fbprophet
fbprophet是facebook开源的的一个时间序列预测算法,能够几乎全自动地预测时间序列未来地走势。它是基于时间序列分解和机器学习的拟合来做的,其中在拟合模型的时候使用pyStan这个开源库,因此能够在较快时间内得到需要预测的结果。
优点很多,但是在windows下安装有点坑,推荐使用conda安装。我这里是在Google Drive Notebook演示(其自带fbprophet)。
时间序列建模的加和模型
时间序列是日常生活中其中一种最常见的数据类型。金融市场的价格、天气、家庭耗能、甚至体重都是可以定期收集数据的例子。几乎每个数据科学家都会在日常工作中碰到时间序列,而学习如何为时间序列建模是数据科学中重要的技能。
用以分析和预测周期数据的加和模型便是一种简单但强大的模型。背后直观的概念是:把时间序列分成不同时间间隔和整体趋势的组合,间隔可以是每天、每周、每季度、每年。你的家也许在夏天比懂冬天耗能,但整体上因为更有效率的能源使用呈递减趋势。加和模型能够展现出规律/趋势并根据这些观察作出预测。
以下的图展示一个时间序列分解成整体趋势、年趋势还有周趋势。

准备数据
通常,一个数据科学的项目有大约 80%的时间花在获取和清洗数据上。本项目中,Quandl 库可以将这个工作量减少到 5%左右。Quandl 可以在命令行中通过 pip 命令安装:
pip install quandl
Quandl 是免费的,你可以每天提出 50 个访问请求而无需注册。如果注册一个免费的帐户,你会得到一个 API 密钥,允许无限制次数的请求。
首先,引入所需的库并获取数据。Quandl 中的数据几乎是无限的,但我想集中比较同行业中的两家公司,即特斯拉和通用汽车。特斯拉是一个引人注目的公司,不仅因为它是 111 年以来美国第一个成功的汽车创业公司,它也是 2017 年美国最值钱的汽车公司。它的竞争者是通用汽车,通用汽车最近已经通过制造一些非常酷的全电动车来展现拥抱未来汽车的迹象。
我们可以通过一句简单的 quandl 命令来获得两家公司的每日股票市值:
# quandl for financial data import quandl # pandas for data manipulation import pandas as pd quandl.ApiConfig.api_key = 'getyourownkey!' # Retrieve TSLA data from Quandl tesla = quandl.get('WIKI/TSLA') # Retrieve the GM data from Quandl gm = quandl.get('WIKI/GM') gm.head(5)

Quandly 自动将数据放入 Pandas 数据框(DataFrame)中,DataFrame 是数据科学家的首选数据类型。(对于其他公司,只需用「TSLA」或「GM」替换股票代码,你也可以指定日期范围)
数据探索
在建模之前,最好先了解一下数据的结构和范围。这也将有助于找出需要纠正的异常值或缺失值。
Pandas dataframe 可以很容易地用内置方法绘图:
# The adjusted close accounts for stock splits, so that is what we should graph plt.plot(gm.index, gm['Adj. Close']) plt.title('GM Stock Price') plt.ylabel('Price ($)'); plt.show() plt.plot(tesla.index, tesla['Adj. Close'], 'r') plt.title('Tesla Stock Price') plt.ylabel('Price ($)'); plt.show();

仅仅比较这两家公司的股票价格,并没有显示出哪个更有价值,因为公司的总市值也取决于股票数量(市值=股价*数量)。Quandl 没有免费的股票数量数据,但是我找到了两家公司的平均年度股票数。这是不精确的,但是对我们的分析来说足够准确。有时我们不得不使用不完善的数据!
在这里,我们使用 Pandas 的一些技巧,如改变列的索引(reset_index)、使用 loc 命令添加索引和更改 dataframe 中的值。
# Yearly average number of shares outstanding for Tesla and GM tesla_shares = {2018: 168e6, 2017: 162e6, 2016: 144e6, 2015: 128e6, 2014: 125e6, 2013: 119e6, 2012: 107e6, 2011: 100e6, 2010: 51e6} gm_shares = {2018: 1.42e9, 2017: 1.50e9, 2016: 1.54e9, 2015: 1.59e9, 2014: 1.61e9, 2013: 1.39e9, 2012: 1.57e9, 2011: 1.54e9, 2010:1.50e9} # Create a year column tesla['Year'] = tesla.index.year # Take Dates from index and move to Date column tesla.reset_index(level=0, inplace = True) tesla['cap'] = 0 # Calculate market cap for all years for i, year in enumerate(tesla['Year']): # Retrieve the shares for the year shares = tesla_shares.get(year) # Update the cap column to shares times the price tesla.loc[i, 'cap'] = shares * tesla.loc[i, 'Adj. Close']
这为特斯拉创建了名为「cap」的列。我们对通用汽车数据进行同样的处理,然后将两者关联(merge)。关联实质上是数据科学工作流的一部分,因为它允许我们在共享列的基础上合并不同的数据集。在这种情况下,该列是日期。我们进行「inner」关联,只保存两个数据框中有相同日期的数据行。
# Merge the two datasets and rename the columns cars = gm.merge(tesla, how='inner', on='Date') cars.rename(columns={'cap_x': 'gm_cap', 'cap_y': 'tesla_cap'}, inplace=True) # Select only the relevant columns cars = cars.ix[:, ['Date', 'gm_cap', 'tesla_cap']] # Divide to get market cap in billions of dollars cars['gm_cap'] = cars['gm_cap'] / 1e9 cars['tesla_cap'] = cars['tesla_cap'] / 1e9 cars.head()

市值的单位为十亿美元。我们可以看到,开始时通用汽车的市场份额超过特斯拉 30 倍。随着时间推移,事情会保持不变吗?

我们观察到特斯拉的急剧上升以及通用汽车在期间的小幅上涨。特斯拉在 2017 年甚至超过了通用汽车!
import numpy as np # Find the first and last time Tesla was valued higher than GM first_date = cars.loc[np.min(list(np.where(cars['tesla_cap'] > cars['gm_cap'])[0])), 'Date'] last_date = cars.loc[np.max(list(np.where(cars['tesla_cap'] > cars['gm_cap'])[0])), 'Date'] print("Tesla was valued higher than GM from {} to {}.".format(first_date.date(), last_date.date())) Tesla was valued higher than GM from 2017-04-10 to 2017-09-21.
在此期间,特斯拉销售约 4.8 万辆汽车,而通用汽车售出 150 万辆。即使销售了 30 多倍汽车,通用汽车的价值仍低于特斯拉。这绝对显示了有号召力的执行官和高质量的产品(如果极低产量)的力量。尽管特斯拉的价值现在低于通用汽车,但是一个好问题可能是,我们可以预测特斯拉再次超越通用汽车吗?什么时候会发生?为此,我们转向预测加法模型,预测未来。
用 Prophet 建模
Prophet 设计目的是用日常观测数据分析时间序列,这些数据在不同尺度衡量下具有模式规律。它同时对建模节日效应的时间序列和添加人工变化点(changepoint)有出色的能力,但在本文中我们将仅运用基本功能来建模和运行。
我们首先引入 prophet,并将我们数据中的列重新命名为正确的格式。日期列必须被称为「ds」,数值列被称为「y」。在这里,数值列是市值。然后,我们创建 prophet 模型并传入数据训练,就像 Scikit-Learn 机器学习模型一样:
import fbprophet # Prophet requires columns ds (Date) and y (value) gm = gm.rename(columns={'Date': 'ds', 'cap': 'y'}) # Put market cap in billions gm['y'] = gm['y'] / 1e9 # Make the prophet model and fit on the data gm_prophet = fbprophet.Prophet(changepoint_prior_scale=0.15) gm_prophet.fit(gm)
创建 prophet 模型时,我将 changepoint 先验设置为 0.15,高于默认值 0.05。这个超参数用于控制趋势对变化的敏感程度,数值越高越敏感,数值越低越不敏感。这个数值用于权衡机器学习中最基本的一对统计量:偏差(bias)与方差(variance)。
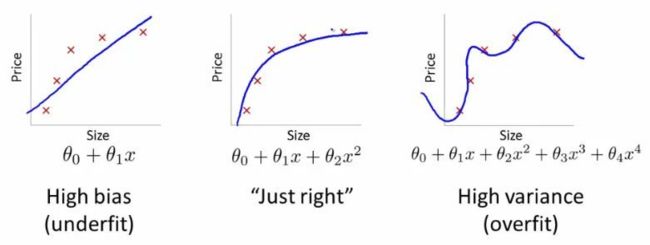
过拟合和欠拟合都是我们不愿看见的。
在创建一个 prophet 模型中,我们也可以指定变化点,如时间,当希望序列从上升到下降趋势时,反之亦然;如节日,当希望影响时间序列时。如果我们不指定变化点,prophet 会为我们计算它们。
为了进行预测,我们需要用 prophet 模型创建所谓的用于预测的未来数据框。我们指定预测的未来时期区间(两年)和预测的频率(每天)。
# Make a future dataframe for 2 years gm_forecast = gm_prophet.make_future_dataframe(periods=365 * 2, freq='D') # Make predictions gm_forecast = gm_prophet.predict(gm_forecast)
我们的未来数据框包含未来两年特斯拉和通用汽车的估计市值。我们可以用 prophet 的绘图函数来可视化预测。
gm_prophet.plot(gm_forecast, xlabel = 'Date', ylabel = 'Market Cap (billions $)') plt.title('Market Cap of GM');

黑点代表实际值(注意实际值测量截止到 2018 年初),蓝线表示预测值,淡蓝色阴影区域表示不确定性(这是预测的关键部分)。未来时间距离越远,不确定性区域越大,因为初始的不确定性随着时间的推移而增长。在天气预报中也观察到这种情况,时间越远天气预报越不准确。
我们也可以检查模型检测出的 changepoints。重申一点,changepoints 代表的是当时间序列的增速有明显变化的时候(例如从增到减)。
tesla_prophet.changepoints[:10]
61 2010-09-24
122 2010-12-21
182 2011-03-18
243 2011-06-15
304 2011-09-12
365 2011-12-07
425 2012-03-06
486 2012-06-01
547 2012-08-28
608 2012-11-27
我们可以对比一下这个时间段从谷歌搜索到的特斯拉趋势看看结果是否一致。changepoints(垂直线)和搜索结果放在同一个图中:
# 加载数据 tesla_search = pd.read_csv('data/tesla_search_terms.csv') # 把月份转换为 datetime tesla_search['Month'] = pd.to_datetime(tesla_search['Month']) tesla_changepoints = [str(date) for date in tesla_prophet.changepoints] # 画出搜索频率 plt.plot(tesla_search['Month'], tesla_search['Search'], label = 'Searches') # 画 changepoints plt.vlines(tesla_changepoints, ymin = 0, ymax= 100, colors = 'r', linewidth=0.6, linestyles = 'dashed', label = 'Changepoints') # 整理绘图 plt.grid('off'); plt.ylabel('Relative Search Freq'); plt.legend() plt.title('Tesla Search Terms and Changepoints');

特斯拉市值的一些 changepoints 跟特斯拉搜索频率的变化一致,但不是全部。我认为谷歌搜索频率不能称为股票变动的好指标。
我们依然需要知道特斯拉的市值什么时候会超越通用汽车。既然有了接下来两年的预测,我们可以合并两个数据框后在同一幅图中画出两个公司的市值。合并之前,列需要更名方便追踪。
gm_names = ['gm_%s' % column for column in gm_forecast.columns] tesla_names = ['tesla_%s' % column for column in tesla_forecast.columns] # 合并的数据框 merge_gm_forecast = gm_forecast.copy() merge_tesla_forecast = tesla_forecast.copy() # 更名列 merge_gm_forecast.columns = gm_names merge_tesla_forecast.columns = tesla_names # 合并两组数据 forecast = pd.merge(merge_gm_forecast, merge_tesla_forecast, how = 'inner', left_on = 'gm_ds', right_on = 'tesla_ds') # 日期列更名 forecast = forecast.rename(columns={'gm_ds': 'Date'}).drop('tesla_ds', axis=1)
首先我们会只画估算值。估算值(prophet包的 “yhat”)除去一些数据中的噪音因而看着跟原始数据图不太一样。除杂的程度取决于 changepoint prior 的大小 - 高的 prior 值表示更多的模型灵活度和更多的高低起伏。
plt.figure(figsize=(10, 8)) plt.plot(forecast['Date'], forecast['gm_trend'], 'b-') plt.plot(forecast['Date'], forecast['tesla_trend'], 'r-') plt.legend(); plt.xlabel('Date'); plt.ylabel('Market Cap ($)') plt.title('GM vs. Tesla Trend');

plt.figure(figsize=(10, 8)) plt.plot(forecast['Date'], forecast['gm_yhat'], 'b-') plt.plot(forecast['Date'], forecast['tesla_yhat'], 'r-') plt.legend(); plt.xlabel('Date'); plt.ylabel('Market Cap (billions $)') plt.title('GM vs. Tesla Estimate');

overtake_date = min(forecast.ix[forecast['tesla_yhat'] > forecast['gm_yhat'], 'Date']) print('Tesla overtakes GM on {}'.format(overtake_date)) #Tesla overtakes GM on 2018-02-03 00:00:00
当生成以上的图像,我们遗漏了预测中最重要的一点:不确定性!
# Create subplots to set figure size fig, ax = plt.subplots(1, 1, figsize=(10, 8)); # Plot estimate ax.plot(forecast['Date'], forecast['gm_yhat'], label = 'gm prediction'); # Plot uncertainty values ax.fill_between(forecast['Date'].dt.to_pydatetime(), forecast['gm_yhat_upper'], forecast['gm_yhat_lower'], alpha=0.6, edgecolor = 'k'); # Plot estimate and uncertainty for tesla ax.plot(forecast['Date'], forecast['tesla_yhat'], 'r', label = 'tesla prediction'); ax.fill_between(forecast['Date'].dt.to_pydatetime(), forecast['tesla_yhat_upper'], forecast['tesla_yhat_lower'], alpha=0.6, edgecolor = 'k'); plt.legend(); plt.xlabel('Date'); plt.ylabel('Billions $'); plt.title('Market Cap Prediction for GM and Tesla');

这更好代表预测的结果。图中显示两个公司预期会增长,特斯拉的增长速度会比通用更快。再强调一下,不确定性会随着时间的推移而增加,而 2020 年特斯拉的下限比通用的上限高意味着通用可能会一直保持领先地位。
市值分析的最后一步是看整体趋势和规律。预言家让我们轻易地达到这个目的。
# 描绘趋势和规律 gm_prophet.plot_components(gm_forecast)

这个趋势非常明显:通用汽车的股价正在上涨并将继续上涨。年度模式很有意思,因为这似乎揭示了通用汽车的股价在年底会有所增长,但随后会缓慢下滑直到夏季。因此,我们可以尝试计算年度市值与通用汽车在此期间平均每月的销售额之间是否存在相关关系。
对通用的历年来每月销售额的平均值做统计:

年度成分市值统计:

看起来月销量与市值不相关。八月份的月销售额是第二高的,但此时是市值的最低点!
而且,每周趋势没有如预期显示出意义。经济学中的随机游走理论指出,股票价格每天都没有可预测的模式。正如我们的分析所证明的那样,长期来看,股票往往会上涨,但在每日来看,几乎没有我们可以利用的模式。(也就是说对股票的预测都是不靠谱的?)
道琼斯工业平均指数(反映证券交易所 30 家最大公司的市场指数)很简单地说明了这一点:
Prophet 也可以应用于更大规模的数据测量,如国内生产总值(衡量一个国家经济总体规模)。我根据美国和中国的历史 GDP 创建了 prophet 模型并做了以下预测。
总结
有很多方法来模拟时间序列,从简单线性回归到具有 LSTM 的循环神经网络(recurrent neural network)。加法模型是有用的,因为它们可以快速开发和运行,可以解释并预测不确定性。Prophet 的能力令人印象深刻,我们在这里只涉及到基本功能。我鼓励你使用本文和 notebook 来探索 Quandl 提供的一些数据或者利用你自己的时间序列数据。作为探索时间序列的第一步,Python 中的加法模型是必经之路!
原文链接:https://towardsdatascience.com/time-series-analysis-in-python-an-introduction-70d5a5b1d52a
完整代码和数据集:https://github.com/WillKoehrsen/Data-Analysis/blob/master/additive_models/Additive%20Models%20for%20Prediction.ipynb
参考链接:
1. https://cloud.tencent.com/developer/article/1119611
2. https://www.zhihu.com/question/21229371/answer/559468427