4月26-28日举办的GMIC全球移动互联网大会, 主旨是AI 生万物。大会有来自全球各大公司的重量级人工智能方向的嘉宾,比如李开复、Yann LeCun、Michael Jordan等等,针对AI的现状、AI技术应用与创新、AI的未来发展等话题进行讨论与分享。
如下为嘉宾的重要分享精华,以及自己的补课内容。
AI 的应用领域普及
AI+手机
对于华为的AI而言,主要体现在AI定制芯片、 AI智慧系统和 AI 的应用等等。具体讲了一些示例,比如智能相机:相机在认知进化后,能够做到识别22类标签,500+场景:餐厅、下雪、人像、风景、绿植、阳光、自行车、汽车、建筑等。自拍的时候也能够做到人景分离,专业虚化,甚至可以识别到人的头发,做到丝毫毕现。至于决策系统和推荐系统,已经发展了很久,大大改善了我们的互联网使用习惯,会议上没有多做分享。
AI+教育
对于教育领域的从业者而言,AI的引入无疑是一大利好,现在的网易有道,已经支持智能语音的输入、文本和语音的识别、多地方言语音的转换、语音的合成、多国语言翻译。不仅如此,还支持自动对支持试卷答题判分和对口语表达进行评分。
AI+物流
一般自动送货机器人都有两个选择,无人机和地面机器人。无人机的电池续航力,和能乘载的货物重量较为受限,三是安全疑虑较高,不过优点就是快速。地面递送机器人的优劣势正好相反,可以互补。
无人机器人通过二维码或者开锁code 的形式,在快递员和收件人之间进行沟通。另一方面通过 GPS 追踪、大力碰撞报警等行为进行预防丢失和安全保障。
AI+汽车
此处应当有视频,官方的宣传视频还是不错的,视频播完的时候,现场一片欢呼声。
传统汽车人车是完全绑定的状态,司机离开驾驶位,基本无法操控车。必须要人工驾驶、人工泊车、手动交互。而新型 AI 汽车支持自动驾驶、自动泊车、语音交互,并且远程控车。老司机一般都知道,传统的汽车为了行驶安全,司机在开车过程中,一般是无法对中控台进行部分操控动作的,但是对于AI 汽车,即使司机在开车,也可以通过语音进行操控,比如播放音乐,更换广播频道,等等。并且当遇到非常狭窄的停车位时,司机可以不必停好车后不得不从车尾箱爬出来。。。
人工智能的四波浪潮 @李开复老师
第一波浪潮:互联网的AI浪潮。
用户每天像小白鼠一样,帮助巨头在标注。由于互联网的数据量是最大的,所以巨头互联网公司能够更深度地了解用户的基础,为用户提供更好、更贴切的服务,同时变现。
AI巨头和互联网巨头成等号,美国的Google、FaceBook、亚马逊,中国的BAT。
第二波浪潮:变现或者提升商业价值。
银行、投资机构、保险公司,以及包括供应链、医疗、学校等其他任何有数据的领域,可以把数据商业化。运用一个用户的数据降低银行信用卡的欺诈率或者调整贷款的数据,或者是投资的回报率。
第三波浪潮:把基于视觉、听觉或者其他传感器的数据变成一个新的应用,甚至是一个新的用户体验。
比如,应用在各种智能音响、智能语音交互等领域中。创新工场的前台Face++已经实现无前台化自动运营,无人商店、工厂等。
基于听觉的AI,国内有讯飞、搜狗,在视觉方面也有Face++、云从、腾讯优图、商汤。
第四波浪潮:自主化、自动化的AI。
也就是在科幻电影中看到的机器人和无人驾驶,还有更聪明的无人飞机等。第四个浪潮会彻底颠覆我们的出行习惯,以及今天所有的物流。
无人驾驶的应用与政策有关,美国的工会在要求总统不要允许货车在高速公路上做无人驾驶测试,这种保护主义会作为工作主轴会对科技发展有很大的限制。相对来说,从政策角度,中国更有魄力做这种颠覆基础设施的事情, 雄安已经为无人驾驶设立了高速公路,会让中国有很大的优势。
Facebook人工智能团队首席AI科学家 @Yann LeCun
主要讲了如下几方面的内容,并且强调Facebook接下来最新的重心是监督学习方面。
监督学习无可替代
监督学习是不能够被替代的,不管是无监督学习还是其他的学习方式都不能够替代它, 如今的 AI 系统都是使用的监督学习,应用诸如:
语音识别:语音转成文本、文本转换语音。
图像识别:图像进行分类、从照片中识别人物、从照片中识别文字。
机器翻译:不同语言相互翻译。
监督学习的特点
训练监督学习模型需要向它展示各种例子,并告诉它正确答案,如果想让机器学会将汽车和飞机区分开来,比如给它展示一辆车的图像,它说这不是一辆车,然后算法上就可以对参数进行调整,下次再向机器展示同一张图像的话,就会得到接近正确的答案。
Facebook 人工智能部门的研究
Mask R-CNN,可以标记图像。随着网络深度的不断增加,识别 ImageNet 图像的错误率也在不断下降,现在已经表现得比人还要好。
不仅可以识别出对应的物体是什么,还可以对图像进行精细的分割。
比如它不仅可以识别出每个人,同时会为每个人加一个标记,所以可以很容易区分出是一个人还是一只狗。并且只是部分可见的东西都可以分得清。
PyTorch:开源了人工智能编程工具PyTorch,是一个深度学习框架的平台,有很多的示例和交换层,被很多研究团队使用。(其实在下午的另外一个nvidia嘉宾分享的过程中,也一再强调,python被称为是机器学习最优秀的语言。)
DarkForest:黑暗森林,体验很多工程。
FastText:快速文本,快速进行文本分类、表示和嵌入。
FairSeq:神经机器翻译。
FAISS:快速相似搜索。
ResNext:具有平行类型的。
DeepMask:综合识别/分隔。
PailAI:对话场景训练。
Detectron:完整的视觉系统,可以识别电脑、酒杯、人、桌子,也可以数出来到底有多少,而且也可以识别出道路、汽车。可以下载上面的代码,它可以探测 200 多种不同的类别。
DensePose,预测人类的行为。可以跟踪很多人的行为,生成视频,非常的准确,可以实时地生成一些相应的数据和信息,并且相应的代码也是可以用的。
深度学习的应用领域
医疗图片分析、无人驾驶汽车、便利性、人脸识别、语言翻译、虚拟助理、对内容的理解:过滤&排名&搜索、游戏、安全异常侦查、诊断预测、科学研究。
深度学习能做到和不能做到的
深度学习可以做到的
更安全的汽车,无人驾驶
更好的医疗图像分析
个人专属医疗
恰当的语言翻译
有用的但是很傻的聊天机器人
信息搜索、检索、过滤
在能源、金融、制造、换包、商业、法律、艺术创作、游戏等应用
深度学习不可以做什么
和人一样思维的机器
智能的私人助手
聪明的聊天机器人
家用机器人
灵巧敏捷的机器人
平面设计
机器学习之父 @Michael Jordan
AI 的原则
Michael Jordan讲到AI 是以人为中心的工程科学,现在虽然可以从数据中提炼模型实现一些功能,但是,一些语义、背景和引申的含义等等,都还不够做到真正的智能和智慧。
比如一个专家系统能够通过学习我的一些信息,推荐我看这本书、看这部电影,我会感觉到“量身定制”的优越性。但如果系统向所有人推荐了同一家餐厅,那么拥挤不堪的用餐体验并不能让每个人感到高兴;又比如说从机场到市区,系统会告诉所有查询的人哪条路不堵,结果反而让这条原本不堵的路变得拥挤。
我们期望建立的是智能的自动化系统,但是目前 AI 的原则并没有完全的建立,体系尚未成熟,所以需要建立很多基本的原则才能建立一个体系,让机器达到人类的智能水平。
AI 的未来
在真实世界中,一些决定可能还是有先后顺序和优先级别的,可能要做出的是成千上万个在经济、金融、商业方面的决策。如何保证自主做出决策的准确性?这个过程并不完善,有很多概念还需要去完善。
因此在搭建AI体系的时候,考虑的应该不是单个的个体智能,而是整个体系和网络。包括数据、决策,包括还有可能出现的错误都要考虑进去。
AI Auto Robby自动送货机器人 @ 李瑞
AI Auto 的五个层级
美国高速公司安全管理局(NHTSA)将无人驾驶划分为五个层级:无自动驾驶辅助功能、特定自动驾驶辅助功能、组合式自动驾驶辅助功能、有限自动驾驶以及无人驾驶。
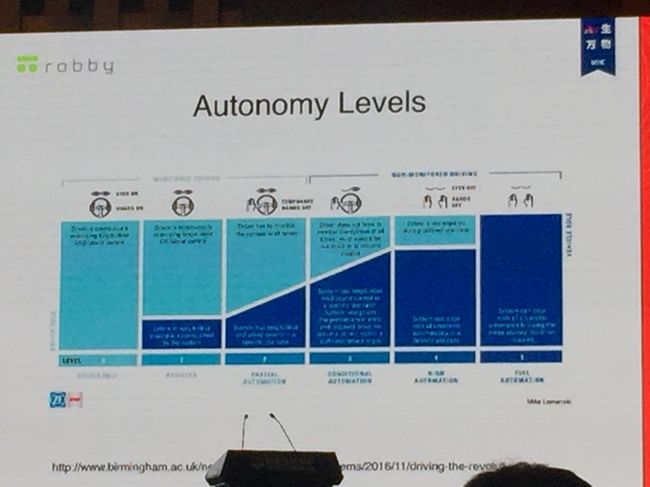
每个层级的主要技术特征见下:
LEVER 0:无自动驾驶辅助功能。没有装备任何装备任何自动驾驶辅助的功能或仅安装了一些预警系统。
LEVER 1:特定功能的自动驾驶辅助功能。车型装备了能协助驾驶者在特定情况下自动驾驶的功能。
LEVER 2:组合自动驾驶辅助。将多个自动驾驶功能组合协调工作,实现特定场景的自动驾驶。
LEVER 3:优先自动驾驶辅助(高度自动驾驶)。汽车将逐步替代人类成为行驶的主导。
LEVER 4:无人驾驶,汽车完全是先无人驾驶。只需要驾驶员给出既定的目的地,就可以前往。
AI Auto 的应用
自动驾驶技术,除了Waymo、Uber的无人驾驶汽车以外,递送机器人也是自动驾驶的一种应用,虽然行进速度不像一般汽车那么快,但不论是辨识行人、自行车、汽车等物体来达到避障、城市地图+LiDAR的路径规划(routing)、定位、与行人互动等。
大会上李瑞有讲到这个小箱子机器人Robby每小时速度3~6里,充一次电可以跑20里,上坡、下坡、晴天、雨天,甚至在旧金山坡度最高约22度的市区仍然可以正常运作。
NVIDIA 英伟达@Yann LeCun
深度学习框架的比较
分享了各种市面上流行的深度学习框架Tensorflow/Caffe/CNTK/ Theano/Torch的特点和核心,并说明Python 是机器学习的最佳最简单语言,如果会 python,则机器学习的入门和学习的成本大大降低,学习效率大大提升。
补充
名词解释
图像分类 Image Classification
对出现在某幅图像中的物体做标注。比如一共有1000个物体类,对一幅图中所有物体来说,某个物体要么有,要么没有。可实现:输入一幅测试图片,输出该图片中物体类别的候选集。
物体检测 Object detection
包含两个问题,一是判断属于某个特定类的物体是否出现在图中;二是对该物体定位,定位常用表征就是物体的边界框。可实现:输入测试图片,输出检测到的物体类别和位置。
语义分割 Semantic scene labeling
将图中每一点像素标注为某个物体类别。同一物体的不同实例不需要单独分割出来。对下图,标注为人,羊,狗,草地。而不需要羊1,羊2,羊3,羊4,羊5.
实例分割 Instance segment
物体检测+语义分割的综合体。相对物体检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割可以标注出图上同一物体的不同个体(羊1,羊2,羊3…)
4种任务的数据集标注示例如图示。标注越来越复杂,但是处理效果越来越有用。
监督学习和非监督学习
机器学习分为:监督学习,无监督学习,半监督学习(也称强化学习)等。
监督学习(supervised learning)
监督学习就是通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统(模型)。
简单来理解,就是从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。这种情况输入的数据都是有明确标记的。
无监督学习(unsupervised learning)
非监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情。
输入数据没有被标记,也没有确定的结果。
AI人才培养
开复老师给大家带福利了。开复老师讲到美国在AI教育方面有非常强的优势。比如说Yann LeCun教授、Michael Jordan教授为代表的很多大学,甚至美国前一百名的大学都有非常好的AI课程。因此在国内计划开展 AI 人才培养计划。
一,创新工场和教育部、北大联合做教师培训,目标是做到,中国前一百甚至几百名的大学都能够有很好的AI课程,学生们在读本科的时候就可以接触到AI。
二,做针对性的培养,把最有潜质成为未来AI金字塔顶尖的朋友集合起来,进行培养,请国际大牛和国内大牛对他们进行帮助、授课。
第三,与各大公司成立竞赛平台。