补java的坑,开始!
1.Intellij一些快捷键
intell常用快捷键:
ctrl+n 快速查找定位类的位置
ctrl+q 快速查看某个类的文档信息
shift + F6 快速类、变量重命名
ctrl + i 在当前类实现接口的方法
ctrl + o 复写基类的方法
ctrl+shift+空格 推荐适用于当前函数的变量
alt+insert 快速设置类的方法
ctrl+shift+a 快速查找各种类,变量,操作
ctrl+alt+t 自动生成异常捕获块
ctrl+alt+b 定位抽象方法的实现
ctrl+alt+v 反射提取出类的对象
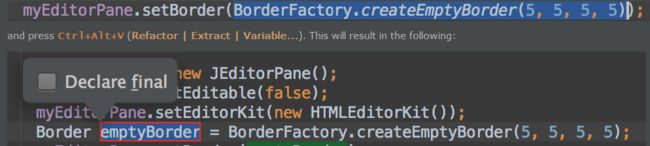
ctrl+/ 注释/取消单行
ctrl+shift+/ 注释多行
shift+F1 浏览器中打开当前元素对应的文档
ctrl+shift+上下箭头可以快速移动当前行到某一行
表达式后面加点.就可以选择要自动添加的条件
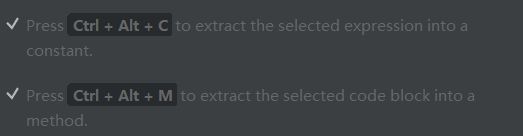
ctrl+shift+m 可以把代码块定义到一个新的方法中,用于代码复用
ctrl+alt+c 用于提取指定变量
ctrl+alt+b 定位到当前接口的实现处
ctrl+alt+l 可以使整个代码界面更整齐,取消单行
ctrl+p 可以提示你当前函数可以用什么参数,以及参数类型,感觉比较有用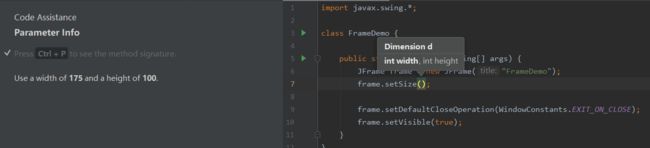
ctrl+shirt+i 可以查看当前方法的具体定义
F2键快速定位到下一个报错的地方
F4可以定位到类的源码处进行分析
ctrl+F12 可以快速分析出当前文件中的结构,包括类、方法、变量
ctrl + f 查找字符串 F3 定位到下一个匹配的字符串处,shift+f3返回上一个匹配的字符串处
ctrl+shift+enter 快速生成if或for代码块
debug技巧:
https://github.com/guobinhit/intellij-idea-tutorial/blob/master/articles/basic-course/debug-skills.md
2.java的一些基础知识
apache-tomcat-7.0.34\webapps下默认是部署的Web项目。webapps 下的文件夹就是你的项目名了,而项目下的WebRoot一般就是网站的根目录了,WebRoot下的文件夹WEB-INF默认是不让Web访问的,一般存在配置泄漏多半是nginx配置没有过滤掉这个目录。
关于java数组对象的文章:
https://blog.csdn.net/zhangjg_blog/article/details/16116613#t1
java虚拟机自动创建了数组类型,可以把数组类型和8种基本数据类型一样, 当做java的内建类型。这种类型的命名规则是这样的
* 每一维度用一个[表示;开头两个[,就代表是二维数组。
* [后面是数组中元素的类型(包括基本数据类型和引用数据类型)
讲得很好,java数组也是对象,对象在计算机中实际上就是一个内存块,这个内存块中存储着该对象的属性等数据,对于基本类型而言

对于基本类型的数组可以通过调用getclass方法来获得其对应的类的名字,而直接定义的基本数据类型无法调用方法,因此数组为对象,而对于基本数据类型,java中向上转型不适合,

例如上图这种方式的数组转型是不适合基本数据类型的,只能够使用:

因为所有的对象的顶层的类均为object,但是对于string可以使用object[]来进行向上转型,

并且此时sting[]类型的直接父类为object,而不是为object[],但是java是单继承的,即此时可以理解为object[]类型的引用可以指向string[]对象的引用,即string[]不继承自object[],但是却可以向上转型为object[],即这是java中的一种特例。
![]()
序列化
反序列化漏洞的本质就是反序列化机制打破了数据和对象的边界,导致攻击者注入的恶意序列化数据在反序列化过程中被还原成对象,控制了对象就可能在目标系统上面执行攻击代码。Java序列化应用于RMI JMX JMS(Java Message Service) 技术中。
Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。
一个类的对象要想序列化成功,必须满足两个条件:
该类必须实现 java.io.Serializable 对象。
该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
检验一个类的实例是否能序列化十分简单, 只需要查看该类有没有实现 java.io.Serializable接口。
实现Serializable和Externalizable接口的类的对象才能被序列化。
Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以采用默认的序列化方式 。
ObjectOutputStream 类用来序列化一个对象
ObjectInputStream类用来反序列化一个对象
以下是最简单的序列化和反序列化的过程,通过ObjectOutStream的writeObject来将对象写入到文件中,通过ObjectInputStream的readObject来读取文件中序列化的对像,这里反序列化的时候原始的对象是Object,要用(类名)转换成对应类的对象才能恢复序列化的对象
import java.io.FileOutputStream; import java.io.ObjectOutputStream; import java.io.*; public class xuliehua implements Serializable{ public static String a="a"; public static void main(String[] args) { xuliehua test = new xuliehua(); try { ObjectOutputStream t = new ObjectOutputStream(new FileOutputStream("./xuliehua")); t.writeObject(test); t.close(); ObjectInputStream tt = new ObjectInputStream(new FileInputStream("xuliehua")); xuliehua x = (xuliehua) tt.readObject(); System.out.println(x.a); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
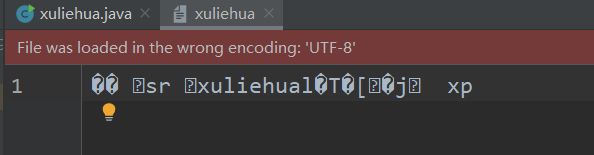
java生成的序列化数据是字节序列,base64一下更易读
自定义序列化和反序列化过程,就是重写writeObject和readObject方法
import java.io.FileOutputStream; import java.io.ObjectOutputStream; import java.io.*; public class xuliehua implements Serializable{ public static String a="a"; private void readObject(ObjectInputStream in) { try { in.defaultReadObject(); Runtime.getRuntime().exec("calc.exe"); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } public static void main(String[] args) { xuliehua test = new xuliehua(); try { ObjectOutputStream t = new ObjectOutputStream(new FileOutputStream("./xuliehua")); t.writeObject(test); t.close(); ObjectInputStream tt = new ObjectInputStream(new FileInputStream("xuliehua")); xuliehua x = (xuliehua)tt.readObject(); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
运行以上代码即可弹出计算器,这里实际上利用了java多态特性的重写,重写readObject方法,其中红色的一行Runtime.getRuntime.exec即自定义的执行命令的语句,而大部分Java反序列化漏洞的原理就是某个类重写了readObject方法
java反射机制:
程序在运行状态中, 可以动态加载一个只有名称的类, 对于任意一个已经加载的类,都能够知道这个类的所有属性和方法; 对于任意一个对象,都能调用他的任意一个方法和属性;
加载完类之后, 在堆内存中会产生一个Class类型的对象(一个类只有一个Class对象), 这个对象包含了完整的类的结构信息,而且这个Class对象就像一面镜子,透过这个镜子看到类的结构,所以被称之为:反射
每个类被加载进入内存之后,系统就会为该类生成一个对应的java.lang.Class对象,通过该Class对象就可以访问到JVM中的这个类.
Class对象的获取方法:
实例对象的getClass()方法;
类的.class(最安全/性能最好)属性;
运用Class.forName(String className)动态加载类,className需要是类的全限定名(最常用).
注意,使用功能”.class”来创建Class对象的引用时,不会自动初始化该Class对象,使用forName()会自动初始化该Class对象
import java.awt.desktop.SystemEventListener; import java.io.*; import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; public class reflection { public static void main(String[] args) { Class test = Test.class; //此时通过.class创建类test的引用 System.out.println("恢复"+test.getName()); Method[] methods = test.getMethods(); //通过Class类型的对象来访问test类的所有方法 for (Method method : methods) { System.out.println("method =>"+method.getName()); } try { Method method= test.getMethod("hack",String.class); //通过class类型的对象的getMethod方法来访问该反射类中的方法,第二个参数为该方法的类型,此处为string型 Object x = method.invoke(new Test("tr1ple"),"23333"); //通过Method类型的method变量来调用invoke来调用getmthod已经定位到的方法,此时第一个参数为反射类的一个实例化对象,
第二个参数为该方法的入口参数 System.out.println(x); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } catch (NoSuchMethodException e) { e.printStackTrace(); } } } class Test { private String a; public Test(String a) { this.a=a; } public String hack(String b) { try { System.out.println("tet"+this.a+"and "+ b); Runtime.getRuntime().exec("calc.exe"); } catch (IOException e) { e.printStackTrace(); } return b; } }
即整个反射链的实际调用情况为:
1.TEST.class获得类的class类型对象,便于访问TEST类内部结构
2.通过类对象->getmethod()来定位需要调用的方法
3.通过Method类型的变量调用invoke方法来进行反射,完成最终反射调用函数的触发
对象创建的几种方法:
1.使用new关键字 2.使用clone方法 3.反射机制 4.反序列化
其中1,3都会明确的显式的调用构造函数
2是在内存上对已有对象的影印 所以不会调用构造函数
4是从文件中还原类的对象 也不会调用构造函数