MPT(Merkle Patricia Trie)
MPT这种数据结构实际上是一种Trie树变种,是以太坊中一种非常重要的数据结构,用来存储用户账户的状态及其变更(状态树)、交易信息(交易树)、交易的收据信息(收据树)。MPT实际上是两种数据结构的组合,分别是Merkle树 和 Patricia 树。由于Merkle树前一篇文档已有较详细的描述,本节将简单介绍Patricia 树的前身Trie树和它本身,接下来引出本文重点Merkle Patricia Trie, 分析一下MPT之于在以太坊区块的作用,以及相关实现细节。
Trie树
Trie一词来自retrieve(检索),发音为/tri:/,也有人读为/traɪ/。Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树,推导一下,索引键值中的每一个字符都来自一个容量为N且包含的字符都互不相同的字母表,这个树就为N叉树,而树的深度就是key的最大长度。
它的核心idea是:
position in the tree defines the key with which it is associated
键不是直接保存在节点中,而是由节点在树中的位置决定
比如,我们需要检索key对应为“ted”的value,从Root节点开始(一般对应root节点索引设为空),key中的每一个字符“t”“e”“d”代表着要找到所需value要经过的子节点:

在代码实现上,Node一般采用定长数组表示:
[i0, i1 ... in, value]
前n个值要么为空(Null),要么为一个指向其他节点索引(指针),最后一个值为以当前节点为终点的key对应的value,如上图中“in”对应的value为5.
了解完Trie树的原理之后,可以分析一下它的主要优势与缺陷。
- 优:相比于哈希表,使用前缀树来进行查询拥有共同前缀key的数据时十分高效。
对于哈希表来说,需要遍历整个表,时间效率为O(n);然而对于前缀树来说,只需要遍历以对应共同前缀的节点为根节点的子节点即可:若对应上图中“tea”“ted”“ten”,我们只需要遍历共同前缀“te”对应的节点的所有子节点即可
优:相比于哈希表,在前缀树不会存在哈希冲突的问题:也就是说一个key永远只对应一个value。
优:代码实现上,对于root节点,中间节点,叶子节点只需要一种节点结构
[i0, i1 ... in, value]劣:直接查找效率低下
前缀树的查找效率是O(m),m为所查找节点的key长度,而哈希表的查找效率为O(1)。且一次查找会有m次IO开销,相比于直接查找,无论是速率、还是对磁盘的压力都比较大。
- 劣:存储不平衡可能会造成空间浪费
If you want to store just one (path,value) binding where the path is (in the case of the ethereum state trie), 64 characters long (number of nibbles in bytes32), you will need over a kilobyte of extra space to store one level per character, and each lookup or delete will take the full 64 steps.
当存在一个key值内容很长的节点,当树中没有与他相同前缀的分支时,为了存储该节点,需要创建许多非叶子节点来构建根节点到该节点间的路径,导致整棵树不平衡,相比于哈希表,额外产生了过多的“无用”中间节点造成了存储空间的浪费。
Patricia树(TODO:图是不是可以统一一下)
针对于Trie树存储不平衡的缺陷,PatriciaTrie,又被称为 RadixTree 或紧凑前缀树 (compact prefix tree),提出了一种优化 Trie空间使用率的idea:如果存在一个父节点只有一个子节点,那么这个父节点将与其子节点合并。这样可以缩短 Trie 中不必要的深度,大大加快搜索节点速度。

Merkle Patricia Trie
MPT(Merkle Patricia Trie)则是在Patricia树的基础上,添加了加密安全功能:引用为下一个节点的hash值,Merkle 树的特性带来的;其次引入了很多节点类型来提高效率:Null Node(空节点),Extension Node(拓展节点),Leaf Node(叶子节点),Branch Node(分支节点)。
空节点(Null): 表示的空,在代码中就是一个空串
叶子节点(Leaf): 叶子节点包含两个字段, 第一个字段是剩下的Key的半字节编码,而且半字节编码方法的第二个参数为true, 第二个字段是Value
扩展节点(Extention): 扩展节点也包含两个字段,第一个字段是剩下的Key的可以至少被两个剩下节点共享的部分的半字节编码,第二个字段是下一个node的hash值,设计体现了 PatriciaTrie 的特点,通过合并只有一个子节点的父节点和其子节点来缩短 trie 的深度。
分支节点(Branch): 分支节点包含了17个字段,其前16个项目对应key中的16个可能的十六进制字符,如果有一个键值对在这个分支点终止,则最后的一个字段用于存放该键值对的值。即分支点既可以是搜索路径上的终止,也可以是路径的中间节点。
MPT还有一个重要概念:对key值进行编码的特殊十六进制前缀编码(HP,MPT实现细节里会有介绍),即上文提到的半字节编码。
以太坊区块结构 ———MPT实际应用场景

图来自于《以太坊技术详解与实战》以太坊结构
几个关键字段的含义如下:
- ParentHash:父块的哈希值
- Number:块编号
- Timestamp:块产生的时间戳
- GasUsed:交易消耗的Gas
- GasLimit:Gas限制
- Difficulty:POW的难度值
- Beneficiary:块打包手续费的受益人,也称矿工
- Nonce:一个随机数,使得块头哈希满足PoW需求
- StateRoot:状态树的根哈希值
- TransactionsRoot:交易树的根哈希值
- ReceiptsRoot:收据树的根哈希值
每个矿工在把交易打包成块的时候,会组织三棵树Merkle Patricia Trie:
-
交易树。leaf是交易信息:包括from,to(若为空则意味着这是一个创建智能合约的交易),Value,data(若不为空,这意味着这是一个创建或者调用智能合约的交易),Gas Limit,GasPrice,nonce,hash(由以上数据生成的hash值),VRS(由发送方对前hash进行签名生成);
key(实际上为path)是rlp(transactionIndex)。一旦建立,不再更新。
There is a separate transactions trie for every block. A path here is: rlp(transactionIndex). transactionIndex is its index within the block it's mined. The ordering is mostly decided by a miner so this data is unknown until mined. After a block is mined, the transaction trie never updates.
-
收据树,leaf是交易生成的不更新的收据:包括medstate,Gas_used,logbloom,logs(执行智能合约过程中生成的打印信息); key(实际上为path)是rlp(transactionIndex)。
一旦建立,不再更新。
Every block has its own Receipts trie. A path here is: rlp(transactionIndex). transactionIndex is its index within the block it's mined. Never updates.
-
状态树,leaf是交易影响到的账户状态的rlp值,账户状态ethereumAccount包括nonce,balance,storageRoot,codeHash; key(实际上为path)sha3(ethereumAddress)。状态树与以上两种树的区别在于:多个块的树共享了账户状态,子块状态树和父块状态树的差别在于它指向了在子区块中被改变了的账户。这样节省了总的存储空间,方便了块的回滚操作。
频繁更新:- 账户余额和账户的随机数nonce经常会更变
- 新的账户会频繁地插入,存储的键( key)也会经常被插入以及删除。
There is one global state trie, and it updates over time. In it, a path is always: sha3(ethereumAddress) and a value is always: rlp(ethereumAccount). More specifically an ethereum account is a 4 item array of [nonce,balance,storageRoot,codeHash]. At this point it's worth noting that this storageRoot is the root of another patricia trie:

这里有一段V神说的关于“状态”的作用:
One particular limitation(of Bitcoin) is that, while they can prove the inclusion of transactions, they cannot prove anything about the current state (eg. digital asset holdings, name registrations, the status of financial contracts, etc).
以太坊可以实现验证当前块状态包括:数字资产拥有权,名字注册,金融合约状态等,而比特币不可以。
三棵树求取根哈希,可以得到 区块头中的StateRoot,TransactionsRoot,ReceiptsRoot三个字段。这样就建立了交易和区块头字段的映射。当其他用户收到块,根据块里的交易可以计算出收据和状态,计算三个根哈希后和区块头的三个字段进行验证,判断这是否为合法的块。
其实区块体中还有一棵树:存储树。其结构也是MPT,其root树根的值存在于状态树的相应的leaf节点的storageRoot字段,用于存储智能合约数据。
MPT的实现细节
Node
node 接口族担当整个 MPT 中的各种节点,node 接口分四种实现: fullNode,shortNode,valueNode,hashNode。
[图片上传失败...(image-d211c3-1545380768641)]
图取自《以太坊技术详解与实战》 以太坊状态树
node.go
type node interface {
fstring(string) string
cache() (hashNode, bool)
canUnload(cachegen, cachelimit uint16) bool
}
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)
值得注意:黄皮书中把节点类型概括为了分支节点、扩展节点和叶子节点。fullNode对应了黄皮书里面的分支节点,shortNode对应了黄皮书里面的扩展节点和叶子节点(通过shortNode.Val的类型来对应到底是叶子节点还是拓展节点,如果是valueNode,就是叶子节点,否则是拓展节点)
-
fullNode 用于表示Branch Node
A 17-item node [ v0 ... v15, vt ]
是一个可以携带多个子节点的节点。
它有一个容量为 17 的 node 数组成员变量 Children。数组中前 16 个空位分别对应 16 进制 (hex) 下的 0-9a-f,这样对于每个子节点,根据其 key 值 16 进制形式下的第一位的值,就可挂载到 Children 数组的某个位置,fullNode 本身不再需要额外 key 变量;
Children 数组的第 17 位,留给该 fullNode 的数据部分。fullNode 明显继承了原生 trie 的特点,而每个父节点最多拥有 16 个分支也包含了基于总体效率的考量。 -
shortNode 用于表示Leaf Node 或者 Extension Node。
A 2-item node[Key,value]
Key 是一个byte数组,根据其的第一位nibble(半字节)是大于等于2时,意味着该点shortNode.Val为valueNode,这样的shortNode在代码里代表叶子节点,否则Extension Node
valueNode,也是字符数组 []byte ,承载了MPT结构中真正数据部分的节点。
-
hashNode, 跟 valueNode 一样,也是字符数组 []byte ,同样存放 32byte 的哈希值,也没有子节点。不同的是,hashNode 是 fullNode 或者 shortNode 对象的 RLP 哈希值,所以它跟 valueNode 在使用上有着莫大的不同。
在 MPT 中,hashNode 几乎不会单独存在 (有时遍历遇到一个 hashNode 往往因为原本的 node 被存储于DB,需要被解析出来),hashNode 体现了 MerkleTree 的特点:每个父节点的哈希值来源于所有子节点哈希值的组合,一个顶点的哈希值能够代表一整个树形结构。
节点Key值·编码
-
RAW 原始编码,对输入不做任何变更
叶子节点key字段剩余的路径=>"bob",RAW编码结果:['b' 'o' 'b']
-
HEX 十六进制编码,相当于把Trie的字母表锁定为 0 - f
- RAW编码输入的每个字符分解为高4位和低4位
- 如果是叶子节点,则在最后加上Hex值0x10表示结束
-
如果是分支节点不附加任何Hex值

func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16
nibbles[i*2+1] = b % 16
}
nibbles[l-1] = 16
return nibbles
}
*比如叶子节点key字段剩余的路径=>"bob",b的ASCII十六进制编码为0x62,o的ASCII十六进制编码为0x6f,分解成高四位和第四位,16表示终结 0x10,最终编码结果为[6 2 6 15 6 2 16],*
-
HEX-Prefix 十六进制前缀编码
- 输入key如果是以0x10结尾,则去掉这个终止符
-
key之前补一个四元组这个Byte第0位区分奇偶信息,第1位区分节点类型
 image
image - 如果剩余key的长度是偶数,则再添加一个四元组0x0在flag四元组后。值得注意!是剩余的key的长度,很多中文文档在此处描述或者含糊或者直接是错误的。
The flagging of both odd vs. even remaining partial path length and leaf vs. extension node as described above reside in the first nibble of the partial path of any 2-item node.
-
将原来的key内容压缩,将分离的两个byte以高四位低四位进行合并

encoding.go
func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16
nibbles[i*2+1] = b % 16
}
nibbles[l-1] = 16
return nibbles
}
PoC 单元测试如下:

比如叶子节点key字段剩余的路径=>"bob",hex编码结果为[6 2 6 15 6 2 16],hp编码结果[20,62,75,63]
这里提个问题:为什么需要HP编码呢?
参考答案:
all data is stored in bytes format, it is not possible to differentiate between, for instance, the nibble 1, and the nibbles 01 (both must be stored as <01>). To specify odd length, the partial path is prefixed with a flag.
所有信息按字节存储,所以对于半字节的信息,需要一种没有二义性的方式存:比如,1和01按字节存储结果都是<01>,HP就能解决
节点·序列化编码:RLP 编码
以太坊中要求数字必须是一个大端字节序的、没有零占位的存储的格式(也就是说,一个整数0和一个空数组是等同的)。RLP的目标就是在没有零占位的存储的格式情况下解决结构体的编码问题.
将MPT里各种节点都编码后信息不带歧义的存入levelDB中:通过记录结构体各层次长度,并且结合字节数要求进行编码。
黄皮书里这样描述RLP:

图中 · 表示concat连接
看不懂?没关系,待看完后面再回头看这个理解会清晰很多:D
RLP 编码函数接受一个item(也就是以上公式中s(x))。item定义如下:
- 将一个字符串作为一个item(比如,一个 byte 数组)
- 一组item列表(list)作为一个item
例如,一个空字符串可以是一个item,一个字符串"cat"也可以是一个item,一个含有多个字符串的列表也行,复杂的数据结构也行,比如这样的["cat",["puppy","cow"],"horse",[[]],"pig",[""],"sheep"]。注意!!说"字符串"的意思其实就相当于"一个确定长度的二进制字节信息数据";而不要假设或考虑关于字符的编码问题。
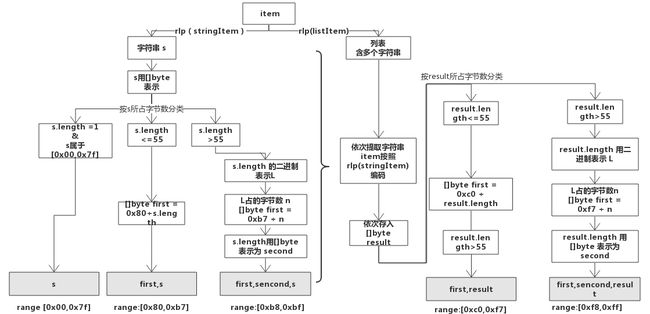
字符串:
-
对于 [0x00, 0x7f] 范围内的单个字节, RLP 编码内容就是字节内容本身。
数字15 ('\x0f') = [ 0x0f ]
空字符串 ('null') = [ 0x80 ]
-
否则,如果是一个 0-55 字节长的字符串,则RLP编码有一个特别的数值 0x80 加上字符串长度,再加上字符串二进制内容。这样,第一个字节的表达范围为 [0x80, 0xb7].
字符串 "dog" = [ 0x83, 'd', 'o', 'g' ]
数字 128('\x80') = [0x81, 0x80]
数字 1024 ('\x04\x00') = [ 0x82, 0x04, 0x00 ] -
如果字符串长度超过 55 个字节,RLP 编码由定值 0xb7 加上字符串长度所占用的字节数,加上字符串长度的编码,加上字符串二进制内容组成。比如,一个长度为 1024 的字符串,将被编码为\xb9\x04\x00 后面再加上字符串内容。第一字节的表达范围是[0xb8, 0xbf]。
字符串 "Lorem ipsum dolor sit amet, consectetur adipisicing elit" = [ 0xb8, 0x38, 'L', 'o', 'r', 'e', 'm', ' ', ... , 'e', 'l', 'i', 't' ]
列表:
-
如果列表的内容(它的所有项的组合长度)是0-55个字节长,它的RLP编码由0xc0加上所有的项的RLP编码串联起来的长度得到的单个字节,后跟所有的项的RLP编码的串联组成。 第一字节的范围因此是[0xc0, 0xf7]
列表 [ "cat", "dog" ] = [ 0xc8, 0x83, 'c', 'a', 't', 0x83, 'd', 'o', 'g' ]
空列表 = [ 0xc0 ]
-
如果列表的内容超过55字节,它的RLP编码由0xC0加上所有的项的RLP编码串联起来的长度的长度得到的单个字节,后跟所有的项的RLP编码串联起来的长度的长度,再后跟所有的项的RLP编码的串联组成。 第一字节的范围因此是[0xf8, 0xff] 。
The set theoretical representation of two, [ [], [[]], [ [], [[]] ] ] = [ 0xc7, 0xc0, 0xc1, 0xc0, 0xc3, 0xc0, 0xc1, 0xc0 ]
以下是手绘的rlp流程,如果感兴趣或者觉得以上流程解释仍然不大理解,可以参考蓝底示例如下图:
Python代码表达以上逻辑:
def rlp_encode(input):
if isinstance(input,str):
if len(input) == 1 and chr(input) < 128: return input
else: return encode_length(len(input),128) + input
elif isinstance(input,list):
output = ''
for item in input: output += rlp_encode(item)
return encode_length(len(output),192) + output
def encode_length(L,offset):
if L < 56:
return chr(L + offset)
elif L < 256**8:
BL = to_binary(L)
return chr(len(BL) + offset + 55) + BL
else:
raise Exception("input too long")
def to_binary(x):
return '' if x == 0 else to_binary(int(x / 256)) + chr(x % 256)
Example MPT(逻辑梳理)
我们要保存四个键值对:
('do', 'verb'), ('dog', 'puppy'), ('doge', 'coin'), ('horse', 'stallion')
首先将键值对的key进行hex编码:
<64 6f> : 'verb'
<64 6f 67> : 'puppy'
<64 6f 67 65> : 'coin'
<68 6f 72 73 65> : 'stallion'
构建MPT(包含HP编码):

序列化:为每个节点生成一个hash,它就是为了确保后续能正常将变动的数据提交DB储存(包含hash与rlp):hash值为索引,value为[]bytes
rootHash: [ <16>, hashA ]
hashA: [ <>, <>, <>, <>, hashB, <>, <>, <>, hashC, <>, <>, <>, <>, <>, <>, <>, <> ]
hashC: [ <20 6f 72 73 65>, 'stallion' ]
hashB: [ <00 6f>, hashD ]
hashD: [ <>, <>, <>, <>, <>, <>, hashE, <>, <>, <>, <>, <>, <>, <>, <>, <>, 'verb' ]
hashE: [ <17>, hashF ]
hashF: [ <>, <>, <>, <>, <>, <>, hashG, <>, <>, <>, <>, <>, <>, <>, <>, <>, 'puppy' ]
hashG: [ <35>, 'coin' ]
(此处这样写是为了让读者理解其结构,在本文后文中commit部分“store”及PoC代码可以详细了解trie在db中存储方式)
黄皮书中求解hash值时用以下公式:
[图片上传失败...(image-752f43-1545380768641)]
[图片上传失败...(image-cedf78-1545380768641)]
H(rlp.encode(x)) = sha3(rlp.encode(x)) if len(rlp.encode(x)) >= 32 else rlp.encode(x),值得注意的是当MPT新出现一个len(rlp.encode(x))>32的节点时,为了反序列化,数据库需要额外存储键值对(sha3(rlp.encode(x)), rlp.encode(x)),因为hash函数的单向性,若只知道sha3(x)无法推导出x。
具体可以参考下文Commit部分中hash过程及PoC代码。
以太坊中对MPT的操作(源码分析)
1. 如何根据某一个hash值在DB中找到整棵MPT?(Trie的反序列化过程)
trie的结构:
// Trie is a Merkle Patricia Trie.
// The zero value is an empty trie with no database.
// Use New to create a trie that sits on top of a database.
//
// Trie is not safe for concurrent use.
type Trie struct {
root node
db Database
originalRoot common.Hash
// Cache generation values.
// cachegen increases by one with each commit operation.
// new nodes are tagged with the current generation and unloaded
// when their generation is older than than cachegen-cachelimit.
cachegen, cachelimit uint16
}
包含了当前的root节点, db是levelDB(键值对都是二进制的高效数据库,以太坊使用它主要考虑到它的写优化的特点),trie的结构最终都是需要通过键值对的形式(key为hash值,value为[]bytes)存储到数据库里面去,然后启动的时候是需要从数据库里面加载的。 originalRoot 启动加载的时候的hash值,通过这个hash值可以在数据库里面恢复出整颗的trie树。
cachegen和cachelimit是Trie的缓存管理,为了不每次都从数据库加载数据,做了一层缓存,Trie每commit一次cachegen加1。
当节点被修改的时候,会打一个标记:
func (t *Trie) newFlag() nodeFlag {
return nodeFlag{dirty: true, gen: t.cachegen}
}
dirty为ture意味着节点被修改了。gen是当前trie的cachegen。
Trie会检查哪些节点是否可以从缓存里卸载掉,当节点的gen大于节点的cachegen-cachelimit的时候,说明它们很久没有被访问了,这些节点就被移出缓存
Trie.go
func (t *Trie) resolveHash(n hashNode, prefix []byte) (node, error) {
cacheMissCounter.Inc(1) //每执行一次cache计数器+1
hash := common.BytesToHash(n)
// 通过hash从DB中取出node的RLP编码内容(如果node存在,否则返回空)
enc, err := t.db.Node(hash)
if err != nil || enc == nil {
return nil, &MissingNodeError{NodeHash: hash, Path: prefix}
}
return mustDecodeNode(n, enc, t.cachegen), nil
}
mustDecodeNode中调用了decodeNode,这个方法通过RLP解码得出的list长度来判断该编码内容属于哪种节点:如果是两个字段(2-item)则为shortNode,如果是17个字段(17-item)则为fullNode。然后再调用各自的decode解析函数。
func decodeNode(hash, buf []byte, cachegen uint16) (node, error) {
if len(buf) == 0 {
return nil, io.ErrUnexpectedEOF
}
elems, _, err := rlp.SplitList(buf) //将buf拆分为列表的内容以及列表后的任何剩余字节。
if err != nil {
return nil, fmt.Errorf("decode error: %v", err)
}
switch c, _ := rlp.CountValues(elems); c {
case 2:
n, err := decodeShort(hash, elems, cachegen) //decode shortNode
return n, wrapError(err, "short")
case 17:
n, err := decodeFull(hash, elems, cachegen) //decode fullNode
return n, wrapError(err, "full")
default:
return nil, fmt.Errorf("invalid number of list elements: %v", c)
}
}
- decodeShort函数中通过key是否含有结束标识符来判断是叶子节点还是扩展节点,这个我们在上面的编码部分已经讲过,有结束标示符则是叶子节点,再通过rlp.SplitString解析出val生成一个叶子节点shortNode返回。没有结束标志符则为扩展节点,通过decodeRef解析并生成一个shortNode返回。
func decodeShort(hash, elems []byte, cachegen uint16) (node, error) {
kbuf, rest, err := rlp.SplitString(elems)
if err != nil {
return nil, err
}
flag := nodeFlag{hash: hash, gen: cachegen}
key := compactToHex(kbuf)
if hasTerm(key) {//是否有结束标志符(也就是判断是否为叶子节点)
// 叶子节点处理
val, _, err := rlp.SplitString(rest)
if err != nil {
return nil, fmt.Errorf("invalid value node: %v", err)
}
return &shortNode{key, append(valueNode{}, val...), flag}, nil
}
//拓展节点处理
r, _, err := decodeRef(rest, cachegen)
if err != nil {
return nil, wrapError(err, "val")
}
return &shortNode{key, r, flag}, nil
}
继续看下拓展节点利用decodeRef怎么处理的?
func decodeRef(buf []byte, cachegen uint16) (node, []byte, error) {
kind, val, rest, err := rlp.Split(buf)
if err != nil {
return nil, buf, err
}
switch {
case kind == rlp.List:
//如果是list,调用decodeNode解析,想一下为什么?
// 'embedded' node reference. The encoding must be smaller
// than a hash in order to be valid.
if size := len(buf) - len(rest); size > hashLen {
err := fmt.Errorf("oversized embedded node (size is %d bytes, want size < %d)", size, hashLen)
return nil, buf, err
}
n, err := decodeNode(nil, buf, cachegen)
return n, rest, err
case kind == rlp.String && len(val) == 0:
// empty node
return nil, rest, nil
case kind == rlp.String && len(val) == 32:
//如果是一个32位hash值返回hashNode
return append(hashNode{}, val...), rest, nil
default:
return nil, nil, fmt.Errorf("invalid RLP string size %d (want 0 or 32)", len(val))
}
}
这段代码比较清晰,通过rlp.Split后返回的类型做不同的处理,如果是空节点返回空,如果是一个32位hash值返回hashNode。想一下什么时候会有rlp.list这种情况?之前有提过,有的hash值不是32位,当是内容长度<32时,hash就是内容本身,那么调用decodeNode进行解析。
- decodeFull函数,解码FullNode,17-item:
func decodeFull(hash, elems []byte, cachegen uint16) (*fullNode, error) {
n := &fullNode{flags: nodeFlag{hash: hash, gen: cachegen}}
for i := 0; i < 16; i++ {
cld, rest, err := decodeRef(elems, cachegen)
if err != nil {
return n, wrapError(err, fmt.Sprintf("[%d]", i))
}
n.Children[i], elems = cld, rest
}
val, _, err := rlp.SplitString(elems)
if err != nil {
return n, err
}
if len(val) > 0 {
n.Children[16] = append(valueNode{}, val...)
}
return n, nil
}
这样我们就找到了hash值对应的node,从而得知node里value值,我们可以对每一个value为hash索引值继续调用resolveHash方法,从而将整棵树从DB中找出。(是不是关于MPT存在性证明有一些思路了呢?:D)
2. MPT存在性证明&不存在性证明
if the root hash of a given trie is publicly known, then anyone can provide a proof that the trie has a given value at a specific path by providing the nodes going up each step of the way. It is impossible for an attacker to provide a proof of a (path, value) pair that does not exist since the root hash is ultimately based on all hashes below it, so any modification would change the root hash.
如果已知RootHash,在已知整棵MPT的情况下,任何人都可以提供某个value存在性证明,只需要从Root节点沿着key到该节点所经过的节点即可,如果该树不存在这个value,攻击者是无法提供一个 (path, value)通过存在性证明生成与已知的RootHash相同的hash值,从而保证了MPT的安全性
存在性证明idea:
Prove constructs a merkle proof for key. The result contains all encoded nodes on the path to the value at key. The value itself is also included in the last node and can be retrieved by verifying the proof.
不存在性证明idea:
If the trie does not contain a value for key, the returned proof contains all nodes of the longest existing prefix of the key (at least the root node), ending with the node that proves the absence of the key.
总结一下,以root节点为开端,沿着SHA3 (ethereumAddress)(状态树)or rlp(transactionIndex)(交易树或者收据树)作为key的路径导向所经历的所有节点,到目标节点(存在性证明)或者拥有与目标节点最多共同前缀的节点(不存在性证明)。
proof.go Prove用于生成(不)存在性证明。
func (t *Trie) Prove(key []byte, fromLevel uint, proofDb ethdb.Putter) error {
// Collect all nodes on the path to key.
key = keybytesToHex(key)
nodes := []node{}
tn := t.root
for len(key) > 0 && tn != nil {
switch n := tn.(type) {
case *shortNode:
if len(key) < len(n.Key) || !bytes.Equal(n.Key, key[:len(n.Key)]) {
// The trie doesn't contain the key.
tn = nil
} else {
tn = n.Val
key = key[len(n.Key):]
}
nodes = append(nodes, n)
case *fullNode:
tn = n.Children[key[0]]
key = key[1:]
nodes = append(nodes, n)
case hashNode:
var err error
tn, err = t.resolveHash(n, nil)
if err != nil {
log.Error(fmt.Sprintf("Unhandled trie error: %v", err))
return err
}
default:
panic(fmt.Sprintf("%T: invalid node: %v", tn, tn))
}
}
hasher := newHasher(0, 0, nil)
defer returnHasherToPool(hasher)
for i, n := range nodes {
// Don't bother checking for errors here since hasher panics
// if encoding doesn't work and we're not writing to any database.
n, _, _ = hasher.hashChildren(n, nil)
hn, _ := hasher.store(n, nil, false)
if hash, ok := hn.(hashNode); ok || i == 0 {
// If the node's database encoding is a hash (or is the
// root node), it becomes a proof element.
//当ok为false的时候,意味着node<32 bytes,并没有经过任何sha3,
if fromLevel > 0 {
fromLevel--
} else {
enc, _ := rlp.EncodeToBytes(n)
if !ok {
hash = crypto.Keccak256(enc)
}
proofDb.Put(hash, enc)
}
}
}
return nil
}
根据proofDb里hash列表进行(不)存在性证明:
func VerifyProof(rootHash common.Hash, key []byte, proofDb DatabaseReader) (value []byte, nodes int, err error) {
key = keybytesToHex(key)
wantHash := rootHash
for i := 0; ; i++ {
//从DB(sha3 hash,node)中根据hash取出node的值(这些node>32byte
)
buf, _ := proofDb.Get(wantHash[:])
if buf == nil {
return nil, i, fmt.Errorf("proof node %d (hash %064x) missing", i, wantHash)
}
//解析 RLP 编码
n, err := decodeNode(wantHash[:], buf, 0)
if err != nil {
return nil, i, fmt.Errorf("bad proof node %d: %v", i, err)
}
//get函数的逻辑
//1.对node根据类型做prove路径选择,遇到sha3 hash值就返回剩余路径和对应的hash值
//2.对于node<32 byte的节点,直接对其本身数据进行解析比对
keyrest, cld := get(n, key)
switch cld := cld.(type) {
case nil:
// The trie doesn't contain the key.
return nil, i, nil
case hashNode:
key = keyrest
copy(wantHash[:], cld)
case valueNode:
return cld, i + 1, nil
}
}
}
func get(tn node, key []byte) ([]byte, node) {
for {
switch n := tn.(type) {
case *shortNode:
if len(key) < len(n.Key) || !bytes.Equal(n.Key, key[:len(n.Key)]) {
return nil, nil
}
tn = n.Val
key = key[len(n.Key):]
case *fullNode:
tn = n.Children[key[0]]
key = key[1:]
case hashNode:
return key, n
case nil:
return key, nil
case valueNode:
return nil, n
default:
panic(fmt.Sprintf("%T: invalid node: %v", tn, tn))
}
}
}
存在性证明的PoC代码见本文最后
3. MPT Get & Insert & Update & Delete & Commit操作?
值得注意的是:Trie树的插入,查找和删除 Trie树的初始化调用New函数,函数接受一个hash值和一个Database参数,如果hash值不是空值的化,就说明是从数据库加载一个已经存在的Trie树, 就调用trei.resolveHash方法来加载整颗Trie树,上文已介绍。
- Get逻辑如下:
- 将key进行Hex编码为encodedKey
- 从根节点开始与encodedKey从第0位开始一一比对,递归调用,假设存在,如果最终递归到ValueNode,返回其value,didResolve设为false;如果递归到HashNode,则根据hashNode.value去db中获取该node值。(didResolve设为true,用来表示trie树发生变化,获取到value后,需要更新现有的整棵trie。)
func (t *Trie) TryGet(key []byte) ([]byte, error) {
key = keybytesToHex(key)
value, newroot, didResolve, err := t.tryGet(t.root, key, 0)
if err == nil && didResolve {
t.root = newroot
}
return value, err
}
func (t *Trie) tryGet(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
// 就是要查找的叶子节点数据
return n, n, false, nil
case *shortNode:
if len(key)-pos < len(n.Key) || !bytes.Equal(n.Key, key[pos:pos+len(n.Key)]) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.tryGet(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n = n.copy()
n.Val = newnode
n.flags.gen = t.cachegen
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.tryGet(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n = n.copy()
n.flags.gen = t.cachegen
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
// hashNodes时候需要去db中获取
child, err := t.resolveHash(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.tryGet(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}
-
Insert 逻辑如下:
Trie树的插入,这是一个递归调用的方法,从根节点开始,通过匹配前缀一直往下找,直到找到可以插入的点,进行插入操作。参数node是当前插入的节点, prefix是当前已经处理完的部分key, key是还没有处理完的部分key, 完整的key = prefix + key。 value是需要插入的值。 返回值bool是操作是否改变了Trie树(dirty),node是插入完成后的子树的根节点, error是错误信息。
如果节点类型是nil(一颗全新的Trie树的节点就是nil的),这个时候整颗树是空的,直接返回shortNode{key, value, t.newFlag()}, 这个时候整颗树的跟就含有了一个shortNode节点。
-
如果当前的根节点类型是shortNode(也就是叶子节点),首先计算公共前缀,
- 如果公共前缀就等于key,那么说明这两个key是一样的,如果value也一样的(dirty == false),那么返回错误。 如果没有错误就更新shortNode的值然后返回。
- 如果公共前缀不完全匹配,那么就需要把公共前缀提取出来形成一个独立的前缀节点(扩展节点),扩展节点后面连接一个branch节点,branch节点后面看情况连接两个节点。首先构建一个branch节点(branch := &fullNode{flags: t.newFlag()}),然后再branch节点的Children位置调用t.insert插入剩下的两个节点。
- 如果匹配的长度是0,那么直接返回一个branch节点,branch节点后面看情况连接short节点,其后操作同上。
如果当前的节点是fullNode(也就是branch节点),那么直接往对应的孩子节点调用insert方法,然后把对应的孩子节点只想新生成的节点。
如果当前节点是hashNode, hashNode的意思是当前节点还没有加载到内存里面来,还是存放在数据库里面,那么首先调用 t.resolveHash(n, prefix)来加载到内存,然后对加载出来的节点调用insert方法来进行插入。
func (t *Trie) insert(n node, prefix, key []byte, value node) (bool, node, error) {
if len(key) == 0 {
if v, ok := n.(valueNode); ok {
return !bytes.Equal(v, value.(valueNode)), value, nil
}
return true, value, nil
}
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
// If the whole key matches, keep this short node as is
// and only update the value.
if matchlen == len(n.Key) {
dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value)
if !dirty || err != nil {
return false, n, err
}
return true, &shortNode{n.Key, nn, t.newFlag()}, nil
}
// Otherwise branch out at the index where they differ.
branch := &fullNode{flags: t.newFlag()}
var err error
_, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val)
if err != nil {
return false, nil, err
}
_, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value)
if err != nil {
return false, nil, err
}
// Replace this shortNode with the branch if it occurs at index 0.
if matchlen == 0 {
return true, branch, nil
}
// Otherwise, replace it with a short node leading up to the branch.
return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil
case *fullNode:
dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value)
if !dirty || err != nil {
return false, n, err
}
n = n.copy()
n.flags = t.newFlag()
n.Children[key[0]] = nn
return true, n, nil
case nil:
return true, &shortNode{key, value, t.newFlag()}, nil
case hashNode:
// We've hit a part of the trie that isn't loaded yet. Load
// the node and insert into it. This leaves all child nodes on
// the path to the value in the trie.
rn, err := t.resolveHash(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.insert(rn, prefix, key, value)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v", n, n))
}
}
Update和Delete逻辑类似于Insert:这里简单讲一下其idea,详细可以参考代码:Trie.go
- Update的idea:一个递归调用的方法,从根节点开始,通过匹配前缀一直往下找,直到找到可以相应key的node,更换其value,若无,insert一个。
- Delete的idea:一个递归调用的方法,从根节点开始,通过匹配前缀一直往下找,直到找到该删除的点,删掉,可能复杂一点的就是:删掉共享一个branch node两个leaf node之一 ,而且该branch node的value为空,将该branch node的父 short node 用于存储剩下的那个leaf node。
在 trie.Trie 结构体的 insert(),delete()等函数实现中,可以看到除了新创建的 fullNode、shortNode,那些子结构有所改变的 fullNode、shortNode 的 nodeFlag 成员也会被重设,hashNode 会被清空。在下次 trie.Commit()调用时,整个 MPT 自底向上的遍历过程中,所有清空的 hashNode 会被重新赋值。这样 trie.Hash()结束后,我们可以得到一个根节点 root 的 hashNode,它就是此时此刻这个 MPT 结构的哈希值。
-
Commit
Commit目的,是将trie树中的key转为Compact编码,为每个节点生成一个hash,它就是为了确保后续能正常将变动的数据提交到db.也就是之上提到的序列化过程。Example MPT部分,最后通过调用Commit()函数将新生成的trie存入到db中:
root, err := trie.Commit()
trie.go
func (t *Trie) Commit() (root common.Hash, err error) {
if t.db == nil {
panic("Commit called on trie with nil database")
}
return t.CommitTo(t.db)
}
// CommitTo writes all nodes to the given database.
// Nodes are stored with their sha3 hash as the key.
//
// Committing flushes nodes from memory. Subsequent Get calls will
// load nodes from the trie's database. Calling code must ensure that
// the changes made to db are written back to the trie's attached
// database before using the trie.
func (t *Trie) CommitTo(db DatabaseWriter) (root common.Hash, err error) {
hash, cached, err := t.hashRoot(db)
if err != nil {
return (common.Hash{}), err
}
t.root = cached
t.cachegen++
return common.BytesToHash(hash.(hashNode)), nil
}
func (t *Trie) hashRoot(db DatabaseWriter) (node, node, error) {
if t.root == nil {
return hashNode(emptyRoot.Bytes()), nil, nil
}
h := newHasher(t.cachegen, t.cachelimit)
defer returnHasherToPool(h)
//值得注意!对于root的hash运算,force被设置为true,必须执行sha3()
return h.hash(t.root, db, true)
}
hasher.go
// hash collapses a node down into a hash node, also returning a copy of the
// original node initialized with the computed hash to replace the original one.
func (h *hasher) hash(n node, db *Database, force bool) (node, node, error) {
// If we're not storing the node, just hashing, use available cached data
//叶子节点只需要将其hash值从cache中取出来
if hash, dirty := n.cache(); hash != nil {
if db == nil {
return hash, n, nil
}
if n.canUnload(h.cachegen, h.cachelimit) {
// Unload the node from cache. All of its subnodes will have a lower or equal
// cache generation number.
cacheUnloadCounter.Inc(1)
return hash, hash, nil
}
//这也是为什么MPT树只用针对dirty的节点进行重新hash运算
if !dirty {
return hash, n, nil
}
}
// Trie not processed yet or needs storage, walk the children
collapsed, cached, err := h.hashChildren(n, db)
if err != nil {
return hashNode{}, n, err
}
hashed, err := h.store(collapsed, db, force)
if err != nil {
return hashNode{}, n, err
}
// Cache the hash of the node for later reuse and remove
// the dirty flag in commit mode. It's fine to assign these values directly
// without copying the node first because hashChildren copies it.
cachedHash, _ := hashed.(hashNode)
switch cn := cached.(type) {
case *shortNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
case *fullNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
}
return hashed, cached, nil
}
hasher的hash方法主要做了两个操作。 一个是保留原有的树形结构,并用cache变量中, 另一个是计算原有树形结构的hash并把hash值存放到cache变量中保存下来。
首先要理解的是:MPT的hash计算也是从根节点开始,依次向上递归调用,直至树根。计算原有hash值的主要流程是首先调用h.hashChildren(n,db)把所有的子节点的hash值求出来,把原有的子节点替换成子节点的hash值。 这是一个递归调用的过程,会从树叶依次往上计算直到树根。然后调用store方法计算当前节点的hash值,并把当前节点的hash值放入cache节点,设置dirty参数为false(新创建的节点的dirty值是为true的),然后返回。
// hashChildren replaces the children of a node with their hashes if the encoded
// size of the child is larger than a hash, returning the collapsed node as well
// as a replacement for the original node with the child hashes cached in.
func (h *hasher) hashChildren(original node, db *Database) (node, node, error) {
var err error
switch n := original.(type) {
case *shortNode:
// Hash the short node's child, caching the newly hashed subtree
collapsed, cached := n.copy(), n.copy()
collapsed.Key = hexToCompact(n.Key)
cached.Key = common.CopyBytes(n.Key)
//如果这个节点的value是hashNode,节点为extension node,则“深入”子节点去递归计算其hash值,并返回放到collapsed.Val中。其二值得注意的是:force设为了“false”
if _, ok := n.Val.(valueNode); !ok {
collapsed.Val, cached.Val, err = h.hash(n.Val, db, false)
if err != nil {
return original, original, err
}
}
return collapsed, cached, nil
case *fullNode:
// Hash the full node's children, caching the newly hashed subtrees
collapsed, cached := n.copy(), n.copy()
for i := 0; i < 16; i++ {
if n.Children[i] != nil {
//类似,force也设为了“false”
collapsed.Children[i], cached.Children[i], err = h.hash(n.Children[i], db, false)
if err != nil {
return original, original, err
}
}
}
cached.Children[16] = n.Children[16]
return collapsed, cached, nil
//叶子节点直接返回其本身
default:
// Value and hash nodes don't have children so they're left as were
return n, original, nil
}
}
hashChildren方法,这个方法把所有的子节点替换成他们的hash,可以看到cache变量接管了原来的Trie树的完整结构,collapsed变量把子节点替换成子节点的hash值。
如果当前节点是shortNode, 首先把collapsed.Key从Hex Encoding 替换成 Compact Encoding, 然后递归调用hash方法计算子节点的hash和cache,这样就把子节点替换成了子节点的hash值,
如果当前节点是fullNode, 那么遍历每个子节点,把子节点替换成子节点的Hash值,
否则的化这个节点没有children。直接返回。
执行完hashChildren方法之后,会执行store方法。如果一个node的所有子节点都替换成了子节点的hash值,那么直接调用rlp.Encode方法对这个节点进行编码,如果编码后的值小于32,并且这个节点不是根节点,那么就把他们直接存储在他们的父节点里面,否者调用h.sha.Write方法进行hash计算, 然后把hash值和编码后的数据存储到数据库里面,然后返回hash值。
func (h *hasher) store(n node, db DatabaseWriter, force bool) (node, error) {
// Don't store hashes or empty nodes.
if _, isHash := n.(hashNode); n == nil || isHash {
return n, nil
}
// Generate the RLP encoding of the node
h.tmp.Reset()
if err := rlp.Encode(h.tmp, n); err != nil {
panic("encode error: " + err.Error())
}
if h.tmp.Len() < 32 && !force {
return n, nil // Nodes smaller than 32 bytes are stored inside their parent
}
// Larger nodes are replaced by their hash and stored in the database.
hash, _ := n.cache()
if hash == nil {
h.sha.Reset()
h.sha.Write(h.tmp.Bytes())
hash = hashNode(h.sha.Sum(nil))
}
if db != nil {
// We are pooling the trie nodes into an intermediate memory cache
hash := common.BytesToHash(hash)
db.lock.Lock()
db.insert(hash, h.tmp, n)
db.lock.Unlock()
//此处对应存储树
// Track external references from account->storage trie
if h.onleaf != nil {
switch n := n.(type) {
case *shortNode:
if child, ok := n.Val.(valueNode); ok {
h.onleaf(child, hash)
}
case *fullNode:
for i := 0; i < 16; i++ {
if child, ok := n.Children[i].(valueNode); ok {
h.onleaf(child, hash)
}
}
}
}
}
return hash, nil
}
可以看到每个值大于32的节点的值和hash都存储到了数据库里面,而小于32bytes的节点就存在其父节点里了,,这也是为了反序列化操作减少重复存储。
了解以上流程之后针对Example MPT的PoC代码如下:
//POC
func TestElementProofsy(t *testing.T) {
trie := newEmpty()
updateString(trie, "do", "verb")
updateString(trie,"dog","puppy")
updateString(trie,"doge","coin")
updateString(trie,"horse","stallion")
root, err :=trie.Commit(nil)
if err != nil {
t.Fatal("commit error")
}
println(hex.EncodeToString(root.Bytes()))
}
...(省略部分,主要截取修改过的代码)
func (h *hasher) store(n node, db *Database, force bool) (node, error) {
// Don't store hashes or empty nodes.
if _, isHash := n.(hashNode); n == nil || isHash {
return n, nil
}
// Generate the RLP encoding of the node
h.tmp.Reset()
if err := rlp.Encode(&h.tmp, n); err != nil {
panic("encode error: " + err.Error())
}
if len(h.tmp) < 32 && !force {
//POC
println("... self hash: "+hex.EncodeToString(h.tmp))
return n, nil // Nodes smaller than 32 bytes are stored inside their parent
}
// Larger nodes are replaced by their hash and stored in the database.
hash, _ := n.cache()
if hash == nil {
hash = h.makeHashNode(h.tmp)
}
if db != nil {
//POC
println("... sha3 hash: "+hex.EncodeToString(hash))
// We are pooling the trie nodes into an intermediate memory cache
hash := common.BytesToHash(hash)
db.lock.Lock()
db.insert(hash, h.tmp, n)
db.lock.Unlock()
}
return hash, nil
}
测试结果:

(不)存在性证明POC代码如下:
func TestElementProofsy(t *testing.T) {
trie := newEmpty()
updateString(trie, "do", "verb")
updateString(trie,"dog","puppy")
updateString(trie,"doge","coin")
updateString(trie,"horse","stallion")
root, err :=trie.Commit(nil)
if err != nil {
t.Fatal("commit error")
}
println("root : ",hex.EncodeToString(root.Bytes()))
for i, prover := range makeProvers(trie) {
proof := prover([]byte("doge"))
if proof == nil {
t.Fatalf("prover %d: nil proof", i)
}
//POC
println("\n***Verify Proof now!")
val, _, err := VerifyProof(trie.Hash(), []byte("doge"), proof)
if err != nil {
t.Fatalf("prover %d: failed to verify proof: %v\nraw proof: %x", i, err, proof)
}
if !bytes.Equal(val, []byte("coin")) {
t.Fatalf("prover %d: verified value mismatch: have %x, want 'coin'", i, val)
}
println("\n***prover verified successful")
}
}
func makeProvers(trie *Trie) []func(key []byte) *ethdb.MemDatabase {
var provers []func(key []byte) *ethdb.MemDatabase
// Create a direct trie based Merkle prover
provers = append(provers, func(key []byte) *ethdb.MemDatabase {
proof := ethdb.NewMemDatabase()
//POC
println("\n***Create Merkle trie provers")
trie.Prove(key, 0, proof)
return proof
})
return provers
}
-
存在key,存在性证明&value不匹配,验证失败
 image
image -
不存在key,不存在性证明&验证失败
 image
image -
存在key,存在性证明&value匹配,验证成功
 image
image
LevelDB 写优化==》mLSM 跟老船长讨论TODO
security_trie 的idea
在security_trie.go这样介绍:
// SecureTrie is not safe for concurrent use.
这个代码不稳定,除了测试用例,别的地方并没有使用该代码。但是idea仍然值得一提:
为了避免使用太长的key导致访问时间太久(这也是目前以太坊一大瓶颈),以太坊用security_trie对上述trie作了一个封装,使得最后所有的key都转换成keccak256算法计算的hash值。同时在数据库里映射存储了对应的原有key。