快过年了,我老婆又开始囤年货了,购物车里全是她加购的零食,闲来无事,就顺手爬了淘宝搜索美食出来的商品信息,简单做了个分析,借此案例给大家学习参考。
数据采集
淘宝的页面也是通过Ajax来抓取相关数据,但是参数比较复杂,甚至包含加密秘钥。用selenium来模拟浏览器操作,抓取淘宝商品信息,即可做到可见即可爬。我就用selenium爬了淘宝网页上能显示的100页的数据,大约4400个左右,速度也不慢,具体步骤如下:
1.准备工作
用selenium抓取淘宝商品,并用pyquery解析得到商品的图片,名称,价格,购买人数,店铺名称和店铺所在位置。需要安装selenium,pyquery,以及Chrome浏览器并配置ChromeDriver。
我们的目标是获取商品的信息,那么先搜索,例如我们搜索美食。而我们需要的信息都在每一页商品条目里。在页面的最下面,有个分页导航。为100页,要获得所以的信息只需要从第一页到带一百页顺序遍历。采用selenium模拟浏览器不断的遍历即可得到,这里为直接输入页数然后点击确定转跳。这样即使程序中途出错,也可以知道爬到那一页了,而不必从头再来。

我们爬取淘宝商品信息,只需要得到总共多少条商品条目,而淘宝默认100页,则只需要每一页商品条目都加载完之后爬取,然后再转跳就好了。用selenium只需要定位到专业和条目即可。
整体代码如下:
from selenium import webdriverfrom selenium.common.exceptions import TimeoutExceptionfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.wait import WebDriverWaitfrom urllib.parse import quotefrom pyquery import PyQuery as pqimport pymongoMAX_PAGE = 100MONGO_URL = 'localhost'MONGO_DB = 'taobao'MONGO_COLLECTION = 'foods'client = pymongo.MongoClient(MONGO_URL)db = client[MONGO_DB]browser = webdriver.Chrome()wait = WebDriverWait(browser, 10)KEYWORD='美食'def index_page(page):"""抓取索引页:param page:页码"""print('正在爬取第', page, '页')try:url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)browser.get(url)if page > 1:input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')))submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')))input.clear()input.send_keys(page)submit.click()wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)))wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item')))get_products()except TimeoutException:index_page(page)def get_products():'''提取商品'''html = browser.page_sourcedoc = pq(html)items = doc('#mainsrp-itemlist .items .item').items()for item in items:product = { 'image': item.find('.pic .img').attr('data-src'), 'price': item.find('.price').text(), 'deal': item.find('.deal-cnt').text(), 'title': item.find('.title').text(), 'shop': item.find('.shop').text(), 'location': item.find('.location').text()}print(product)save_to_mongo(product)def main():'''遍历每一页'''for i in range(1, MAX_PAGE+1):index_page(i)browser.close()def save_to_mongo(result):"""保存至MongoDB"""try:if db[MONGO_COLLECTION].insert(result):print('存储到MongoDB 成功')except Exception: print('存储到MongoDB失败')if __name__ == '__main__':main()
运行结果:

数据清洗
拿到数据后,对商品数据进行清洗和处理。
1 、导入数据
import pandas as pdimport numpy as npimport pymysqlimport recoon = pymysql.connect( host='localhost', user='root', passwd='root', port=3306, db='taobao', charset='utf8' # port必须写int类型 # charset必须写utf8,不能写utf-8)cur = coon.cursor() # 建立游标sql='select * from taobao_food'df=pd.read_sql(sql=sql,con=coon)#print(df.values)df=pd.DataFrame(df)df=df.drop('id',axis=1)print(pd.isnull(df).values.any())
2、去重
print('去重之前的形状',df.shape)df=df.drop_duplicates(keep='first')print('去重之后的形状',df.shape)print(df.head())

3、提取地址信息以及购买数量
def get_buy_num(buy_num):if u'万' in buy_num: # 针对1-2万/月或者10-20万/年的情况,包含-buy_num=float(buy_num.replace("万",''))*10000#print(buy_num) else:buy_num=float(buy_num)returnbuy_numdf['place'] = df['place'].replace('','未知')#fillna("['未知']")datasets = pd.DataFrame()for index, row in df.iterrows(): #print(row["place"]) row["place"] = row["place"][:2] row["buy_num"]=get_buy_num(row["buy_num"][:-3].replace('+',''))#print(row["place"])df.to_csv('taobao_food.csv',encoding='utf8',index_label=False)
数据分析
先来看看美食搜索结果里面,哪些种类关键词出现的比较多,对商品标题进行文本分析,用词云图进行可视化,代码如下:
import pandas as pdimport jieba, refrom scipy.misc import imreadfrom wordcloud import WordCloud, ImageColorGenerator, STOPWORDSimport matplotlib.pyplot as pltfr = open('停用词.txt', 'r')stop_word_list = fr.readlines()new_stop_word_list = []for stop_word in stop_word_list:stop_word = stop_word.replace('\\ufeef', '').strip() new_stop_word_list.append(stop_word)file1 = df.loc[:,'title'].dropna(how='any') # 去掉空值print('去掉空值后有{}行'.format(file1.shape[0])) # 获得一共有多少行print(file1.head())text1 = ''.join(i for i in file1) # 把所有字符串连接成一个长文本responsibility = re.sub(re.compile(',|;|\.|、|。'), '', text1) # 去掉逗号等符号wordlist1 = jieba.cut(responsibility, cut_all=True)print(wordlist1)word_dict={}word_list=''for word in wordlist1:if (len(word) > 1 and not word in new_stop_word_list):word_list = word_list + ' ' + wordif (word_dict.get(word)):word_dict[word] = word_dict[word] + 1else:word_dict[word]=1print(word_list)print(word_dict)#输出西游记词语出现的次数#按次数进行排序sort_words=sorted(word_dict.items(),key=lambda x:x[1],reverse=True)print(sort_words[0:101])#输出前0-100的词font_path=r'C:\Windows\Fonts\SIMYOU.TTF'#bgimg=imread(r'1.png')#设置背景图片wc = WordCloud(font_path=font_path, # 设置字体 background_color="black", # 背景颜色 max_words=300, # 词云显示的最大词数 stopwords=stopwords, # 设置停用词 max_font_size=400, # 字体最大值 random_state=42, # 设置有多少种随机生成状态,即有多少种配色 width=2000, height=1720, margin=4, # 设置图片默认的大小,margin为词语边缘距离 ).generate(str(word_list))#image_colors = ImageColorGenerator(bgimg) # 根据图片生成词云颜色plt.imshow(wc)plt.axis("off")plt.savefig("examples.jpg") # 必须在plt.show之前,不是图片空白plt.show()

果然,不出所料,休闲零食小吃之类的销量最高;
接下来我们再对商品的销量进行排名:
print(df['buy_num'].sort_values(ascending=False))print(df.loc[df['buy_num'].sort_values(ascending=False).index,'shop'])a=df['buy_num'].sort_values(ascending=False)b=df.loc[df['buy_num'].sort_values(ascending=False).index,'shop']c=df.loc[df['buy_num'].sort_values(ascending=False).index,'title']frames = [a,b,c]data=pd.concat(frames,axis=1)print(data)

销量第一名是三只松鼠旗舰店的猪肉脯,而且前20名里面,三只松鼠就占了将近一半,不得不佩服,果然是零食界扛把子,再一看我老婆的购物车,果然有不少三只松鼠的零食。
我们再获取一下销量排名商店所在的城市信息,看看淘宝销量最高的美食都来自哪里
a=df['buy_num'].sort_values(ascending=False)b=df.loc[df['buy_num'].sort_values(ascending=False).index,'place']c=df.loc[df['buy_num'].sort_values(ascending=False).index,'shop']frames = [a,c,b]data=pd.concat(frames,axis=1)print('销售排名商店与所在城市信息分布\n',data)

buy_num_sum=df.groupby(['place'])['buy_num'].sum().sort_values(ascending=False)print('地区销售总量信息分布\n',buy_num_sum)
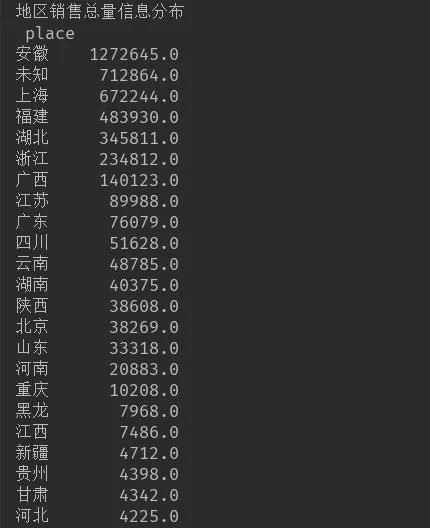
做个地区销售总量信息分布图
brougt=buy_num_sum.values.tolist()address=buy_num_sum.index.tolist()map = Map("地区销售总量信息分布", "data from 51job",title_color="#404a59", title_pos="left")map.add("销售总量", address,brougt , maptype='china',visual_range=[0, 300000],is_visualmap=True,visual_text_color='#000',is_label_show=True,is_map_symbol_show=False)map.render("地区销售总量信息分布图.html")

安徽和上海的美食总销量处于TOP级别的位置,上海排在前几名我可以理解,安徽有些让我出乎意料,我猜安徽应该有不少的食品加工厂。
最后,我再来看看商品价格与销量的分析,看看价格和销量的关系
a=df.loc[df['buy_num'].sort_values(ascending=False).index,'price']b=df['buy_num'].sort_values(ascending=False)frames = [a,b]data=pd.concat(frames,axis=1).reset_index()print('商品价格对销售额的影响分析',data)from pyecharts import Lineline = Line("商品价格对销售额的影响分析")line.add("价格随销量降低而变化",data['price'].index,data['price'], is_smooth=True,mark_line=["max", "average"])line.render('折线图1.html')
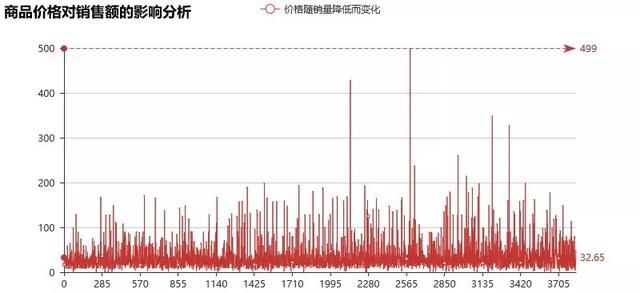
可以明显看出,随着销售额的下降,商品的售卖价格也在增高。换句话说,销量排名靠前的商品大部分价格都不高,人们也倾向于购买价格实惠的美食