简介
Stream是Redis 5.0引入的一种新数据类型,允许消费者等待生产者发送的新数据,还引入了消费者组概念,组之间数据是相同的(前提是设置的偏移量一样),组内的消费者不会拿到相同数据。这种概念和kafka很雷同。
Stream 类型,从字面上看是流类型,但其实从功能上看,应该是 Redis 对消息队列(MQ,Message Queue)的完善实现。基于 Redis 做消息队列的方案有很多种,例如:
PUB/SUB,订阅/发布模式
基于 Lis 类型t的 LPUSH+BRPOP 的实现
基于 Sorted-Set 的实现
Redis 5.0 中发布的 Stream 类型,也用来实现典型的消息队列。该 Stream 类型的出现,几乎满足了消息队列具备的全部内容。
在某些特定场景可以使用redis的stream代替kafka等消息队列,减少系统复杂性,增强系统的稳定性
特点
1.如果使用xrange和xrevrange命令,则Stream和list功能类同
2.如果使用xread命令,则有其非常独特的地方
2.1 与redis的pub/sub不同,pub/sub多个客户端是收到相同的数据,而stream的多个客户端是竞争关系,每个客户端收到的数据是不相同的
2.2 pub/sub中一旦触发数据获取,不会记录下上一次拿的位置,意味着客户端无法重复去拿以前的数据,而blpop方式一旦pop,数据就会永久的删除,也无法重复去拿以前的数据。而Stream会永久的存放数据,并且客户端会保留上一次拿的id,甚至通过修改id可以拿回以前的数据。和kafka的机制类似。
2.3.Stream提供了消费者组(kafka也有),不同组接收到的数据完全一样(前提是条件一样),但是组内的消费者则是竞争关系(还是和kafka一样)。
2.4.可以设置为阻塞与非阻塞模式
2.5.多客户端时,遵循FIFO特性
命令操作详解
先对基本命令做一些熟练操作,后面再研究高级特性。
注意:命令是不区分大小写的,个人比较喜欢小写的方式
添加
命令格式:XADD stream_name id key-value [key-value ...]
stream_name:给流指定一个名字
id:entry在流中的标识,entry可以理解为添加到流中数据的封装。id一般来说都使用自增的序列,而不需要自己手动指定,有两部分组成:
因为redis的stream是支持范围查询,所以ID组成部分使用了millisecondsTime。因为millisecondsTime就是不断有序自增的
如果要自定义id,则一定要保证全局唯一,避免出现意料不到问题
1.命令行单条执行
XADD mytopic * acctid 012 age 9
输出结果:
127.0.0.1:6379> XADD mytopic * acctid 012 age 9
1527837352024-0
2.使用文件批量执行
在文件中编写命令:
XADD mytopic * acctid 123 age 10
XADD mytopic * acctid 234 age 11
XADD mytopic * acctid 345 age 12
XADD mytopic * acctid 456 age 13
执行命令:
cat 1.txt | redis-cli -a runoob
输出结果:
[hadoop@hadoop00 /home/hadoop/proc/redis-5.0-rc1]$ cat 1.txt | redis-cli -a runoobWarning: Using a password with '-a' option on the command line interface may not be safe.1527837440631-01527837440632-01527837440632-11527837440632-2
查看队列长度命令:
xlen mytopic
输出:
127.0.0.1:6379> xlen mytopic
(integer) 5
127.0.0.1:6379>
获取数据:xrange xrevrange
1.xrange
xrange mytopic - +
符号"-":表示最小值
符号"+":表示最大值
xrange mytopic 0 +
命令xrange mytopic 0 +的效果和上面一样,因为排序时字符0是字符1小的,而上面所有自动生成的millisecondsTime肯定是大于0的
xrange mytopic 1527837440632 1527837440632
自定义查询范围,指定特殊的值,上面的查询结果为同一个毫秒向Stream中添加的数据,包含如下三个entry
1527837440632-0
1527837440632-1
1527837440632-2
xrange mytopic 1527837440632 + count 2
该命令的意思为:查询ID以1527837440632开始,以无限大为结束的entry,但只取出查询结果集(升序排列)中的前两个entry,输出结果包含如下两个Id
1527837440632-0
1527837440632-1
2.xrevrange
xrevrange mytopic + 1527837440632 count 3
该命令的意思为:反向查询ID以无限大为开始,以1527837440632为结束的entry,但只取出查询结果集(降序排列)中的前三个entry,输出结果包含如下三个id
1527839429360-0
1527837440632-2
1527837440632-1
获取数据:xread
1.非阻塞
xread count 4 streams mytopic 0
从stream 中拿ID比0大的4个Entry,按升序排列
count 4:count参数的值为4
streams:该参数必须是xread命令的最后一个参数
xread count 10 streams mytopic mystream 0 0
一次访问多个stream,可分别指定最大ID
2.阻塞
xread block 0 streams mystream $
监听name为mystream的stream,从stream中拿比ID比"$"(特殊ID:该stream中此刻最大ID)还大的Entry,其实只要你将"$"设置为任何一个比当前ID还大的值,一样可以实现阻塞等待,如果比当前ID小,那么立马返回符合条件的entry
block 0:block表示命令要阻塞,0表示阻塞时间为无限大,不超时,如果设置为>0的整数,即为阻塞超时时间
监听生效后,拿到数据监听就失效,与zk的watcher雷同。意思是该命令执行后,只能拿到一条ID比设置ID更大的entry,要想继续拿,必须执行xread命令,官方推荐下一次拿entry使用上一次得到的ID。注意千万别乱设置很大的ID ,否则你可能永远拿不到entry。
xread block 0 streams mystream mytopic $ $
收到任何一个stream的消息,本次监听就失效,只能拿到一条数据,后面还需要拿数据,可以将各自stream拿到的ID作为最大ID,重新执行命令
消费者组-Consumer groups
redis5引入了消费者组的概念,一个stream的数据每一个消费者组都发一份,消费者组里面的消费者竞争同一份数据,亦即在同一个消费者组内,一个消息是不可能发给多个消费者的
need-to-insert-img
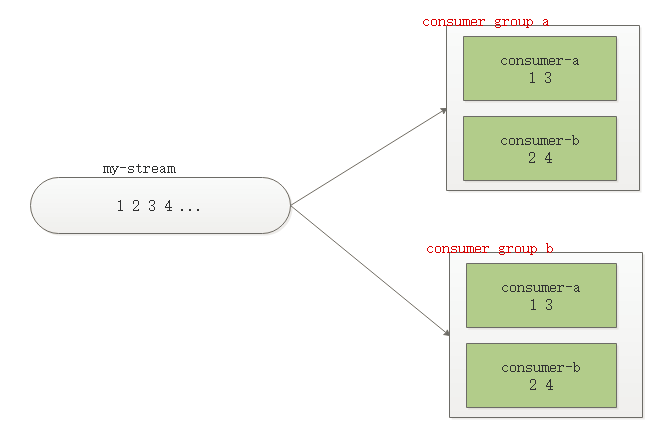
消费者组提供了如下5点保障:
组内消费者消费的消息不重复
组内消费者名称必须唯一
消费者拿到的消息肯定是没有被组内其他消费者消费过的消息
消费者成功消费消息之后要求发送ACK,然后这条消息才会从消费者组中移除,也就是说消息至少被消费一次,和kafka一样
消费者组会跟踪所有待处理的消息
命令:
1.创建消费者组
xgroup create mytopic mygroup $
该命令的意思是:使用xgroup命令创建了一个mygroup消费者组,该消费者组与mytopic stream进行了关联,以后mygroup消费者组中的消费者就会mytopic stream中拿数据
符号"$"和上面一样,代表mytopic stream中目前最大的ID,消费者拿到的entry的id一定会大于此刻$代表的最大ID。你也可以指定这个最大的ID,比如0
2.从消费者组读数据
xreadgroup group mygroup consumer_a count 1 streams mytopic >
该命令的意思是:使用xreadgroup命令让消费者consumer_a从mygroup消费者组的mytopic stream中拿最新的,并且没有被发送给其他消费者处理的entry。
group:该参数是必选项
">":该符号只有在消费者组命令xreadgroup中有效,意思为mytopic stream中最新且没有被其他消费者处理的ID,千万记住不要与上面"$"最大ID搞混了,否则拿出来的数据与你的期望值不符,如果使用的是任何数组ID,那么该消费者就无法拿到任何新的消息,只是从它的已经处理过的消息中拿,并且不会有ACK机制
如果想一个消费者组关联多个stream可以这样做:
xgroup create mystream mygroup $
xgroup create mytopic mygroup $
xreadgroup group mygroup consumer_a block 0 count 1 streams mytopic mystream > >
读消息的参数多了一个block 0,就是说读数据需要阻塞。
3.发送ACK
将指定ID对应的entry从consumer的已处理消息列表中删除
XACK mystream mygroup 1527864992409-0
参考:https://blog.csdn.net/valada/article/details/88904110
异步执行
指的是若操作 A 和操作 B 需要做数据交互,但是两个操作处理数据的速度相差较大,例如典型的 IO 请求(包括磁盘和网络),此时应该将操作设计为异步执行的,也就是不需要等待其他的操作执行完毕,当前操作就可以继续执行。那此时也可以使用消息队列。在操作A执行完毕后,将结果放入队列即可完成任务,不需要等待操作 B。而操作 B 直接去队列中提取消息进行处理即可。这样,慢的操作还可以并发执行,进而提升响应速度。
