在前端开发中也会或多或少接触到一些与编译相关的内容,常见的有
- 将ES6、7代码编译成ES5的代码
- 将SCSS、LESS代码转换成浏览器支持的CSS代码
- 通过uglifyjs、uglifycss等工具压缩代码
- 将TypeScript代码转换成JavaScript代码
- Vue模板语法转换成render函数、JSX语法转换成JS代码
尽管社区的工具如bable、*-loader已经帮我们完成了上面的所有工作,我们不用关心编译的过程,甚至也很少有人关注输出的代码,但是了解编译原理还是很有必要的,这篇文章主要用来记录我在学习编译原理时整理的一些笔记。
本文包含大量示例代码,跳过部分代码并不影响阅读重要,因此可酌情忽略,附:源码地址。
本文主要参考下面两篇文章
- the-super-tiny-compiler,本文实现的编译器基本参照这个项目实现,附中文讲解-用 JavaScript 写一个超小型编译器
- 怎样写一个解释器,这篇文章讲的十分好,不妨移步阅读
写在前面
在了解编译器的相关概念之前,让我们先确定一下到底是称呼"编译器"还是"解释器"。
程序主要有两种运行方式:静态编译与动态解释。静态编译的程序在执行前全部被翻译为机器码,通常将这种类型称为AOT (Ahead of time)即 “提前编译”;而解释执行的则是一句一句边翻译边运行,通常将这种类型称为JIT(Just-in-time)即“即时编译”。
从静态编译与动态解释这两种程序运行的方式,可以引申出两个工具
- 解释器:直接执行用编程语言编写的指令的程序,即JIT运行时的工具
- 编译器:把源代码转换成(翻译)低级语言的程序,即AOT运行时的工具
实际上,我认为初学时不需要纠结于这些概念,本文的主要目的是实现将一个简单的工具,它的功能是:将dart函数命名参数调用形式
sayHello(name: "shymean", msg: 'hello');
复制代码转换为javascript函数参数调用
sayHello({name: 'shymean', msg: 'hello'})
复制代码如果只是为了输出JavaScript代码,可以把这个工具看做是编译器,因为它将一种代码语言编译成了另外一种代码语言;如果在工具后面在添加一行eval,这个工具就变成了解释器,因为它可以通过JavaScript直接“运行”Dart代码。
所以,简而言之,这篇文章不关注我们实现的到底是编译器还是解释器,统称为编译器即可。
现在回到我们要实现的这个编译器,看起来只要加一对大括号就行了吗?不,我们将学习编译原理,并了解编译器的基本工作流程。
编译器的工作流程
大多数编译器可以分成三个阶段:解析(Parsing),转换(Transformation)以及代码生成(Code Generation)
- 解析是将源代码转换为一种更抽象的表达方式,一般将结果称为AST抽象语法树
- 转换是对AST做一些处理,让他能做到编译器预期他做到的事情
- 代码生成器接收AST转换之后的数据结构,然后把它转换成新的代码。
在vue的源码compiler实现中,可以查看模板编译相关的逻辑
export const createCompiler = createCompilerCreator(function baseCompile ( template: string, options: CompilerOptions ): CompiledResult { const ast = parse(template.trim(), options) if (options.optimize !== false) { optimize(ast, options) } const code = generate(ast, options) return { ast, render: code.render, staticRenderFns: code.staticRenderFns } }) 复制代码可以看见其主要的工作跟上面提到的编译器工作流程基本一致
- parse,将template模板解析成ast,主要是解析标签和上面的属性、指令等内容
- optimize,主要是标记ast的静态节点,优化虚拟DOM树,方便后期diff优化算法
- generate,通过ast生成render函数
接下来我们逐个学习编译器的每一个流程。
解析获取AST
解析一般来说会分成两个阶段:词法分析和语法分析
- 词法分析主要是拆分原始代码,并将其分割成一些Token,token由一些代码语句的碎片组成,可以是数字、标签、运算符等
- 语法分析接收词法分析生成的token,然后把他们转换成一种抽象的表示,这种表示描述了代码语句中每一个片段以及他们之间的关系,这被称为AST抽象语法树,AST是一个嵌套很深的对象,用一种更容易处理的方式代表了代码本身
解析阶段最主要的目的就是从源码中获取所需的信息,但是词法分析和语法分析算是编译器中十分繁琐和无趣的"脏活",下面我们通过两个例子来理解解析的概念和实现。
通过正则拆分文本
这是之前曾做过一个功能,将一段txt文本解析成对话小说,文本内容大致类似于下面结构(此外还有如图片、分支选项等结构,这里暂且省略)
[作者]shymean
[简介]测试测试测试测试
这里是背景旁白~
【小明】
How are you?
[小花]
I'm fine, 3Q you & you?
复制代码需要将其解析成大致如下JSON结构,方便后续提交到服务端
{ author: 'shymean',
abstract: '测试测试测试测试',
nodes:
[ { type: 10, content: '这里是背景旁白~' },
{ name: '小明', content: 'How are you?', type: 0 },
{ name: '小花', content: 'I\'m fine, 3Q you & you?', type: 0 } ] }
复制代码由于整个文档结构都是按约定编写的,因此可以通过正则等方式提取关键信息。接下来是整个功能的简单实现,通过这个功能,可以大致了解文本拆分的逻辑
function parser(input) {
let [header, ...content] = input.split(/\r?\n\s*?\r?\n/); let { author, abstract } = parseHeader(header); let body = getNode(content); return { author, abstract, nodes: body }; // 拆分头部信息 function parseHeader(head) { let res = null; let total = []; const reHeadInfo = /[\[【[].*?[\]】]](.*)\r?\n?/g; while ((res = reHeadInfo.exec(head))) { total.push(res[1]); } let [author, abstract] = total; return { author, abstract }; } // 获取节点列表 function parseContent(content) { const reNode = /[\[【[](.*?)[\]】]].*(?=\r?\n)\r?\n([^]*)/; return content.map(item => { let res = reNode.exec(item); if (res) { // 对话 let name = res[1].trim(); let chatContent = res[2].trim(); return { name: name, content: chatContent, type: 0 }; } else { content = item.trim(); return { type: 10, content }; } }); } } 复制代码可以看见,我们可以使用编译器语言支持的正则来进行拆分,Hexo解析markdown文本并输出静态html文件,大致也是同样的原理。当然,直接遍历源码文本也是可以的,接下来我们来实现简单的词法分析
通过遍历字符串拆分文本
以下面一段简单的JS代码为例
var a = 100;
var b = "hello";
复制代码我们需要把这段代码里面的两个变量声明语句拆分出来,这里我们采用遍历源码文本的方法来实现
function isReserveWords(name) {
const reserveWords = ["var"]; // 假设这里只有var一个关键字 return reserveWords.includes(name); } function tokenizer(input) { let tokens = []; let current = 0; while (current < input.length) { let char = input[current]; if (char === "=" || char===';') { tokens.push({ type: "symbol", value: char }); current++; continue; } // 去除空格 let WHITESPACE = /\s/; if (WHITESPACE.test(char)) { current++; continue; } let NUMBERS = /[0-9]/; if (NUMBERS.test(char)) { let value = ""; while (NUMBERS.test(char)) { value += char; char = input[++current]; } tokens.push({ type: "number", value }); continue; } // 解析字符串,这里只处理了双引号的字符串 if (char === '"') { let value = ""; char = input[++current]; while (char !== '"') { value += char; char = input[++current]; } current++; tokens.push({ type: "string", value }); continue; } // 处理函数、变量名,除开上面的字面量后,只有保留字和函数变量名了 let LETTERS = /[a-z]/i; if (LETTERS.test(char)) { let value = ""; while (LETTERS.test(char)) { value += char; char = input[++current]; } if (isReserveWords(value)) { tokens.push({ type: "reserveWords", value }); } else { tokens.push({ type: "name", value }); } continue; } throw new TypeError("I dont know what this character is: " + char); } return tokens; } let code = `var a = 100; var b = "hello";`; let tokens = tokenizer(code); console.log(tokens); // 从源码中解析得到tokens数组 复制代码可见对于某个符号或者某个连续字符串,都是由我们在解析过程中自己定义的,语言越复杂,词法分析时需要判断的情况越多~
将token转换成AST
这里引用了怎样写一个解释器这篇文章里面的图。
我们可以把(* (+ 1 2) (+ 3 4))这样的表达式拆分成一个tokens数组,然后我们可以遍历这个数组,将其转换成一个AST。下面是该表达式对应的AST结构
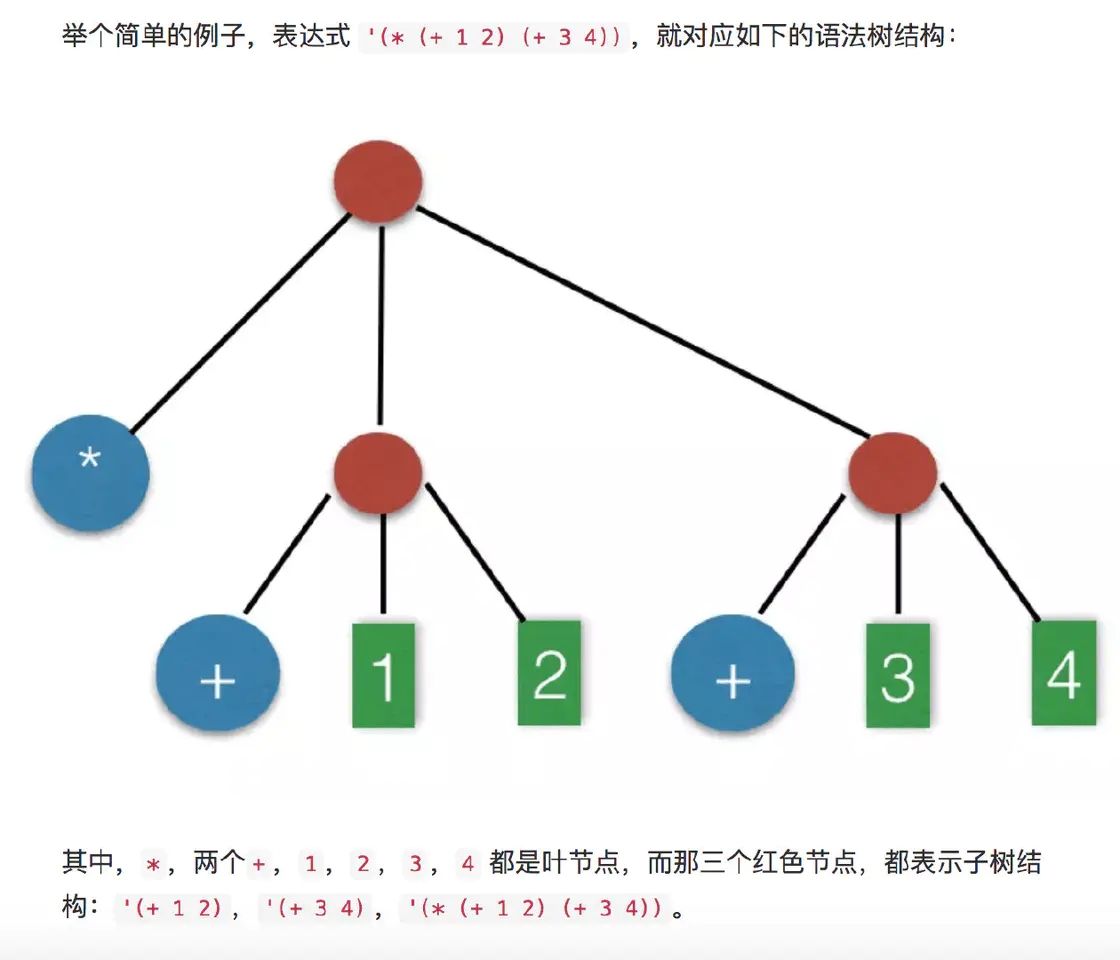
此外还可以参考这个在线示例,将tokens转换成AST是一个比较复杂的过程,在本文实现的编译器中有比较粗略的实现,这里不再赘述,其主要逻辑是通过遍历tokens数组,将不同的token转换成对应类型的节点,然后构造成AST树结构。
遍历AST
虽然AST不一定是二叉树,但是了解二叉树的遍历方式还有有一些帮助的。二叉树常见的两种遍历次序是:深度优先和广度优先
-
在广度优先中,先处理节点的子节点,然后遍历下一层
-
在深度优先中,根据根节点访问顺序的不同又分为了
- 先序遍历,根节点首先被访问,然后先序遍历左子树,最后先序遍历右子树
- 中序遍历,先中序遍历左子树,然后访问跟根节点,最后中序遍历右子树
- 后序遍历,先后序遍历左子树,接着后序遍历右子树,最后访问根节点
// 先序遍历
// 先访问根节点,然后是左子树,最后是右子树
// 所谓访问就是获取节点所保存的数据,
// 如果将树叶当作左右节点都为空的根节点,则访问指的就是访问每层的根节点。
function preorder(node) { if (node) { console.log(node.data); preorder(node.left); preorder(node.right); } } // 中序遍历 // 先遍历左子树,然后是根节点,最后是右子树 function inorder(node) { if (node) { inorder(node.left); console.log(node.data); inorder(node.right); } } // 后序遍历 // 先访问左子树,然后是右子树,最后是根节点 function postorder(node) { if (node) { postorder(node.left); postorder(node.right); console.log(node.data); } } 复制代码遍历AST一般采用的方式是从根节点开始,通过深度优先遍历AST,将不同类型的节点保存在目标语言的对象中,方便后续的代码生成。
同样以Vue的源码为例,在optimizer中,从根节点开始,遍历所有节点,并将对应类型的节点标记为static。
export function optimize (root: ?ASTElement, options: CompilerOptions) { if (!root) return isStaticKey = genStaticKeysCached(options.staticKeys || '') isPlatformReservedTag = options.isReservedTag || no // first pass: mark all non-static nodes. markStatic(root) // second pass: mark static roots. markStaticRoots(root, false) } 复制代码获取到AST,且掌握了对它的遍历方法之后,我们就可以对它进行接下来的操作了。
转换
解析完成后的下一步是转换,它只是把 AST 拿过来然后对它做一些修改。它可以在同种语言下作 AST,也可以把 AST 翻译成全新的语言。
如果解析阶段获取的AST能满足后续的需求,那么转换步骤也许并不是必须的。
代码生成
代码生成阶段主要是根据转换阶段的AST结果来输出目标代码,代码生成器知道如何打印AST获取的各种节点,然后递归调用自身,直到所有节点都被打印在一个很长的字符串中,最后输出目标代码。
因此代码生成阶段最主要的工作,仍旧是遍历AST,并根据每个节点的类型,输出合适的代码。
代码实现
现在我们大致了解了编译器解析、转换和代码生成这三个流程,接下来让我们来一步一步地实现前文提到的编译器。
解析
首先我们通过遍历源码(一个很长的字符串)
sayHello(userName:getUsername("shymean"), msg:"hello");
复制代码将其拆分到一个token数组里面
[ { type: 'name', value: 'sayHello' },
{ type: 'paren', value: '(' }, { type: 'name', value: 'userName' }, { type: 'colon', value: ':' }, { type: 'name', value: 'getUsername' }, { type: 'paren', value: '(' }, { type: 'string', value: 'shymean' }, { type: 'paren', value: ')' }, { type: 'comma', value: ',' }, { type: 'name', value: 'msg' }, { type: 'colon', value: ':' }, { type: 'string', value: 'hello' }, { type: 'paren', value: ')' } 复制代码接着遍历这个token数组,将其解析成对应的ast
{
type: "Program",
body: [
{
type: "CallExpression", name: "sayHello", params: [ { type: "NameParam", name: "userName", value: { type: "CallExpression", name: "getUsername", params: [{ type: "StringLiteral", value: "shymean" }] } }, { type: "NameParam", name: "msg", value: { type: "StringLiteral", value: "hello" } } ] } ] } 复制代码拆分tokens和将tokens的具体实现可以在源码中查到。
转换
看起来我们的简易编译器并不需要生成新的AST,因为他们的函数调用、参数都是类似的,唯一的区别在于dart的命名参数在JS中需要通过对象参数来实现。因此转换这一步被我们简单地略过了,在the-super-tiny-compiler这个项目中,实现了转换功能,将原始的ast转换成更符合JavaScript语义的AST,如函数的calle、arguments等属性
代码生成
在我们的编译器中,这一步的实现是非常简单的:对于NameParam类型的节点,我们会在参数列表首尾拼接{}就大功告成了
function codeGenerator(node, index, nodeList) {
switch (node.type) { // ...其他类型 case "NameParam": let str = ""; // 第一个参数前拼接'{' if (index === 0) { str += "{"; } str += node.name + ":" + codeGenerator(node.value); // 最后一个参数后拼接 '}' if (index === nodeList.length - 1) { str += "}"; } return str; } } 复制代码将上面的流程汇总,然后就可以得到一个非常简单的编译器了
function compiler(input) {
let tokens = tokenizer(input); let ast = parser(tokens); let output = codeGenerator(ast); return output; } let input = `sayHello(userName:getUsername("shymean"), msg:"hello");`; let code = compiler(input); // sayHello({userName:getUsername("shymean"), msg:"hello"}) 复制代码小结
本文先了解了编译器的基本工作流程,然后介绍了词法分析和语法分析的基本实现,接着介绍了遍历AST的方法,最后将各个阶段结合起来,实现了一个十分建议的编译器。
虽然实现的编译器看起来只是添加了一对{},实际上却大致展示一个编译器的工作流程
- 词法分析和语法分析,将源代码转换成AST
- 根据AST输出新的代码,如果目标代码是比较底层的中间代码或机器代码,工作可能会更加繁琐
当然仅仅了解这一些东西是万万不够的,不过万事开头难,了解到编译器的雏形和基本概念之后,进一步的学习才会更有动力,继续学习吧~
作者:橙红年代
链接:https://juejin.im/post/5ceff22af265da1b6b1cbb90