大纲
应用简介
人脸检测
人脸识别
通用目标检测
图像分割
风格迁移
总结
讲述CNN典型应用,主要是在机器视觉领域里边,这是它应用最广的一个领域,包含下边几个应用:人脸识别;人脸检测;通用目标检测;图像分割;风格迁移。
检测、分类、分割基本上已经涵盖了图像理解的整体上要完成的一个目标,我们对所有图像的理解无非就是这三类问题:图像分类(判断一个图像它是什么)、目标检测(找出图像里边所有的目标,包括它的大小和位置)、图像分割(确定每个像素它属于哪一个目标)。
卷积神经网络应用简介
先简单介绍一下CNN的应用情况。它最早是应用在机器视觉/图像领域里边的,更具体来说,是用来做图像分类的,1989年,Yanlecun的第一篇CNN的文章和后边的LeNet5它都是用来做手写字符识别的,就是图像分类问题,后边它逐步地被用到其他领域,包括NLP(比如文本分类、机器翻译等),还有图形学问题(它研究的就是怎样用计算机来画出图像来,尤其是来生成这种比较真实的图像)。其实不要把思维局限在图像这个领域,只要是基于这种空间结构的数据,比如说二维三维甚至更高维的,我们都可以用CNN来对它进行处理,也就是说CNN它最适合处理的就是这种空间结构的数据。
在所有的深度神经网路DNN里边,CNN它是变换种类最多的,各种花样层出不穷,为什么呢?因为他要解决很多的实际问题,针对这些问题,我们要设计专门的一些CNN,比如说做检测、图像分割,如果还用标准的CNN比如说像输入层、卷积层、池化层以及全连接层等这样的网络,你用来做图像分割就不适合了,因为图像分割它要预测输入图像里边每个像素点它所代表的类型是什么,比如说这一块是人这一块是一个自行车,需要把每个像素的类别预测出来,用一个标准的CNN肯定是做不到的,因为它最后的输出就是一个向量值,不能还原出一个每一个像素点它所代表的类别,因此就发明了像全卷积神经网路FCN这样的结构。因此为了解决各种复杂的实际问题设计了一些专门的网络结构,包括损失函数,其实损失函数和网络结构它们两个是密切相关的,很多时候我们的网络结构就决定了我们的损失函数应该定义成什么样子,而我们的损失函数也可以用来指导我们设计出一个什么样的网络来。损失函数实际上是和我们要完成的目标是息息相关的,比如说是要判断每个像素的类别还是要找出图像中所有物体出现的位置和大小等等,根据不同的目标,我们可以设定不同的损失函数。因此理解这些改进的神经网路它的关键点有两个,第一个是要理解网络的结构,这些网络包括哪些层,然后他们的连接关系是什么样子的,每一层它的作用是什么,比如这一层是用来提取特征的下一层是用来做图像放大的等等各种用途,所以说我们要搞清楚每一个层它的输入数据是什么东西输出数据是什么东西,这也是和它的作用密切相关的。第二点就是训练的目标也就是我们的损失函数是怎么构造出来的,前边说了,损失函数的构造,它和网络的结构是密切相关的,它是直接与我们要完成的任务确定的,你确定什么样的问题,就要定义和它相符合的损失函数。
人脸检测简介
人脸检测是标准的目标检测问题,它的目标就是找出人脸在图像里边出现的所有位置和大小,人脸可能出现在图像里边所有的可能位置。但是人脸可能有不同的大小,另外人脸可能有不同的姿态,比如倾斜、旋转等等各种角度,还有它有不同的表情、遮挡等不同的问题存在,因此导致这个问题非常不好解决。其实这也是所有目标检测问题所面临的一个通用的挑战。人脸检测是怎么做的呢?其实可以把它看成一个分类问题二分类问题,就是把所有的地方都找一遍,就是从左往右从上往下用一个固定大小的区域把它框出来,就像用一个放大镜一样,把某一块裁出来看一下是否是人脸,因此就是回答一个Yes或No的问题即二分类问题,这其实是一种暴力破解的方式,找到所有可能的位置,找到了位置以后接下来就是一个二分类问题,回答这个区域它是人脸还是不是人脸,做这样一个判断。人脸检测,它是整个机器视觉里边非常重要的一个问题,因为它有一个强的使用价值,另外它学术研究的价值也非常强,而且相对于其他的一些目标检测来说它还是算简单一些的了,比如说行人检测,它是更复杂的,因为行人的姿态变化各种情况会更多一些遮挡会更多一些,而人脸算简单一些的问题。而人脸在我们很多场景里边会经常出现的,因为日常生活中非常关心人的脸这样一个问题,因此它非常重要。
实际上CNN在1990年代就用来做人脸检测了,但是长期以来没有得到一个很大的突破,第一次真正意义上的突破是在200年的时候,VJ提出的一个用人工特征(准确的说是Haar特征)+级联的Adaboost分类器+滑动窗口(即从左往右从上往下滑,依次找这个固定大小区域里边它是人脸还是不是人脸)的方案,这是人脸检测历史上第一次有里程碑意义的突破,这个框架后来就是长时间被工业界和学术界所用的,它的优点就是用这种级联的AdaBoost分类器方案,它非常省时间,它的原理就是用多个分类器联合判断这个区域是人脸函数不是人脸。因为人脸在图像里面出现它是一个很稀疏的小概率事件,就是出现的概率非常小,因此我们用一个非常简单的分类器,把大部分一看就不是人脸的区域给排除掉,这样就能减少工作量,因为人肉眼一瞥,瞥一眼就能看出这不是人脸,就不用细看了,这样就把大部分不是人脸的东西给筛掉了,最后能留下来的这些区域,在接下来再做一次判断,用第二级分类器来判断,第二级分类器比第一级更精细一些更准确一些,如果通过的话就接着往下走,一直到通过了所有级的分类器以后,就判定为是一个人脸,否则被任意一级分类器丢掉了,都认为不是人脸,它就是这样做的,这就是分类器级联的方案。这种方法看上去很简单,但是它极大的提高了人脸检测的速度,因为我们如果要采用这种暴力破解的方式滑窗、缩放图像、固定窗口大小的方式来判断是否是人脸,用这种滑动窗口的技术做人脸检测,运算量是相当大的,速度是非常慢的,而VJ框架这种方法很巧妙的用一些简单的分类器把大部分不是人脸的区域给排除掉了,这样就大大节约了时间、精度也非常高,比之间的方法要好一些,因此它被得到大规模的使用,以前数码相机人脸对焦都是使用这种VJ框架实现的。人脸检测,它有两个指标,它和所有的目标检测问题是一样的,第一个检测率,就是算法它检测出来的数据Nd比上真实的目标数N,误报率就是被错误的判断为人脸数除以负样本的总数即不是人脸的所有的区域。我们要追求的目标是检测率要高误报率要低,另外还有速度上的要求,就是算法要尽量的快。
人脸而分类器
前边已经说了,最终是把问题转化为一个二分类问题,就是用一个固定大小的窗口去框区域,把一个区域裁出来判断它是人脸还是不是人脸,这是怎么做的呢?
这就需要我们训练一个分类器用于判断一个固定大小的区域它是否是人脸,怎么训练的呢?就是用大量人脸的正样本比如十万个人脸和一千万个非人脸的这样的样本来训练二分类模型,得到这样一个模型以后,接下来给一张图像以后,我们就可以判断它是人脸还是不是人脸,这就是一个整体的思路。

滑动窗口技术
滑动窗口技术是怎么做的呢?
因为我们要找出所有的人脸,它可能出现在所有的位置上,那么我们就用一个固定大小的窗口,比如说64*64像素的,在图像上面滑,从左往右从上往下,然后来判断框住这快区域它是人脸还是不是人脸,这是一个二分类问题,前边说了,我们训练一个二分类器就可以解决这个问题,这是解决了找人脸的所有位置的问题,但是还有一个问题没有解决,就是要检测不同大小的人脸,比如近大远小,一般是训练一个能检测最小的人脸的分类器,比如说64*64像素的人脸分类器,只能判断64*64大小的人脸,如果想判断更大的人脸,只需缩放即可用该分类器判断,这就是图像的金字塔技术,就是把图像反复的缩小,比如说把图像缩小以一定的比例缩小,如1.1,不断地除以1.1,反复缩小图像,这样就把图像中大的人脸经过很多级缩小以后缩成小的人脸,这样就能用64*64的窗口把它检测出来,金字塔技术加上滑动窗口技术方案。
我们的原始的检测结果会是什么样子呢?它在人脸区域周围检测出很多框出来,它都把这些地方来判断为人脸,因为这些地方都是人脸,只是偏了几个像素而已。最后还要做一个非最大抑制,合并去重,把属于同一个人脸的这些矩形给合并掉,合并掉以后就只剩下一个干净的矩形框来表示这个人脸,这就叫非最大抑制NMS。
分类器级联
分类器级联主要来解决速度问题,即计算量太大而达不到实时的问题。由于人脸在图像中出现是一个小概率事件,用简单分类器快速把不是人脸的大部分窗口排除掉,这就能简化我们的计算过程,级联的分类器就是这样做的。判断每一个窗口它是人脸还是不是人脸的时候,它不是用一个二分类器来判断Yes还是No,而是用了很多个分类器集合起来使用的。第一个分类器它非常简单,比如只用一个if-else就可以判断出它是否是人脸来,如果通过了就用第二个分类器来更细致的判断它是否是人脸,第二个分类器可能比第一个复杂点,但是它准确率会更高一些,如果判断不是人脸,就排除掉了,不做其他的判断不再劳烦其他的分类器了,如果通过了再用接下来的分类器判断层层把关,如果所有分类器都认为是人脸的话,最后输出True,被任意一个分类器否定掉就认为不是人脸。它的核心是分类器复杂程度递增,从而不是上来就用复杂分类器来判断,因此就大大的提高了我们的检测效率。

Cascade CNN简介
分类器级联(cascade分类器)以及滑动窗口(sleding window)技术最开始是被adaboost所使用的,人工特征(Haar特征)+AdaBoost集成起来用的,前边讲深度学习概念的时候说了,这种人工设计的特征,它的描述能力是非常有限的,因为它计算非常简单,限定了我们算法所要达到的精度了,因此我们就必须把它干掉,用CNN来自动提取特征。问题又来了,如果是手工提取的,如Haar特征加上AdaBoost,我们可以把各种级联的分类器做的非常简单,比如第一级用一个if-else就可以判断出来了,而CNN,就算是再小,它也要经过卷积、池化、全连接等等一系列运算,还是相当复杂的,因此直接用CNN来做cascade级联的话,其实面临一个速度上的问题,就是它的速度比我们的AdaBoost+Haar/HoG特征这样的更慢一些,因此直接的用CNN来暴力的这样做的话肯定是不行的,所以说它也要采用这种级联的分类器来做,就是用多个CNN来做,第一个CNN1,计算量小,用来排除那些一看就不是人脸的区域,通过CNN1后再送到第二个CNN2,又把大部分排除掉了,再送到第三个网络CNN3中去,CNN3可能又把大部分排除了,如果CNN3认为是人脸了,那最终就判定为是人脸。但是它也是级联,在速度比Haar+Adaboost这样的方案慢很多,主要原因是它采用了滑动窗口暴力破解技术,要检测所有的位置和所有大小的图像。
第一篇CNN+滑动窗口技术来解决人脸分类问题的是2015年的一篇文章:
Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, Gang Hua. A convolutional neural network cascade for face detection. 2015, computer vision and pattern recognition.
这篇文章采用了3级卷积网络,CNN1、CNN2、CNN3联合起来检测,CNN1最简单,后边的越复杂,接收的图像尺寸也是不一样的,第一个接收的是一个非常小的图像的输入,第二个可能会大一点,第三个会更大一些。
第一级网络结构简单,计算量小,用于快速排除大量的非人脸窗口。如果窗口图像通过了所有3级网络,则被认为是人脸。
这篇文章有一个创新之处,它除了判断图像是否是人脸外,它还训练了另外一组神经网路,做位置矫正的,做滑窗找出的人脸位置可能不是很正稍偏,大小、位置都有点偏,校正把位置调到真正的人脸上去。
接下来看它的整体结构。
检测算法的流程

经过三次检测、三次校准、三级最大抑制。
检测网络的结构
检测网络用于区分候选区域即窗口图像是人脸还是背景,是一个二分类器网络。

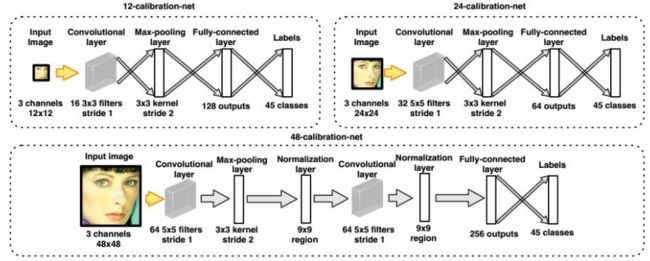
这里有三级网络,分别接收12*12的输入、24*24的输入、48*48的输入,它们的输入都是RGB图像,大图像进行缩放输入判断就可以了,这三个CNN,一个比一个复杂,第一个最简单,有一个卷积层,是16个3*3的三通道卷积核,接着是3*3的池化层,然后接了一个全连接层,最后是输出层,输出结果是人脸还是不是人脸的概率分别是多大。第三个稍微复杂一点,有两个卷积层、两个池化层、还有归一化层、最后是全连接层,这里它采用了一个技巧就是提取这个图像在多尺度上的信息,因为人脸它缩放到不同的大小的时候它所提取出来的信息是不一样的,因此这个网络它除了把48*48图像通过上边这些层处理以后,还把48*48的图像缩放到24*24的大小,然后接了一个24*24网络结构,把它的全连接层和48*48的全连接层拼接起来形成一个更长的一个向量,最后送到输出层里边去输出一下,得到是人脸还是不是人脸的概率有多大。
校准网络的结构
说完了检测网络,接下来说校准网络它是怎么做的,它是把所有可能的校准分成了45种情况,比如下图将红色框校准成蓝色框,他要做平移、高度宽度调整一下。45种情况包括向左调、向右调、宽度缩小、宽度放大等等。

这个网络接收的输入是偏离的人脸图像也可能是正的,输出是正的人脸图像,它也有三级,分别接收12*12、24*24、48*48的输入图像,这些输入图像都可能是偏的,最后根据这些图像算出来一个结果,就是要把它往哪个方向去调。
看它是怎么调怎么校准的?
校准方式:
![]()
前边的是那些x、y是偏了的人脸坐标,w、h是偏了的矩形框的宽度和高度,算出来以后的结果是校正后的x、y、w、h,xn、yn、sn都代表着校正方式,xn表示在x方向平移多少个像素,yn表示在y方向平移多少个像素,sn表示它的尺度是缩小一点还是放大一点,xn、yn、sn这三个参数组合起来一共有45种情况,xn、yn各三种情况,sn有15种情况,这三个参数采用离散值量化,组合起来有45种校正情况。
校正网络要根据输入图像判断应该用这45种方式中的哪一种进行校正,这是一个多分类问题。由于各种校正情况之间并不严格互斥,为了提高精度采用了取平均的方式,比如按第一种方式调整之后乘以0.9概率值,第二种调整方式调整之后乘以0.1概率值,把结果叠加起来得到最后的一个调整结果。
训练算法的流程
前边已经说了整个网络的结构,包括检测时候的算法的流程,接下来我们回答最后一个问题:这个网络它是怎么训练出来的?
训练时需要解决对3个检测网络及3个校准网络的训练,检测网络好说,就拿正样本人脸、负样本不是人脸来训练就可以了,关键是校准网络它的样本怎么生成一会再说。另外还要确定两级级联阈值,因为第一级网络它判定为是人脸还是不是人脸以后,还要对它的结果做一个稍微的调整以便送到第二级里边去处理,不是说它判定为不是人脸就把它丢掉,它有个概率值的,就是这个级联阈值,这个和AdaBoost级联阈值一回事,就是把分类器F(x)的输出结果加上Σ再来判定一下。
首先说检测网络是怎么训练的,检测网络非常简单,它和我们之前的AdaBoost级联分类器的训练是一样的,它是采用每一级分别进行训练的,它是把人脸图像作为正样本,正样本是从AFLW中取出来的样本标注好位置把它裁出来作为正样本,把一些背景图像作为负样本来训练每一级分类器。注意这三级检测网络,它的正样本都是从AFLW中做出来的正样本,负样本是有所不同的,负样本是怎么做的呢?第一级的负样本很简单,就拿所有背景图像做负样本来训练所有AFLW样本为正样本来训练,训练完以后,紧接着要确定一个阈值,这个阈值是怎么确定的呢?就是要保证正样本有99%的检测率,把三级网络对于所有正样本的预测输出结果即是人脸的概率按照从大到小进行排序,前99%都要通过即大于这个阈值就判断为是人脸,注意训练之前要把所有的图像缩放到12*12的大小送到CNN里面去训练,正样本是整个AFLW里边的样本,负样本是从背景图像里边随机选出来的20万张样本,这样我们就把第一个网络训练出来了,并把级联阈值给算出来了(即卡到99%时的值就设定为阈值)。
紧接着训练第2级检测网络,怎么训练呢?还是拿所有的AFLW的样本作为正样本,负样本是有讲究的,它这时候是怎么收集负样本的呢?它是先拿第一级检测网络和校正网络对背景进行扫描,把被第一级网络判定为人脸的那些背景作为负样本来训第二级检测网络,这和AdaBoost类似,重点关注前边分类器错判的那些样本,这时候所有的样本都要缩放到24*24的大小训练第2级网络。训练好之后,用同样的方式确定它的级联阈值,保证它有97%的检测率,即把所有的正样本按照它的预测结果概率p从大到小排序在97%的位置,预测结果小于该阈值的则认为不是人脸,大于该阈值的认为是人脸。
紧接着再训练第3级检测网络,它是把第2级检测网络和校准网络找出来那些不是人脸的虚景背景图像拿来做负样本来训练。说完检测网络的训练,再来说一下校准网络,校准网络它的训练样本是偏了的人脸图像,就拿AFLW人脸按45种方式随机扰动一下,截一个偏一点的人脸图像作为样本,拿到网络里边来训练,这样就把我们的校正网络给训练出来了。
到这里为止,我们就完成了整个网络的训练,注意它的检测网络是一级一级这样训练的,然后每一级是重点关注被前一级错判的那些样本即虚景做负样本,然后校准网络是用随机扰动的那些样本来训练的,阈值是通过卡检测率如99%通过正样本来找出它多大。
检测结果
cascade CNN在FDDB上边的检测结果,官网上的ROC曲线,cascade CNN它的ROC曲线是比之前的AdaBoost这样的算法的ROC曲线高了很多、性能改善是非常明显的,作者给出了一些例子就是在这些图像的检测效果,图像模糊、有遮挡、各种复杂姿态,这个比之前的人工特征+AdaBoost那套算法要强太多太多了。

DenseBox简介
Lichao Huang, Yi Yang, Yafeng Deng, Yinan Yu. DenseBox: Unifying Landmark Localization with End to End Object Detection. 2015, arXiv: Computer Vision and Pattern Recognition.
使用全卷积网络,在同一个网络中直接预测目标矩形框和目标类别置信度,通过在检测的同时进行关键点定位,进一步提高了检测精度。
上面介绍完了CascadeCNN,接下来介绍第二种算法叫DenseBox,这里是百度在2015年提出来的,当时的效果是非常好的。
CascadeCNN还是采用的滑动窗口的技术,即用一个小窗口从左往右从上往下滑,卷积神经网络作用于这个小窗口图像。然后判断这一块图像它是人脸还是不是人脸,就回答一个yes或no问题。这个运算量是非常大的,因为我们的卷积神经网络要从左往右从上往下依次滑,而且还要把图像缩成不同的尺寸都去这样过一遍,这个运算量的大的惊人。CNN每次只运行在这个小窗口区域对这一块进行计算,判断这个窗口它是人脸还是不是人脸。能不能让神经网络作用于整张图像,因为CNN我们可以用gpu来进行并行加速的,前面讲CNN原理的时候已经讲过了,他最后把对整张图像的卷积运算转换成矩阵乘法kx->y,y外就是卷积输出的特征图像featuremap,这个矩阵运算是非常好并行化的,也就是把所有的位置的卷积同时把它做了,所以说如果能对整张图像一次卷积的话是最好的,这是第一个点。
第二个点是前面这种滑动窗口的方案他其实是有很多重复的计算的,比如每次窗口滑动时的交叠区域他的卷积就可能被计算多次,因此这里边大量的重复计算存在,因此说我们就在想,如果能用卷积神经网络通过一次卷积直接把所有位置上是人脸的概率给找出来就好了,这显然是可以达到的,因为我们卷积以后输出的是一个特征图像faturemapFM,FM中的一点代表以该点为中心映射回去,原始图像里边某一块区域他所有的信息都被卷到这一点里面了,原始图像通过多级卷积以后图像FM中一点的感受野是非常大的一片区域,因此我们把图像经过多次卷积和池化变得很小的时候,比如说,512×512的输入图像,最后卷积成32×32的时候,它里边每一个像素点对应512×512图像里边一片很大的区域。
我们想,可以用CNN输出32×32FM中每一点处对应回去512×512处一点以该点为中心的一片区域有人脸出现的概率。DenseBox以及后边要讲的SSD等目标检测算法,他就是这样做的。DenseBox它就是用一个全卷积网络,可以认为这个网络没有全连接层,最后输出的就是一个featuremap的一个图像,这个图像里的每一点,就代表以这点为中心的对应回去的原始图像里面一块大区域它是人脸的概率值,就是他最后得到的这张预测图,它就包含了所有该图一点映射到原图对应区域他是否是人脸的概率以及还包含了一些位置信息、不同宽高比(即FM中该点映射到哪一块区域裁才多大区域出来,以及宽高比是多少呢这是不一定的,即x,y,w,h),这是DenseBox他核心的做法。
这代表着两种不同的流派思想,第一种是CascadeCNN的,这种以滑动窗口为基础的CNN,他的卷积每次作用与图像里边每个小窗口,对该小窗口判断,他是人脸还是不是人脸,第二种就是DenseBox这种的,直接输出一张图像,即对原图像进行一次卷积,输出一张小图像,这张小图像代表原始图像里面每个位置上出现人脸的概率有多少,就是直接把人脸的位置和大小给算出来了,还有他出现的概率给出来了。这是篇论文它还有一个特点是他在做人脸检测的时候,他还做了人脸的关键点定位,这样可以进一步提高检测效率,这也不是什么新的做法了,在之前的文章,比如说JDA,有兴趣可以看一下,这是用AdaBoost做的,它就是同时做人脸检测,就是把人脸框出来,还包括它眼睛的中心鼻尖还有嘴角这五个关键点的定位同时给做了,这同时有利于提高我们检测精度的,因为你要检测这块区域是不是人脸的话,那可以看他这几个那关键点,如果这几个关键点有的话,它可能是个人,如果没有的话就不是个人,所以说人脸的关键点定位和人脸的检测它是相辅相成的,两个综合起来的话是能提高检测的效率的,而这种做法在后面的另一篇文章像MTCNN里面也是有体现的。
检测算法的流程
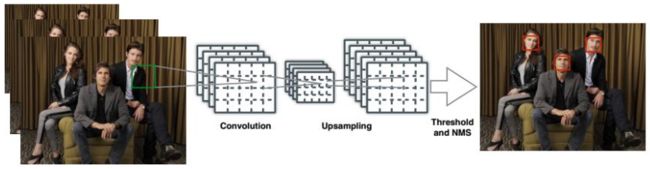
面来看,DenseBox它的检测流程,他首先是对图像做了金字塔缩放。原始图像,按照一定的比例反复把它缩小,得到一些比较小的图像,然后分别把这些图像送到卷积网络里面去处理,这样是为了检测所有不同大小尺寸的人脸,经过一些卷积和池化以后,接下来她做了一个上采样操作,这是因为通过很多层卷积和池化以后,图片会缩的非常小,他做了一个上采样又把图像给变大了,得到一张大一点的图像在这里,然后这张图像又包含了每一点处对应原图像区域出现人脸的概率有多大,以及如果这个人脸出现了的话,他的位置是怎样即该矩阵框它的位置和大小(x,y,w,h),因此后面通过反卷及实现上采样得到的结果图像里边就已经蕴含了任何一个位置上面是否出现目标及出现目标的概率p以及这个目标的位置信息,这样就可以检测出来图像中任何一个地方的人脸。
加上我们对图像做了金字塔缩放,把各个尺度图像分别拿进来进行处理,这样就可以检测不同大小的人脸,这样既解决了人脸的大小问题,又解决了人脸出现在任何一个位置上的问题,因为每个位置他都预测了一个概率,而且还预测出这个位置上面他的人脸如果出现的话,它的矩形框应该在什么地方,做完以后,就得到了很多人脸的候选框,就可以做一个阈值化,这个阈值化就是为了得到候选框而用的,因为我们输出的是一张概率图,实际上不是一张直接的位置(x,y,w,h),而是他们的调整值。
那我们就可以根据这个概率图经过阈值化,就得到所有的人脸,只要这个判定为人脸的概率大于阈值,我们就把这个地方判断为人脸,除了一张概率图外,他还生成另外四张图,分别表示人脸的矩形框w,x,x,y,那就结合这个概率,如果这个概率超过某个值的话,就把该区域对应的另外四个通道图像取出来,把矩形框计算出来,这样得到一些候选框,最后做一个非最大抑制就能得到最后的结果了。
总结一下DenseBox,他的检测流程,其实和后边讲的YOLO、SSD系列是非常像的,他是直接得到目标图像的矩形框,他是怎么做到的呢?他为了检测不同大小的人脸,他把图像做金字塔缩放,分别把每个尺寸头像缩放以后的图像和原始图像分别送到CNN里面去处理,经过一些卷积和池化操作以后,再经过上采样,得到一个输出图像,这个输出图像他有五个通道,其中一个通道,它里边的每一个像素点表示这一点出现目标的概率,对应就是原始图像里面以某一点为中心的区域出现人脸的概率有多大,另外四个通道表示如果这个地方是人脸的话,它的矩形框应该是在什么位置上边x,yz,w,h这些参数,当然,这些参数不是通过回归值直接回归出来的,而是通过一个调整值调整出来的,他预测的是一个调整值。这样就解决了在图像的任何一个地方都出现人脸的这样一个问题,前面的检测不同大小的人脸也出来了,概率图就是来做判断的二分类表示这个地方是人脸还是不是练的概率,而另外四个通道表示了这个人脸在什么地方即w,h,x,y。这相当于做了一个分类和回归,分类就是二分类,表示任何一点处出现人脸的概率,回归就是回归了矩形框的值x,y,w,h他的坐标。
网络结构
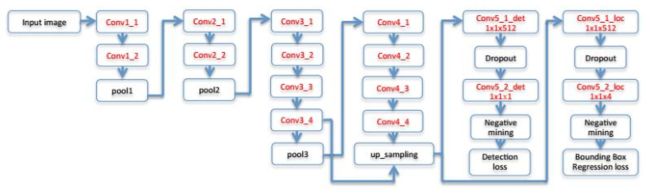
前面我们说完了检测的流程,接下来就收一下它的网络结构。前面说了,他有卷积层、池化层,由VGGNet那样的网络改进的,做完卷积、池化之后,他做了一个上采样,他把前面的那些卷积层结果串起来,把不同尺度上的卷积层结果串起来,为了多分辨的特征提取,这种思路前面已经讲述过了,在CascadeCNN的时候,他也把两个不同大小的卷积网络结果图像拼接起来形成一个大的特征向量。
总之,就是作一些卷积、池化以后再做一次上采样把图像变大一些,得到一张尺寸稍放稍为稍微大一些的卷积图像,对这个图像我们做了两个分支。第一个分支是用来输出任何一点处它出现一个目标的概率值,就是检测。另一个分支是预测,如果这个位置是人脸的话,他的矩形框框在什么地方即x,y,w,h这四个参数,这样的话,它对应的输出图像就是五个通道的图像,第一个通道是概率p,后面四个通道分别表示x,y,w,h,这些坐标以及矩形框的尺寸等这些信息。
相应的,他的输出层有两个分支的话,那损失函数求两个部分构成,第一个部分是分类损失,就是判断任何一点处有没有目标的概率值损失,第二个是目标矩形框的回归损失,要预测这个位置它如果有目标出现的话它的矩形框应该在什么地方,然后训练的时候,这个地方它也会产生一个损失,因此他是使用了一个多目标的损失函数,等会再细讲。
网络的输出数据与损失函数
卷积网络的输出数据:
详细介绍一下,DenseBox这个网络的输出结果,前面我们已经说了,他是去掉了全连接层,他就是经过一些卷积和池化以后,做了一个上采样操作,然后接了两个分支出来,这两个分支接下来进行的也是一些卷积操作,最后得到两组输出的卷积特征图像,一组代表了每个位置上出现一个目标的概率,另外一组他有四个通道,代表如果这个位置上出现一个目标的话,它的矩形框的宽高和位置在什么地方,那么我们就来说他输出的结果,两个分支共输出五个通道的图像,其中有一个通道是置信度得分,代表每个位置是人脸的概率,另外一个分支输出的是四个位置结果w,h,x,y。整个卷积网络,它如果接受m×n的输入图像的话,因为他是一个全卷积网络,所以说他可以接受任意大小的一个输入图像,这个我们后面在讲SPPnet和fastRCN的时候会说的。
我们干掉了全连接层以后,可以保证我们的网络它可以输入任意大小的图像,都可以对他做一些卷积和池化,输出一个和输入图像大小相关的一个输出图像,它的尺寸和输入图像是有关的,比如说把他缩小4倍。这里卷积网络接受m×的输入图像,刚好产生5通道的m/4×n/4输出图像。假设原图像中目标矩形左上角的坐标为(xt, yt),右下角的坐标为(xb, yb),输出图像中位于点(xi, yi)处的像素用5维向量描述了一个目标的矩形框和置信度,第一个分量是候选框是一个目标的置信度,后边4项分别为本像素的位置与矩形框左上角、右下角的距离,该5维向量的计算公式:
![]()
损失函数:
输出层有两个分支,因此损失函数由两部分组成。
第一部分输出值为分类置信度即本位置是一个目标的概率,分类损失函数采用欧氏距离
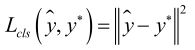
第二部分是矩形框预测误差

总损失函数是这两部分的加权和,这样给定一个训练样本的话,我们可以把这两部分损失给算出来。
训练样本的标注方案为,对于图像的任何一个位置,如果它和真实目标矩形框的重叠比大于指定阈值,则标注为1,否则标注为0;对位置的标注根据每个像素与目标矩形框4条边的距离计算。
这种多目标的损失函数,等会在讲fastRCNN、fasterRCNN、YOLO、SSD等等还有一系列人脸识别的算法里边经常会用到这样一种思想,同一种神经网路它要完成几种不同的任务,第一个是做分类,判断每个位置上是不是有目标,如果该位置有目标还要预测目标的位置,因此它有两个任务,合起来就构造出了这样一个多任务的损失函数。
MTCNN简介
下面介绍第三种人脸检测算法,叫MT-CNN即多任务CNN,multi-task CNN,因为他同时把图像中人脸给检测出来了,还把人脸的几个关键点给找出来了,所以说它叫多任务的神经网络。它融合了人脸检测和关键点定位这两个功能,就是在一个网络里面同时完成这两个功能。
这个算法它是怎么做的呢?她抛弃了CascadeCNN那种滑动的思想,即不需要滑窗,但是他还是使用那种级联即Cascade那种思想。也就是说先用一个模型来初步的预测一下,然后再用一个模型细化它,一步步反复这样做,但是他也是用了三级,然后呢,他没有滑窗它怎么做的呢?他也是像DenseBox一样,它是用一个卷积网络一样,直接预测出一个位置数人脸的概率值,以及关键点的坐标。他整个系统用了三个网络构成,即ProposalNet(提取一些候选区,可以认为是一个粗略的筛选,就是把一次是人脸的地方找出来)、RefinementNet(求精的细化网络,比它更复杂的一个网络)、OutputNet(输出网络)。
检测时,使用这3个网络进行级联,即第一个网络的处理结果交给第二个网络处理,第二网络处理完了,交给第三个网络处理,这就有点像前面那个CascadeCNN(CascadeCNN是用了3个尺寸不一样的神经网路合成来完成这样一个检测任务)。
它检测的时候怎么做的呢?首先用ProposalNet输出候选,人脸关键点,这是一个粗略的结果,不准确,这个网络,它是一个全卷积的网络,和DenseBox一样,他就直接输出了一个很小的图像比如缩小到四分之一或八分之一,图像中每一个像素点代表了原始图像里面对应区域出现人脸的概率有多大,以及它如果是人脸的话,他的人脸的关键点坐标是多少,这里它抛弃了用滑动窗口的方案会更快一些,像DenseBox一样。接下来用RefinementNet对ProposalNet的结果重新细化,抛弃了非人脸窗口,只对前面提出的人脸窗口(即检测出来一次是人脸的窗口)进行处理,然后呢,同样也得到一些矩形框的位置及关键点的坐标,并执行了一次非最大抑制。
接下来再送到最后一个网络OutputNet里面进行处理,然后他又在上一步的网络里面进一步的细化,最后得到了矩形框的回归值,即每个人脸矩形框的位置和大小及关键点的准确值,这样就产生了我们最后的检测结果。
Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. 2016.
检测算法的流程