String字符串是系统里最常用的类型之一,在系统中占据了很大的内存,因此,高效地使用字符串,对系统的性能有较好的提升。
针对字符串的优化,我在工作与学习过程总结了以下三种方案作分享:
一.优化构建的超大字符串
验证环境:jdk1.8
反编译工具:jad
1.下载反编译工具jad,百度云盘下载:
链接:https://pan.baidu.com/s/1TK1_N769NqtDtLn28jR-Xg
提取码:ilil
2.验证
先执行一段例子1代码:
执行完成后,用反编译工具jad进行反编译:jad -o -a -s d.java test.class
1 public class test3 { 2 public static void main(String[] args) { 3 String str="ab"+"cd"+"ef"+"123"; 4 } 5 }
反编译后的代码:
1 // Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov. 2 // Jad home page: http://www.kpdus.com/jad.html 3 // Decompiler options: packimports(3) annotate 4 // Source File Name: test.java 5 package example; 6 public class test 7 { 8 public test() 9 { 10 // 0 0:aload_0 11 // 1 1:invokespecial #112 // 2 4:return 13 } 14 public static void main(String args[]) 15 { 16 String str = "abcdef123"; 17 // 0 0:ldc1 #2 18 // 1 2:astore_1 19 // 2 3:return 20 } 21 }
案例2:
1 public class test1 { 2 public static void main(String[] args) 3 { 4 String s = "abc"; 5 String ss = "ok" + s + "xyz" + 5; 6 System.out.println(ss); 7 } 8 }
用反编译工具jad执行jad -o -a -s d.java test1.class进行反编译后:
1 // Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov. 2 // Jad home page: http://www.kpdus.com/jad.html 3 // Decompiler options: packimports(3) annotate 4 // Source File Name: test1.java 5 6 package example; 7 8 import java.io.PrintStream; 9 10 public class test1 11 { 12 public test1() 13 { 14 // 0 0:aload_0 15 // 1 1:invokespecial #116 // 2 4:return 17 } 18 public static void main(String args[]) 19 { 20 String s = "abc"; 21 // 0 0:ldc1 #2 22 // 1 2:astore_1 23 String ss = (new StringBuilder()).append("ok").append(s).append("xyz").append(5).toString(); 24 // 2 3:new #3 25 // 3 6:dup 26 // 4 7:invokespecial #4 27 // 5 10:ldc1 #5 28 // 6 12:invokevirtual #6 29 // 7 15:aload_1 30 // 8 16:invokevirtual #6 31 // 9 19:ldc1 #7 32 // 10 21:invokevirtual #6 33 // 11 24:iconst_5 34 // 12 25:invokevirtual #8 35 // 13 28:invokevirtual #9 36 // 14 31:astore_2 37 System.out.println(ss); 38 // 15 32:getstatic #10 39 // 16 35:aload_2 40 // 17 36:invokevirtual #11 41 // 18 39:return 42 } 43 }
根据反编译结果,可以看到内部其实是通过StringBuilder进行字符串拼接的。
再来执行例3的代码:
1 public class test2 { 2 public static void main(String[] args) { 3 String s = ""; 4 Random rand = new Random(); 5 for (int i = 0; i < 10; i++) { 6 s = s + rand.nextInt(1000) + " "; 7 } 8 System.out.println(s); 9 } 10 }
用反编译工具jad执行jad -o -a -s d.java test2.class进行反编译后,发现其内部同样是通过StringBuilder来进行拼接的:
1 // Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov. 2 // Jad home page: http://www.kpdus.com/jad.html 3 // Decompiler options: packimports(3) annotate 4 // Source File Name: test2.java 5 package example; 6 import java.io.PrintStream; 7 import java.util.Random; 8 public class test2 9 { 10 public test2() 11 { 12 // 0 0:aload_0 13 // 1 1:invokespecial #114 // 2 4:return 15 } 16 public static void main(String args[]) 17 { 18 String s = ""; 19 // 0 0:ldc1 #2 20 // 1 2:astore_1 21 Random rand = new Random(); 22 // 2 3:new #3 23 // 3 6:dup 24 // 4 7:invokespecial #4 25 // 5 10:astore_2 26 for(int i = 0; i < 10; i++) 27 //* 6 11:iconst_0 28 //* 7 12:istore_3 29 //* 8 13:iload_3 30 //* 9 14:bipush 10 31 //* 10 16:icmpge 55 32 s = (new StringBuilder()).append(s).append(rand.nextInt(1000)).append(" ").toString(); 33 // 11 19:new #5 34 // 12 22:dup 35 // 13 23:invokespecial #6 36 // 14 26:aload_1 37 // 15 27:invokevirtual #7 38 // 16 30:aload_2 39 // 17 31:sipush 1000 40 // 18 34:invokevirtual #8 41 // 19 37:invokevirtual #9 42 // 20 40:ldc1 #10 43 // 21 42:invokevirtual #7 44 // 22 45:invokevirtual #11 45 // 23 48:astore_1 46 47 // 24 49:iinc 3 1 48 //* 25 52:goto 13 49 System.out.println(s); 50 // 26 55:getstatic #12 51 // 27 58:aload_1 52 // 28 59:invokevirtual #13 53 // 29 62:return 54 } 55 }
综上案例分析,发现字符串进行“+”拼接时,内部有以下几种情况:
1.“+”直接拼接的是常量变量,如"ab"+"cd"+"ef"+"123",内部编译就把几个连接成一个常量字符串处理;
2. “+”拼接的含变量字符串,如案例2:"ok" + s + "xyz" + 5,内部编译其实是new 一个StringBuilder来进行来通过append进行拼接;
3.案例3循环过程,实质也是“+”拼接含变量字符串,因此,内部编译时,也会创建StringBuilder来进行拼接。
对比三种情况,发现第三种情况每次做循环,都会新创建一个StringBuilder对象,这会增加系统的内存,反过来就会降低系统性能。
因此,在做字符串拼接时,单线程环境下,可以显性使用StringBuilder来进行拼接,避免每循环一次就new一个StringBuilder对象;在多线程环境下,可以使用线程安全的StringBuffer,但涉及到锁竞争,StringBuffer性能会比StringBuilder差一点。
这样,起到在字符串拼接时的优化效果。
2.如何使用String.intern节省内存?
在回答这个问题之前,可以先对一段代码进行测试:
1.首先在idea设置-XX:+PrintGCDetails -Xmx6G -Xmn3G,用来打印GC日志信息,设置如下图所示:
2.执行以下例子代码:
未使用intern的GC日志:
1 public class test4 { 2 public static void main(String[] args) { 3 final int MAX=10000000; 4 System.out.println("不用intern:"+notIntern(MAX)); 5 // System.out.println("使用intern:"+intern(MAX)); 6 } 7 private static long notIntern(int MAX){ 8 long start = System.currentTimeMillis(); 9 for (int i = 0; i < MAX; i++) { 10 int j = i % 100; 11 String str = String.valueOf(j); 12 } 13 return System.currentTimeMillis() - start; 14 } 15 /* 16 private static long intern(int MAX){ 17 long start = System.currentTimeMillis(); 18 for (int i = 0; i < MAX; i++) { 19 int j = i % 100; 20 String str = String.valueOf(j).intern(); 21 } 22 return System.currentTimeMillis() - start; 23 }*/ 24
1 不用intern:354 2 [GC (System.gc()) [PSYoungGen: 377487K->760K(2752512K)] 377487K->768K(2758656K), 0.0009102 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 3 [Full GC (System.gc()) [PSYoungGen: 760K->0K(2752512K)] [ParOldGen: 8K->636K(6144K)] 768K->636K(2758656K), [Metaspace: 3278K->3278K(1056768K)], 0.0051214 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 4 Heap 5 PSYoungGen total 2752512K, used 23593K [0x0000000700000000, 0x00000007c0000000, 0x00000007c0000000) 6 eden space 2359296K, 1% used [0x0000000700000000,0x000000070170a548,0x0000000790000000) 7 from space 393216K, 0% used [0x0000000790000000,0x0000000790000000,0x00000007a8000000) 8 to space 393216K, 0% used [0x00000007a8000000,0x00000007a8000000,0x00000007c0000000) 9 ParOldGen total 6144K, used 636K [0x0000000640000000, 0x0000000640600000, 0x0000000700000000) 10 object space 6144K, 10% used [0x0000000640000000,0x000000064009f2f8,0x0000000640600000) 11 Metaspace used 3284K, capacity 4500K, committed 4864K, reserved 1056768K 12 class space used 359K, capacity 388K, committed 512K, reserved 1048576K
根据打印的日志分析:没有使用intern情况下,执行时间为354ms,占用内存为24229k;
使用intern的GC日志:
1 使用intern:1515 2 [GC (System.gc()) [PSYoungGen: 613417K->1144K(2752512K)] 613417K->1152K(2758656K), 0.0012530 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 3 [Full GC (System.gc()) [PSYoungGen: 1144K->0K(2752512K)] [ParOldGen: 8K->965K(6144K)] 1152K->965K(2758656K), [Metaspace: 3780K->3780K(1056768K)], 0.0079962 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] 4 Heap 5 PSYoungGen total 2752512K, used 15729K [0x0000000700000000, 0x00000007c0000000, 0x00000007c0000000) 6 eden space 2359296K, 0% used [0x0000000700000000,0x0000000700f5c400,0x0000000790000000) 7 from space 393216K, 0% used [0x0000000790000000,0x0000000790000000,0x00000007a8000000) 8 to space 393216K, 0% used [0x00000007a8000000,0x00000007a8000000,0x00000007c0000000) 9 ParOldGen total 6144K, used 965K [0x0000000640000000, 0x0000000640600000, 0x0000000700000000) 10 object space 6144K, 15% used [0x0000000640000000,0x00000006400f1740,0x0000000640600000) 11 Metaspace used 3786K, capacity 4540K, committed 4864K, reserved 1056768K 12 class space used 420K, capacity 428K, committed 512K, reserved 1048576K
日志分析:没有使用intern情况下,
执行时间为1515ms,占用内存为16694k;
综上所述:使用intern情况下,内存相对没有使用intern的情况要小,但在节省内存的同时,增加了时间复杂度。我试过将MAX=10000000再增加一个0的情况下,使用intern将会花费高达11秒的执行时间,可见,在遍历数据过大时,不建议使用intern。
因此,使用intern的前提,一定要考虑到具体的使用场景。
到这里,可以确定,
使用String.intern确实可以节省内存。
接下来,分析一下intern在不同JDK版本的区别。
在JDK1.6中,字符串常量池在方法区中,方法区属于永久代。
在JDK1.7中,字符串常量池移到了堆中。
在JDK1.8中,字符串常量池移到了元空间里,与堆相独立。
分别在1.6、1.7、1.8版本执行以下一个例子:
1 public class test5 { 2 public static void main(String[] args) { 3 4 String s1=new String("ab"); 5 s.intern(); 6 String s2="ab"; 7 System.out.println(s1==s2); 8 9 10 String s3=new String("ab")+new String("cd"); 11 s3.intern(); 12 String s4="abcd"; 13 System.out.println(s4==s3); 14 } 15 }
1.6版本
执行结果:
fasle false
分析:
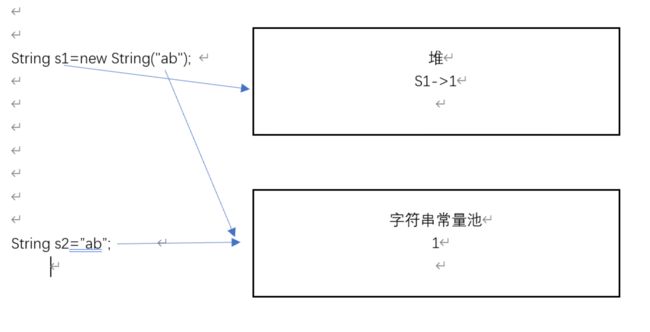
执行第一部分时:
1.代码编译时,先在字符串常量池里创建常量“ab";在调用new时,将在堆中创建一个String对象,字符串常量创建的“ab"存储到堆中,最后堆中的String对象返回一个引用给s1。
2.s.intern(),在字符串常量池里已经存在“ab”,便不再创建存放副本“ab";
3.s2="ab",s2指向的是字符串常量池里”ab",而s1指向的堆中的”ab",故两者不相等。
该示意图如下:
执行第二部分:
1.两个new出来相加的“abcd”存放在堆中,s3指向堆中的“abcd";
2.执行s3.intern(),在将“abcd"副本的存放到字符串常量池时,发现常量池里没有该”abcd",因此,成功存放;
3.s4="abcd"指向的是字符串常量池里已有的“abcd"副本,而s3指向的是堆中的"abcd",副本"abcd"的地址和堆中“abcd"地址不相同,故为false;
1.7版本
false true
执行第一部分:这一部分与jdk1.6基本类似,不同在于,s1.intern()返回的是引用,而不是副本。
执行第二部分:
1.new String("ab")+new String("cd"),先在常量池里生成“ab"和”cd",再在堆中生成“abcd";
2.执行s3.intern()时,会把“abcd”的对象引用放到字符串常量池里,发现常量池里还没有该引用,故可成功放入。当String s4="abcd",即把字符串常量池中”abcd“的引用地址赋值给s4,相当于s4指向了堆中”abcd"的地址,故s3==s4为true。
1.8版本
false true
参考网上一些博客,在1.8版本当中,使用intern()时,执行原理如下:
若字符串常量池中,包含了与当前对象相当的字符串,将返回常量池里的字符串;若不存在,则将该字符串存放进常量池里,并返回字符串的引用。
综上所述,可见三种版本当中,使用intern时,若字符串常量池里不存在相应字符串时,存在以下区别:
例如:
String s1=new String("ab"); s.intern();
jdk1.6:若字符串常量池里没有“ab",则会在常量池里存放一个“ab"副本,该副本地址与堆中的”ab"地址不相等;
jdk1.7:若字符串常量池里没有“ab",会将“ab”的对象引用放到字符串常量池里,该引用地址与堆中”ab"的地址相同;
jdk1.8:若字符串常量池中包含与当前对象相当的字符串,将返回常量池里的字符串;若不存在,则将该字符串存放进常量池里,并返回字符串的引用。
3.如何使用字符串的分割方法?
在简单进行字符串分割时,可以用indexOf替代split,因为split的性能不够稳定,故针对简单的字符串分割,可优先使用indexOf代替;