄存器中返回 Any 的体系结构中也是如此.
struct AnyReturn {
Any any;
AnyReturn(Any a) : any(a) { }
operator Any() { return any; }
~AnyReturn() { }
};
这里的 Any 指的是
/// The layout of Any.
using Any = OpaqueExistentialContainer;
在介绍结构体, 类, 枚举的反射时, 先来看看一个函数 swift_getFieldAt, 这个函数可以通过用语言的元数据去查找类型信息. HandyJSON 里面直接用到了.
swift_getFieldAt
swift_getFieldAt() 可以通过结构、类和枚举的元数据去查找类型信息
函数原型:
void swift::swift_getFieldAt(
const Metadata *base, unsigned index,
std::function
callback) { ... }
接下来从上往下看.
auto *baseDesc = base->getTypeContextDescriptor();
if (!baseDesc)
return;
通过元数据获取类型的上下文描述
auto getFieldAt = [&](const FieldDescriptor &descriptor) { ... }
定义一个方法 getFieldAt , 从描述符中查找信息.
接下来的工作分为两步.
- 查找描述符.
- 调用
getFieldAt方法, 通过描述符查找信息.
auto dem = getDemanglerForRuntimeTypeResolution();
获取符号还原器, 将符号修饰过的类名还原为实际的类型引用.
auto &cache = FieldCache.get();
获取字段描述符的缓存.
auto isRequestedDescriptor = [&](const FieldDescriptor &descriptor) {
assert(descriptor.hasMangledTypeName());
auto mangledName = descriptor.getMangledTypeName(0);
if (!_contextDescriptorMatchesMangling(baseDesc,
dem.demangleType(mangledName)))
return false;
cache.FieldCache.getOrInsert(base, &descriptor);
getFieldAt(descriptor);
return true;
};
定义一个方法, 检查输入的描述符是否是被需要的哪一个, 如果是, 那么将描述符放到缓存中, 并且调用 getFieldAt, 然后返回成功给调用者.
if (auto Value = cache.FieldCache.find(base)) {
getFieldAt(*Value->getDescription());
return;
}
如果存在字段描述符缓存, 那么通过 getFieldAt 获取字段信息.
ScopedLock guard(cache.SectionsLock);
// Otherwise let's try to find it in one of the sections.
for (auto §ion : cache.DynamicSections) {
for (const auto *descriptor : section) {
if (isRequestedDescriptor(*descriptor))
return;
}
}
for (const auto §ion : cache.StaticSections) {
for (auto &descriptor : section) {
if (isRequestedDescriptor(descriptor))
return;
}
}
字段描述符可以在运行时注册, 也可以在编译时加入到二进制文件中. 这两个循环查找所有已知的字段描述符以进行匹配.
接下来看看 getFieldAt 内部的实现过程.
getFieldAt 这个方法作用是将字段描述符转化为名字和字段类型, 进行回调返回.
auto &field = descriptor.getFields()[index];
- 获取字段的引用.
auto name = field.getFieldName(0);
- 在引用中获取字段的名字.
if (!field.hasMangledTypeName()) {
callback(name, FieldType().withIndirect(field.isIndirectCase()));
return;
}
- 判断是否有类型. 比如, 字段实际上是一个枚举, 那么它可能没有类型.
std::vector descriptorPath;
{
const auto *parent = reinterpret_cast<
const ContextDescriptor *>(baseDesc);
while (parent) {
if (parent->isGeneric())
descriptorPath.push_back(parent);
parent = parent->Parent.get();
}
}
- 定义一个
ContextDescriptor类型的指针descriptorPath, 通过baseSesc获取描述符的路径. 也就是将这个类型的所有范型的上下文抽离出来.
auto typeInfo = _getTypeByMangledName(
field.getMangledTypeName(0),
[&](unsigned depth, unsigned index) -> const Metadata * { ... }
- 获取类型信息
前面有提到, 字段的引用 field 将字段类型储存为一个符号修饰的名字, 但是最终回调的是元数据的指针. 所以需要将符号修饰的名字转化为一个真实的类型. (字符串 -> 类型)
_getTypeByMangledName 方法的作用在此.
在 _getTypeByMangledName 内部,
field.getMangledTypeName(0)
首先传入由符号修饰的类型.
if (depth >= descriptorPath.size())
return nullptr;
接着检查请求的深度与描述符的路径, 如果前者比后者大, 返回失败
unsigned currentDepth = 0;
unsigned flatIndex = index;
const ContextDescriptor *currentContext = descriptorPath.back();
for (const auto *context : llvm::reverse(descriptorPath)) {
if (currentDepth >= depth)
break;
flatIndex += context->getNumGenericParams();
currentContext = context;
++currentDepth;
}
接着, 从字段的类型中获取范型参数. 将索引和深度转化为单独的扁平化的索引, 通过遍历描述符的路径, 在每个阶段添加范型参数的数量直到达到深度为止.
if (index >= currentContext->getNumGenericParams())
return nullptr;
如果索引比范型参数可达到的深度大,那么失败.
return base->getGenericArgs()[flatIndex];
在 _getTypeByMangledName 的最后, 从元数据 base 获得基本类型信息, 再在其中获得合适的范型参数.
callback(name, FieldType()
.withType(typeInfo)
.withIndirect(field.isIndirectCase())
.withWeak(typeInfo.isWeak()));
getFieldAt 方法中最重要的一步, 执行回调, 将字段名字和类型暴露出来.
结构体的反射
结构体的反射的实现和元组类似, 但是结构体可能包含需要反射代码去提取的弱引用. 下面是实现代码.
struct StructImpl : ReflectionMirrorImpl {
显示方式, 结构体是 's'
char displayStyle() { ... }
子元素数量
intptr_t count() { ... }
所有子元素信息
AnyReturn subscript(intptr_t i, const char **outName,
void (**outFreeFunc)(const char *)) { ... }
}
char displayStyle() {
return 's';
}
结构体的显示样式是 's'
intptr_t count() {
auto *Struct = static_cast(type);
return Struct->getDescription()->NumFields;
}
count 方法返回子元素的数量. type 由原来的 MetaType 类型的指针转为 StructMetadata 类型的指针.
StructMetadata 类型有一个 TargetStructDescriptor 类型的字段 getDescription(), 这是一个指针, TargetStructDescriptor 类中有一个字段 NumFields, 由此可获得子元素数量.
注意: StructMetadata 类型实际是 TargetStructMetadata 类型, 这是一个 struct
using StructMetadata = TargetStructMetadata;
AnyReturn subscript(intptr_t i, const char **outName,
void (**outFreeFunc)(const char *)) { ... }
subscript 方法比较复杂
auto *Struct = static_cast(type);
- 获取
type的StructMetadata类型的指针.
if (i < 0 || (size_t)i > Struct->getDescription()->NumFields)
swift::crash("Swift mirror subscript bounds check failure");
- 进行边界检查, 防止访问不存在的子元素.
auto fieldOffset = Struct->getFieldOffsets()[i];
- 查找对应索引的字段偏移值.
Any result;
swift_getFieldAt(type, i, [&](llvm::StringRef name, FieldType fieldInfo) {
assert(!fieldInfo.isIndirect() && "indirect struct fields not implemented");
获取字段名字
*outName = name.data();
*outFreeFunc = nullptr;
计算字段储存的指针
auto *bytes = reinterpret_cast(value);
auto *fieldData = reinterpret_cast(bytes + fieldOffset);
loadSpecialReferenceStorage 方法用于处理将字段的值复制到 Any 返回值以处理弱引用
bool didLoad = loadSpecialReferenceStorage(fieldData, fieldInfo, &result);
如果值没有被载入的话那么那个值用普通的储存,并且以普通的方式拷贝到返回值
if (!didLoad) {
result.Type = fieldInfo.getType();
auto *opaqueValueAddr = result.Type->allocateBoxForExistentialIn(&result.Buffer);
result.Type->vw_initializeWithCopy(opaqueValueAddr,
const_cast(fieldData));
}
});
- 通过
_swift_getFieldAt方法, 获取结构体字段中的信息(字段的名字和类型).
AnyReturn(result);
最后, 将子元素信息返回.
类的反射
struct ClassImpl : ReflectionMirrorImpl {
显示样式, 类是 'c'
char displayStyle() { ... }
子元素数量
intptr_t count() { ... }
子元素信息
AnyReturn subscript(intptr_t i, const char **outName,
void (**outFreeFunc)(const char *)) { ... }
#if SWIFT_OBJC_INTEROP
id quickLookObject() { ... }
#endif
}
StructImpl 与 ClassImpl 的实现主要有两个不同:
第一, ClassImpl 实现了 quickLookObject 这个字段, 如果父类是 OC 中的类的话, 在使用 quickLookObject 时会调起 OC 的 debugQuickLookObject 方法.
#if SWIFT_OBJC_INTEROP
id quickLookObject() {
id object = [*reinterpret_cast(value) retain];
if ([object respondsToSelector:@selector(debugQuickLookObject)]) {
id quickLookObject = [object debugQuickLookObject];
[quickLookObject retain];
[object release];
return quickLookObject;
}
return object;
}
#endif
第二, 如果该类的父类是 OC 的类,字段的偏移值需要在 OC 运行时获得.
uintptr_t fieldOffset;
if (usesNativeSwiftReferenceCounting(Clas)) {
fieldOffset = Clas->getFieldOffsets()[i];
} else {
#if SWIFT_OBJC_INTEROP
Ivar *ivars = class_copyIvarList((Class)Clas, nullptr);
fieldOffset = ivar_getOffset(ivars[i]);
free(ivars);
#else
swift::crash("Object appears to be Objective-C, but no runtime.");
#endif
参考
how-mirror-works
[HandyJSON] 设计思路简析