概述
1)资料查询(官方网址)
(1)官方网站:
http://hadoop.apache.org/
(2)各个版本归档库地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
(3)hadoop2.7.6版本详情介绍
https://hadoop.apache.org/docs/r2.7.6/
2)Hadoop运行模式
(1)本地模式(默认模式):
不需要启用单独进程,直接可以运行,测试和开发时使用。
(2)伪分布式模式:
等同于完全分布式,只有一个节点。
(3)完全分布式模式:
多个节点一起运行。
1. 本地文件运行Hadoop 示例
1.1 运行官方grep案例
1)创建在hadoop-2.7.7文件下面创建一个input文件夹
2)将hadoop的xml配置文件复制到input
3)执行share目录下的mapreduce程序
4)查看输出结果
代码示例:
[shaofei@hadoop128 hadoop-2.7.7]$ mkdir input
[shaofei@hadoop128 hadoop-2.7.7]$ cp -r etc/hadoop/*.xml input/
[shaofei@hadoop128 hadoop-2.7.7]$ ll input/
[shaofei@hadoop128 hadoop-2.7.7]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input/ output 'dfs[a-z.]+'
[shaofei@hadoop128 hadoop-2.7.7]$ cat output/*
1.2 官方wordcount案例
1)创建在hadoop-2.7.7文件下面创建一个wcinput文件夹
2)在wcinput文件下创建一个wc.input文件
3)编辑wc.input文件
4)回到hadoop目录/opt/module/hadoop-2.7.7
5)执行程序:
6)查看结果:
代码示例:
[shaofei@hadoop128 hadoop-2.7.7]$ mkdir wcinput
[shaofei@hadoop128 hadoop-2.7.7]$ vim wcinput/input.input
java
java
java
hadoop
hadoop
python
pyfysf
upuptop
java
lll
haha
helloworld
:wq
[shaofei@hadoop128 hadoop-2.7.7]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput/ wcoutput
[shaofei@hadoop128 hadoop-2.7.7]$ cat wcoutput/*
hadoop 2
haha 1
helloworld 1
java 4
lll 1
pyfysf 1
python 1
upuptop 1
2 伪分布式运行Hadoop 案例
2.1 启动HDFS并运行MapReduce 程序
1)执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取jdk的安装路径:
修改JAVA_HOME 路径:
(b)配置:core-site.xml
(c)配置:hdfs-site.xml
(2)启动集群
(a)格式化namenode(第一次启动时格式化,以后就不要总格式化)
(b)启动namenode
(c)启动datanode
(3)查看集群
(a)查看是否启动成功
(b)查看产生的log日志
(c)web端查看HDFS文件系统
(4)操作集群
(a)在hdfs文件系统上创建一个input文件夹
(b)将测试文件内容上传到文件系统上
(c)查看上传的文件是否正确
(d)运行mapreduce程序
(e)查看输出结果
命令行查看:
浏览器查看
浏览器查看.png
(f)将测试文件内容下载到本地
(g)删除输出结果
代码示例
1)配置集群
配置hadoop-env 里面的JAVA_HOME
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/module/jdk1.8.0_191
配置core-site.xml
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/core-site.xml
fs.defaultFS
hdfs://hadoop128:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.7/data/tmp
配置hdfs-site.xml
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/hdfs-site.xml
dfs.replication
1
2)启动集群
格式化namenode
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs namenode -format
启动namenode
[shaofei@hadoop128 hadoop-2.7.7]$ sbin/hadoop-daemon.sh start namenode
确认是否开启成功
[shaofei@hadoop128 hadoop-2.7.7]$ jps
2323 NameNode
2392 Jps
启动datanode
[shaofei@hadoop128 hadoop-2.7.7]$ sbin/hadoop-daemon.sh start datanode
确认是否开启成功
[shaofei@hadoop128 hadoop-2.7.7]$ jps
2417 DataNode
2323 NameNode
2492 Jps
3)查看集群
查看生成的日志log
[shaofei@hadoop128 hadoop-2.7.7]$ cat logs/hadoop-shaofei-datanode-hadoop128.log
在web端查看HDFS文件系统[ip 为linux服务器ip]
http://hadoop128:50070
http://ip:50070
http://hadoop128:50070/explorer.html#/
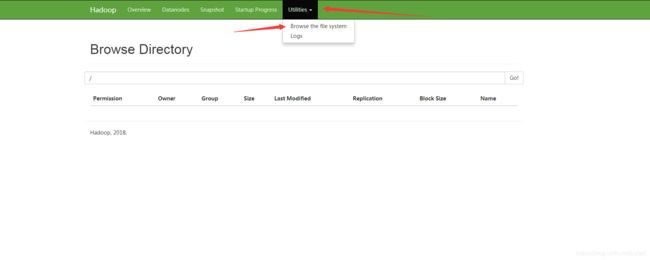
4)操作集群
在hdfs文件系统上创建一个wcinput文件夹
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs dfs -mkdir -p /user/shaofei/wcinput
查看是否创建成功
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs dfs -ls /user
复制本地的 wcinput/input.input 到 hdfs系统中的wcinput中 并查看是否上传成功
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs dfs -put wcinput/input.input /user/shaofei/wcinput
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs dfs -ls /user/shaofei/wcinput
执行MapReduce程序
[shaofei@hadoop128 hadoop-2.7.7]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/shaofei/wcinput/ /user/shaofei/wcoutput
将结果下载到本地查看
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs dfs -get /user/shaofei/wcoutput
[shaofei@hadoop128 hadoop-2.7.7]$ cat wcoutput/*
在web中查看hdfs系统
/user/shaofei
/user/shaofei/wcinput
/user/shaofei/wcoutput


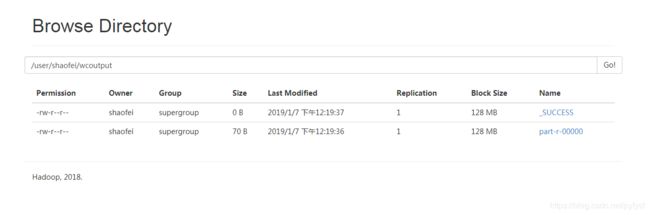
2.2 YARN上运行MapReduce 程序
1)执行步骤
(1)配置集群
(a)配置yarn-env.sh
配置一下JAVA_HOME
(b)配置yarn-site.xml
(c)配置:mapred-env.sh
配置一下JAVA_HOME
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
(2)启动集群
(a)启动前必须保证namenode和datanode已经启动
(b)启动resourcemanager
(c)启动nodemanager
(3)集群操作
(a)yarn的浏览器页面查看
http://192.168.1.101:8088/cluster
(b)删除文件系统上的output文件
(c)执行mapreduce程序
(d)查看运行结果
代码示例
1)配置集群
配置yarn-evn.sh中的JAVA_HOME
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/yarn-env.sh
# some Java parameters
export JAVA_HOME=/opt/module/jdk1.8.0_191
配置yarn-site.xml
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop128
配置mapred-env.sh中的JAVA_HOME
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_191
对mapred-site.xml.template 重命名
[shaofei@hadoop128 hadoop-2.7.7]$ mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
配置mapred-site.xml
[shaofei@hadoop128 hadoop-2.7.7]$ vim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
2)启动集群
启动yarn之前需要确定namenode和datanode是启动状态
[shaofei@hadoop128 hadoop-2.7.7]$ jps
3184 Jps
2417 DataNode
2323 NameNode
启动ResourceManager
[shaofei@hadoop128 hadoop-2.7.7]$ sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
[shaofei@hadoop128 hadoop-2.7.7]$ sbin/yarn-daemon.sh start nodemanager
查看启动程序列表
[shaofei@hadoop128 hadoop-2.7.7]$ jps
2417 DataNode
3217 ResourceManager
3587 Jps
2323 NameNode
3465 NodeManager
在浏览器中查看
http://[ip]:8088/cluster

2)执行MapReduce
删除文件系统上的output文件
[shaofei@hadoop128 hadoop-2.7.7]$ bin/hdfs dfs -rm -r /user/shaofei/wcoutput
执行mapreduce程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/shaofei/wcinput /user/shaofei/wcoutput
查看运行结果
[shaofei@hadoop128 hadoop-2.7.7]$ hadoop fs -cat /user/shaofei/wcoutput/*
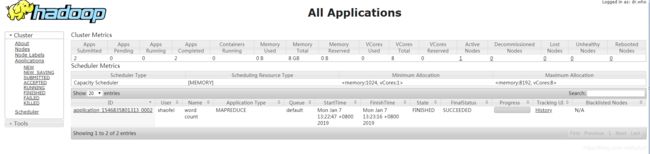
3 完全分布式
集群部署规划
| – | hadoop132 | hadoop133 | hadoop134 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
配置文件
core-site.xml
fs.defaultFS
hdfs://hadoop132:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop134:50090
slaves
hadoop132
hadoop133
hadoop134
yarn
yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop133
mapreduce
mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
mapred-site.xml
mapreduce.framework.name
yarn
集群同步以上配置文件
启动集群
如果集群是第一次启动,需要格式化 namenode
$ bin/hdfs namenode -format
$ sbin/start-dfs.sh
第二台机器上启动yarn
$ sbin/start-yarn.sh
注意:Namenode 和 ResourceManger 如果不是同一台机器,不能在 NameNode 上启动 yarn,应该在 ResouceManager 所在的机器上启动 yarn。
本博客仅为博主学习总结,感谢各大网络平台的资料。蟹蟹!!