
来源:Visual Genome、thehindu
译者:王嘉俊 王婉婷 李宏菲
【新智元导读】ImageNet 已经成为全球最大的图像识别数据库,每年一度的比赛也牵动着各大巨头公司的心弦,如今图像识别已经能做到很高的水准。下一步是图像理解,ImageNet 创始人李飞飞开启了 Visual Genome(视觉基因组)计划,要把语义和图像结合起来,推动人工智能的进一步发展。近日 Visual Genome 论文发布,李飞飞要给我们带来怎样的惊喜?
几年前,机器学习的技术突破,让计算机学会了识别照片中的物体,而且非常准确。
现在的问题是,计算机能否带来另一个飞跃:学会理解相片中究竟发生着什么事。
一个叫 Visual Genome 的图像数据库,可能会推动计算机实现这个目标。它由斯坦福计算机视觉教授、人工智能实验室主任李飞飞和几个同事开发,我们知道李飞飞教授过去创建了 ImageNet,而 Visual Genome 是后 ImageNet 时代计算机视觉在理解图片上的训练和测试数据集。
在 Visual Genome 的官方网站上,把它定义为:
Visual Genome 是一个数据集,知识库,不断努力把结构化的图像概念和语言连接起来。
网站:https://visualgenome.org
目前包含:
108249 张图片
420 万对区域的描述(Region Descriptions)
170 万视觉问答(Visual Question Answers)
210 万对象案例(Object Instances)
180 万属性(Attributes)
180 万关系(Relationships)
所有的东西都映射到 Wordnet Synsets
教会计算机解析视觉图像是人工智能非常重要的任务,这不久能带来更多有用的视觉算法,而且也能训练计算机更为高效的沟通。毕竟,在表达真实世界的时候,语言总是受到很大的限制。
“我们专注在计算机视觉领域的一些最艰难的问题,给感知和认知建立一个桥梁,”李飞飞说:“不仅仅是处理像素的数据、知道它的颜色、阴影等事情,而且要把它们转变成 3D 形式以进行更全面的理解,带来语义视觉的世界。”
ImageNet 包含了超过 100 万张图片的数据集,里面的内容都有很好的标记。每年,ImageNet 大规模视觉识别挑战赛都会测试计算机在自动识别图像内容的能力。Visual Genome 的图像要比 ImageNet 的图像标签更为丰富,包括名字、图片的不同细节,以及在对象和动作信息之间的关系。
Visual Genome 使用了众包的方式实现,由李飞飞一位同事 Michael Bernstein 提出。
2017 年计划使用 Visual Genome 数据集推出 ImageNet 风格的挑战赛。(Visual Genome 挑战赛?)
论文全文
Visual Genome:Connecting Language and Vision Using Crowdsourced Dense Image Annotations
视觉基因组:使用众包密集图像注释以联结语言和视觉
作者:Ranjay Krishna · Yuke Zhu · Oliver Groth · Justin Johnson· Kenji Hata · Joshua Kravitz · Stephanie Chen · Yannis Kalantidis · Li-Jia Li · David A. Shamma · Michael S. Bernstein · Li Fei-Fei
摘要
尽管在感知的任务上(例如图像分类)计算机有很多进展,但是在认知的任务上(例如图像描述和问答),计算机表现的不怎么样。如果我们不仅仅诉求识别出图像,而要深究我们视觉世界的意义,那么认知是最核心的任务。被用于解决图片内容丰富的认知任务的模型,依然使用给感知任务设计的相同数据集来训练。要在认知任务中获得成功,模型需要理解对象和物体之间的交互和关系。当问道:“这个人正在骑着什么交通工具?”的时候,计算机需要识别出图片中的物体,以及里面的关系“骑行”(人、马车)和“拉车”(马、马车),这样才能正确回答“这个人正坐着马车”。
在这篇论文中,我们介绍了 Visual Genome 数据集,以及使用这种关系进行建模。我们收集了对象、属性、图片里关系的密集注释,以学习这些模型。特别的,我们的数据集包括了超过 10 万张图片,每一张图片都包含了平均 21 个对象,18 种属性和 18 种物体之间的关系。我们规范化了从对象、属性、关系、区域描述里的名词和短语和问答对到 WordNet 同义词集的关系。这些注释代表了图像描述、属性、关系和问答里最密集、规模最大的数据集。
关键词:Computer Vision · Dataset · Image · Scene Graph · Question Answering · Objects · Attributes · Relationships · Knowledge · Language · Crowdsourcing
1、介绍:
计算机视觉领域的圣杯,是完全理解图像里的场景:一个能够命名并且检测物体的模型,描述它们的属性,识别出它们的关系和交互。理解场景会带来重要的应用,例如图片搜索、问答、机器人交互等。为了实现这个目标,最近几年已经有了很多的进展,包括图片的分类任务和对象识别上。
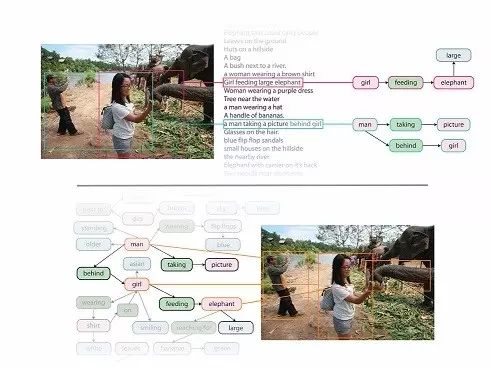

一个起作用的重要因素是大规模数据的可利用性,这驱动了统计模型,构成了今天我们计算视觉理解进展的基础。虽然这个进展很让人兴奋,但我们离理解图像的目标还有很远的距离。正如图 1 显示的,现在的模型能够探测出相片中的潜在物体,但没有能力解释它们之间的的交互和关系。这种解释性的行为倾向于自然界的认知,整合感知的信息得出关于图片物体之间关系的结论。对我们视觉世界的认知理解,因而需要我们在计算机识别物体的能力之外,补充描述物体和理解他们之间交互关系的能力。
在把下一代的数据集整合在一起,以服务于深度、认知图像理解任务的训练和基准测试,现在有越来越多的努力,其中最出名的是 MS-COCO 和 VQA。MS-COCO 数据集包含了从 Flickr 收集来的 30 万张真实世界的照片。每一张图片,都像素级别的分割成 91 种对象级别和 5 个独立的、用户生成的句子,以描述这个场景。VQA 给相关图片的视觉内容增加了 61.4 万的问答对。在这些信息下,MS-COCO 和 VQA 给致力于精准物体识别、分割、给图片总结性的文字和基础的问答任务的模型,提供了多产的训练和测试基础。例如,最前沿的模型提供了对 MS-COCO 图片(图1)的描述“两个人站在一只象旁边”。但是关于进一步理解各个对象在哪里,每个人在做什么,人和象的关系是什么,都丢失掉了。没有这样的关系,这个模型没法把它和其他人站在大象旁边的图片区分开来。
为了更彻底的理解图像,我们认为有三个关键元素需要添加到现在的数据集中:
1、将视觉概念落实到语义层面(a grounding of visual concepts to language)
2、基于多区域图片的更加完整描述和问答(more complete set of descriptions and QAs)
3、对图片各个组成的形式化表示(a formalized representation of the components of an image)
出于把视觉世界里面的完全信息映射出来,我们向大家介绍 Visual Genome 数据集。Visual Genome 数据集的第一次发布使用了 108249 张图片,来自于 YFCC100M 和 MS-COCO 的交集。章节 5 对这个数据集有更详细的描述。我们会在下面强调,正是这三个关键因素的动机和贡献,让 Visual Genome 和其他已有的数据集有很大的差异化。
除了传统的对对象进行关注外,Visual Genome 数据集把关系和属性,作为注释里面的头等公民看待。对于完整理解一张图片而言,对关系和属性的识别是非常重要的部分,而在很多案例中,这些部分是讲述场景故事的关键(例如“一只狗追着人跑”和“一个人追着狗跑”的不同)。Visual Genome 是首个提供物体的交互和属性的详细标签,将视觉概念落实到语义层面的数据集。
通常来说,一张图片有丰富的场景,但很难用一个句子完全描述。图1 包含了很多故事“一个男人正在给象拍照”,“一个女人正在喂食一头象”,“一条河背后葱葱郁郁的地面”等。现在的数据库例如 Flickr 30K 和 MS-COCO 专注于对图像进行高层次的描述。相对的,对于 Visual Genome 数据集里的每一张图片,我们收集了 图片中不同区域的 42 种描述,提供了更加密集和完全的图像描述。另外,在 VQA 的激发下,我们也根据对每张图片的描述,平均收集了 17 种问答对。基于区域的问答可以被用于共同发展 NLP 和视觉模型,可以根据描述或图片,或者两者以回答问题。
通过一张图片的密集描述、视觉像素(对象的界限)和文字描述(关系,属性)的明确对应,Visual Genome 现在是第一个能够提供结构化的对图片进行形式化表示的数据集,在这种形式下能够大量用于 NLP 的基于知识的展示中。例如在图 1 ,我们可以正式的表达出“举着”这个关系涉及到女人和食物。把所有的对象和他们在图片中的关系放在一起,我们可以把每幅图片看作是场景图。场景图展示被用于提升提高语义图片的检索和给图片加上说明。更进一步说,Visual Genome 里面每一张图片的所有对象、属性和关系,都会建立和 Word-Net 的规范化映射。这个映射联结了所有 Visual Genome 的图片,也提供了有效的方法对数据集里相同的概念(对象、属性或关系)有一致的提问。它也可能帮助训练模型,从多张图片的上下文信息中学习。
在这篇论文中,为了能够高效地展开模型的训练以及定立能够用于综合场景理解的下一代计算机模型基准,我们引进了Visual Genome 数据集。这篇论文的安排如下:章节2,我们展现了关于数据集中各个组成部分的细节描述。章节3,展示了相关数据集以及相关识别任务的回顾。章节4,讨论了我们在持续努力收集这个数据集的过程中采用的众包策略。章节5,是对数据统计分析的收集,展示了Visual Genome 数据集的特性。最后同等重要的是,章节6展示了采用了Visual Genome 数据集作为基准进行实验研究的一组实验结果。
未来,基于Visual Genome 数据集的可视化模型、API、以及其它信息可以在线获取。
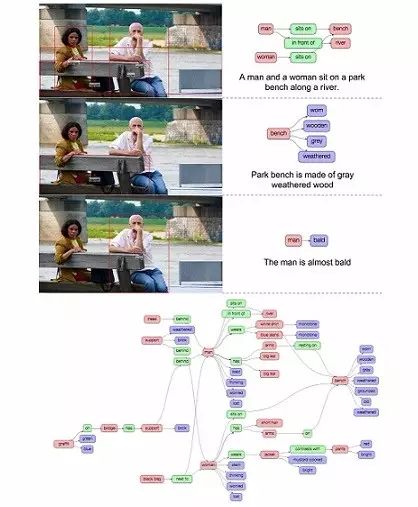
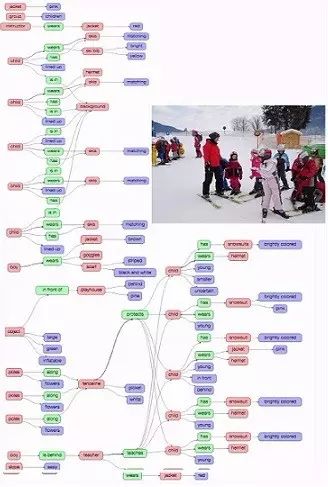
2、Visual Genome 的数据表现
Visual Genome 数据集包括 7 个主要部分:区域描述、对象、属性、关系、区域图、场景图和问答对。图 4 展示了一幅画的每一个部分的例子。要对图像进行理解的研究,我们从收集描述和问答对开始。这些是原始的文本,没有任何长度和词汇的限制。下一步,我们从描述中提取对象、属性和关系。这些对象、属性和关系一起构造了我们的场景图,这代表了一般的图像。在这个章节中,我们分解了图像 4,也对里面的 7 个部分分别进行了解释。在章节 4 中,我们会对此进行更详尽的描述,来自各个部分的数据,是如何通过众包平台收集的。
2.1 多区域和对它们的描述
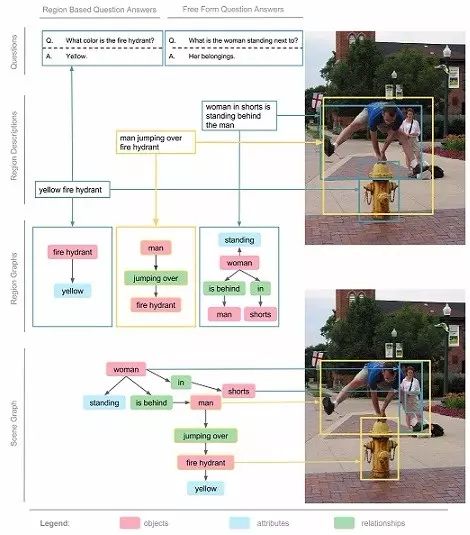
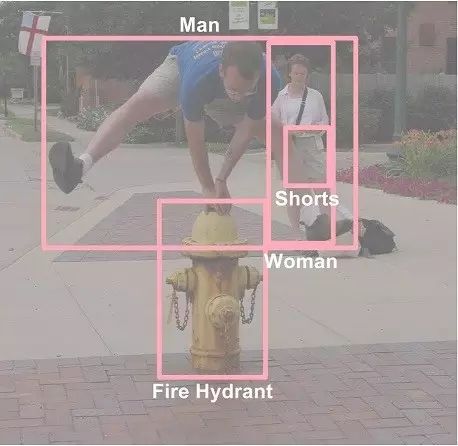
在真实世界中,一个简单的总结,往往不足以描述图片的所有内容和交互。相反,一个自然的扩展方法是,对图像的不同区域进行分别描述。在 Visual Genome 中,我们收集了人们对图像不同区域的描述,每一个区域都由边框进行坐标限定。在图像 5 中,我们展示了按区域描述的 3 个案例。不同的区域之间被允许有高度的重复,而描述会有所不同。例如说,“黄色消防栓”和“穿短裤的姑娘正站在男人的背后”的重叠部分非常少,但“男人跳过消防栓”和其他两个区域有着很高的重叠。我们的数据对每一张图片平局有着 42 种区域描述。每一个描述都是一个短语包含着从 1 到 16 个字母长度,以描述这个区域。
2.2 多个物体与它们的边框
在我们的数据集中,平均每张图片包含21个物体,每个物体周围有一个边框(见图6)。不仅如此,每个物体在WordNet中都有一个规范化的ID。比如,man和person会被映射到man.n.03|(the generic use of the word to refer to any human being)。相似的,person被映射到person.n.01 (a human being)。随后,由于存在上位词man.n.03,这两个概念就可以加入person.n.01中了。这是一个重要的标准化步骤,以此避免同一个物体有多个名字(比如,man,person,human),也能在不同图片间实现信息互联。

2.3 一组属性
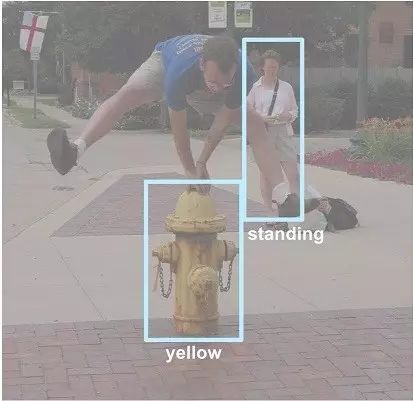
Visual Genome中,平均每张图片有16个属性。一个物体可以有0个或是更多的属性。属性可以是颜色(比如yellow),状态(比如standing),等等(见图7)。就像我们从区域描述中提取物体一样,我们也能提取出这些物体自身的属性。在图7中,从短语“yellow fire hydrant”里,我们提取到了“fire hydrant”有“yellow”属性。和物体一样,我们也把属性在WordNet中规范化;比如,yellow被映射到yellow.s.01 (of the color intermediate between green and orange in the color spectrum; of something resembling the color of an egg yolk)。
2.4 一组关系
“关系”将两个物体关联到一起,可以是动作(比如jumping over),空间位置(比如is behind),动词(比如wear),介词(比如with),比较词(比如taller than),或者是介词短语(比如drive on)。例如,从区域描述“man jumping over fire hydrant”中,我们提取到物体man和物体fire hydrant之间的关系是jumping over(见图8)。这些关系是从一个物体(也叫主体)指向另一个物体(也叫客体)的。在这个例子里,主体是man,他正在对客体fire hydrant表现出jumping over的关系。每个关系也在WordNet中有规范化的synset ID:jumping被映射到jump.a.1 (move forward by leaps and bounds)。平均而言,我们数据集中的每张图片包含18个关系。

2.5 一组区域图
我们将从区域描述中提取的物体、属性、以及关系结合在一起,每42个区域创造一幅有向图表征。区域图的样子见图4。每幅区域图都是对于图片的一部分所做的结构化表征。区域图中的节点代表物体、属性、以及关系。物体与它们各自的属性相连,而关系则从一个物体指向另一个物体。图4中连接两个物体的箭头,从主体物体指向关系,再从关系指向其他物体。
2.6 全景图
区域图是一张图片某一区域的表征,我们也将它们融合在一起成为一幅能表征整张图片的全景图。全景图是所有区域图的拼合,包括每个区域描述中所有的物体、属性、以及关系。通过这个方式,我们能够以更连贯的方式结合多个层次的全景信息。例如,在图4中,最左边的区域描述告诉我们“fire hydrant is yellow”,而中间的区域描述告诉我们“man is jumping over the fire hydrant”。将它们拼合在一起以后,这两个描述告诉我们的是“man is jumping over a yellow fire hydrant”。
2.7 一组问答
我们的数据集中,每张图片都有两类问答:基于整张图片的随意问答(freeform QAs),以及基于选定区域的区域问答(region-based QAs)。我们为每张图片收集了6个不同类型的问题:what,where,how,when,who,以及why。在图4中,“问:女人站在什么的边上?;答:她的行李”就是一个随意问答。每张图片的问题都包含了这6个类型,每个类型至少有1个问题。区域问答是通过区域描述收集的。例如,我们通过“黄色消防栓”的描述收集到了这个区域问答:“问:消防栓是什么颜色的?;答:黄色”。区域问答让我们能够独立地研究如何优先运用NLP和视觉来回答问题。
3、众包策略
Visual Genome的数据收集和验证工作全部是由Amazon Mechanical Turk的众包工人(crowd workers)完成的。在这一节中,我们概括了一些创造数据集时运用到的途径。每个元素(区域描述、物体、属性、关系、区域图、全景图、问答)都包含了多个任务阶段。我们用了不同的策略来让保持数据的准确性和每个元素的多样性。我们也提供了这些帮助Visual Genome建立起来的众包工人的背景信息。
3.1 验证
一旦标注完成,所有的Visual Genome数据都会进入一个验证阶段。这个阶段能够帮助消除被错误标记的物体、属性、以及关系。它也能够帮助移除一些可能正确却有些含糊(比如“这个人看上去在享受阳光”)、主观(比如“屋子看上去很脏”)、或是武断(比如“暴露在这种艳阳下可能会导致癌症”)的区域描述和问答。
验证是通过两种不同的策略实施的:多数人投票(majority voting)和快速判断(rapid judgments)。数据集中除了物体之外的元素都是使用多数人投票的方式来验证的。多数人投票的方法是,由3个众包工人阅读每一条注释,随后判断注释是否在事实上是正确的(factually correct)。只有当3人中至少2人认可后,这条注释才会被加入我们的数据集中。
我们只在物体的判别上使用快速判断来加快验证速度。快速判断用到一种受快速序列视觉加工(rapid serial visual processing)所启发而产生的交互界面,能够让对物体的验证在速度上比多数人投票有量级的提升。
3.2 规则化
我们收集的所有描述和问答都是众包工人们写下的形式自由的文字。例如,我们并不强迫众包工人一定要将图片中的一个男性写作man。我们允许他们择取各种表达,比如person,boy,man,等等。这种模糊性使得我们难以从数据集中收集所有man的例子。为了减少这些概念的模糊性、并将我们的数据集与学术圈中使用的其他资源相联系,我们将所有的物体、属性、关系、以及区域描述和问答中名词短语都映射到了WordNet的同义词集合(synset)中。在刚才的例子里,person、boy、和man会被分别映射到以下同义词集合:person.n.01 (a human being),male_child.n.01 (a youthful male person),以及man.n.03 (the generic use of the word to refer to any human being)。由于WordNet具有的层级结构,我们可以将这三种表达都融入到同一个概念(person.n.01 (a human being))中——因为这是这几个同义词集合的最低层次公共祖先节点(lowest common ancestor node)。
我们使用Stanford NLP工具来从区域描述和问答中提取名词短语。接着,根据WordNet的词素计数(lexeme counts),我们将它们映射到WordNet中最频繁匹配(most frequent matching)的同义词集合里。随后,我们为30中最常见的失败案例人工创造了映射规则,以此完善这种简单的映射逻辑。比如,根据WordNet的词素计数,table最常见的语义是table.n.01 (a set of data arranged in rows and columns)。然而在我们的数据中,更有可能出现家具,因此映射应该倾向于table.n.02 (a piece of furniture having a smooth flat top that is usually supported by one or more vertical legs)。全景图中的物体已经是名词短语了,也依据相同的方式映射到WordNet中。
我们基于形态学(morphology)对每一个属性都做了正态化,并将它们映射到WordNet中。我们另外加入了15个人工创造的规则来应对常见的失败案例。例如,同义词集合long.a.02 (of relatively great or greater than average spatial extension)在WordNet中不如long.a.01 (indicating a relatively great or greater than average duration of time)常见,但是这个词在我们的图片中更有可能指的是前者。
对于关系,我们忽略了其中所有的介词,因为介词无法被WordNet识别。因为动词的意思在很大程度上依赖于它们的形态和在句子中的位置(例如,被动态、介词短语),我们尝试在WordNet中寻找语句框架与数据集中关系的语境相匹配的同义词集合。WordNet中的语句框架是一种形式化的语法框架,例如,play.v.01: participate in games or sport出现在“Somebody [play]s”和“Somebody [play]s something”。随后,对于每个动词-同义词集合的配对,我们使用这个同义词集合的根源上位词,以此降低WordNet细致的语义区分可能带来的噪音。WordNet的动词层级来自超过100个根源动词。例如,draw.v.01: cause to move by pulling可以追溯回根源上位词move.v.02: cause to move or shift into a new position,而draw.v.02: get or derive可以追溯回根源上位词get.v.01: come into the possession of something concrete or abstract。我们也人工添加了20条规则,用以应对常见失败案例。
这些映射并不是完美的,仍然含有一些模糊性。因此,我们将每个映射和它最有可能的4个候选同义词集合发送给Amazon Mechanical Turk,让众包工人们来验证我们的映射是否正确、是否有哪个候选同义词集合更合适。我们像众包工人们展示我们想要规范化的概念与我们提出的对应同义词集合,并给出另外4个候选同义词集合。为了防止众包工人们总是默认我们提出的同义词集合最合适,我们并不会直白地标示出5个同义词集合中哪个是我们提出的。5.8节列出了我们规范化策略的实验精确率(precision)和召回率(recall)。
4.未来应用
我们已经分析了这个数据集的各个组成部分,并且呈现了基于像是属性分类、关系分类、描述生成、回答问题等任务的基线实验结果。然而,我们的数据集能够用于更多的应用和实验任务中。在这个章节中,我们列举了一些未来可能会使用到我们数据集的一些潜在应用。
密集的图像注释。我们已经看到了许多关于图像注释的论文(如:Kiros et al.,2014,Mao et al.,2014,Karpathy and Fei-Fei,2014,Vinyals et al.,2014)。这些论文的大致思想都是尝试用一个图像注释来描述一整幅图像。然而,这些图像注释并没有详尽地描述图像中每一部分的场景。但是通过启用Visual Genome 数据集,能够使得这种应用获得一个自然的延伸。即是通过在Visual Genome 数据集上进行模型的训练,创造出描述图像中每部分场景的密集图像注释模型。
视觉问答。虽然视觉问答作为一个独立的任务被研究。(Yu et al.,2015,Ren et al.,2015a,Antol et al.,2015,Gao et al.,2015),但是我们引进了一个将所有问题的答案说明和场景图片结合起来的数据集。未来工作可以创建一个用Visual Genome(视觉基因组) 数据集的各个组件来解决视觉问答的监督模型。
图像理解。虽然我们已经看到图像注释(Kiros et al.,2014)和问答模型(Antol et al.,2015)的迅猛发展。但是基于此还有一些工作还有待完成。即是创建更多的综合评价指标来衡量这些模型的性能。这样的模型通常用BLEU,CIDEr,或者是METEOR和其它与这些指标相似的指标来进行模型性能的评估。但是这些指标不能很好地评估出这些模型在理解图像方面(Chen et al.,2015)的性能如何。Visual Genome 数据集中的场景图片可以被用来作为在图像理解方面模型性能的一种评估方式。生成性的描述和答案可以通过与图像的地面真实场景图进行匹配来对其相应的模型进行评估。
关系提取。关系提取已经在信息检索和自然语言处理领域中被广泛地研究。(Zhou et al.,2007,GuoDong et al.,2005,Culotta and Sorensen,2004,Socher et al.,2012).Visual Genome 数据集是第一个大规模的视觉关系数据集。这个数据集能够被用于图像视觉关系提取(Sadeghi et al.,2015)的研究中,并且对象之间的相互作用也能够被用于行为识别的研究(Yao and Fei-Fei,2010,Ramanathan et al.,2015)以及对象之间的空间定位(Gupta et al.,2009,Prest et al.,2012)的研究中。
语义图像检索。之前的工作已经表明:场景图片能够被用来改善语义图像搜索性能(Johnson et al.,2015,Schuster et al.,2015)。未来新的方法可以用我们的区域描述与区域图片相结合来进行探测。基于注意力(Attention-based)的搜索方法也能够通过由查询指定的并且也定位在检索到的图像中的感兴趣区域来进行探测。
5.结论
Visual Genome 数据集提供了一个多层次的图片理解,基于此,也能基于多角度对一幅图像进行研究。从像素级信息(如对象),到要求进一步推导的关系模型,甚至到更深层次的认知任务(如 视觉问答)。从模型的训练和定立下一代计算机视觉模型基准两方面来说,Visual Genome 是一个全面的数据集,我们希望这些模型能够建立一个对我们视觉世界更广泛的理解。完善检测对象的计算机能力,并且这些被检测的对象要同时兼顾能够描述那些对象以及解释对象之间的相互作用和关系的能力。对于视觉理解和一个更加完整的描述集以及基于视觉概念到语言的视觉问答模型来说,Visual Genome 数据集是一个大型的形式化的知识表述。
转载自:后 ImageNet 时代:李飞飞视觉基因组重磅计划,新一轮竞赛!
其实转载这篇文章是因为感觉Visual Genome蛮不错的。