0. 前言
数据库的事务隔离级别是关系型数据库事务的理论基础,本文将从资源互斥的角度从上到下依次进行阐释。
1.数据库的事务隔离级别
1.1 事务的隔离级别,隔离的是什么?
在阐述数据库事务的隔离级别时,我们首先应当明确一下,这个隔离,到底隔离的是什么。
- 什么是事务?
从数据库的事务定义来看,其具备ACID特性(即Atomic,原子性,Consistency一致性,Isolation,隔离性,Duration,持久性)。
一般意义上讲,所谓的事务,指的是一批操作,可以原子性的方式进行,要么全部成功,要么全部失败; - 什么是隔离性,隔离的是什么?
隔离性,是指不同的客户端在做事务操作时,理想状态下,各个客户端之间不会有任何相互影响,好像感知不到对方存在一样。所谓的隔离,真正隔离的对象在实现上是数据库资源的互斥性访问,隔离性就是通过数据库资源划分的不同粒度体现的。
接下来,本文将通过数据库资源的不同粒度的划分,来阐述隔离性不同级别的实现。
1.2 - 隔离级别-序列化读(SERIALIZABLE READ)
1.1.1 将整个数据库作为互斥资源
如果将整个数据库当做互斥资源的访问,那么,这种访问会有如下性质:
规定同一时间内只能有一个客户端连接数据库进行事务操作,在这个客户端完成事务之前,其他客户端不能对数据库进行事务操作。
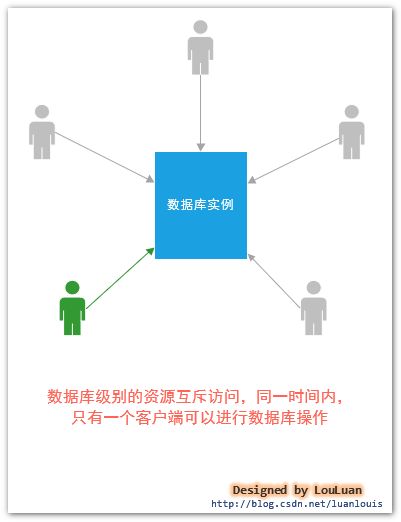
当客户端访问数据库时,各个客户端以互斥的方式进行访问。交互方式如下图所示:
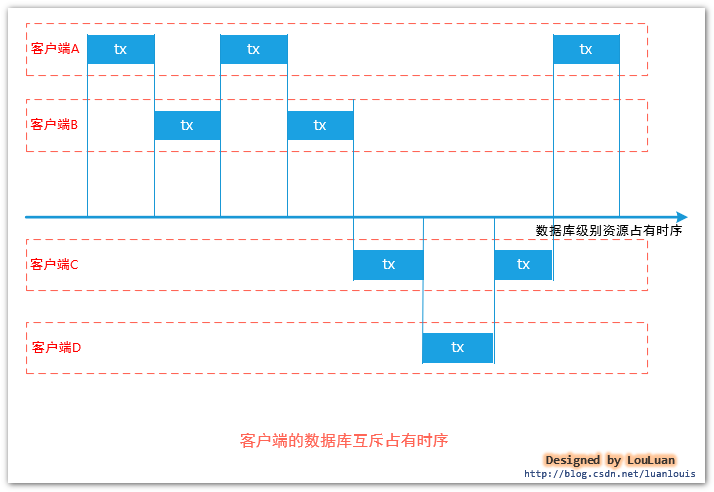
这种级别的隔离方式时最理想的,肯定不会存在不同的客户端事务相应影响的情况,因为,所有的客户端在事务操作时,都是以排队的形式进行的。
数据库除了在理论上的严谨性之外,还要看它的实用性。 下面我们介绍下数据库性能的一个衡量标准:TPS: 单位时间内的事务数(Transactions Per Second),TPS越高,表示数据库的性能越好。
在后续的介绍中,将会使用这一指标来衡量每一个隔离级别的性能。
假设每个客户端的每次事务操作耗时为 T 秒,并且期间没有空闲,那么此时数据库的最大TPS能力就是1/T。
最大TPS = 1 / T (T 为客户端的平均事务操作时间)
例如:T = 10ms, 那么数据库此时的TPS值 为 1 / 0.01 = 100, 即数据库每秒能够完成100个事务操作
合理性讨论:使用数据库级别作为互斥资源,有这么必要吗?
使用数据库级别作为互斥资源访问,确实能够完全保证事务的隔离性;但是,在实际的应用场景中,使用这种粗粒度的互斥资源没有必要。
举例:假设数据库
mall中有两张表:t_user、t_order; 而外部共有4个客户端A、B、C、D。其中,A和B客户端只操作了t_user表,C和D客户端只操作了t_order表。
从互斥资源的角度上来讲,客户端访问互斥资源的情况,分别有两对互斥:A <--t_user--> B 、C<--t_order-->D,在做事务隔离控制时,没有必要使用数据库作为互斥资源;可以将互斥资源进行细分,细分到表这一层级。
1.1.2 使用数据库的表作为互斥资源
接着上面的例子,我们将数据库的表作为互斥资源,细分后的交互方式如下所示:

当我们把锁级别放到表级别之后,在时序操作上,会有两个资源互斥组t_user-[A,B]、t_order-[C,D], 这两个互斥组之间不会受到相互影响,可以并行处理,并行的结果如下图所示:

由于将资源的互斥级别 从
数据库级别细化到
表级别,数据库的TPS数量也提升了不少,下面我们简单估算一下满负荷状态下的TPS,还是假设客户端的平均事务操作的耗时为T,资源互斥组数量为N,那么:
最大TPS = (1 / T)* N
本例中,若T= 10ms ,N = 2,那么:TPS = (1 / 0.01) * 2 = 200
和将数据库作为互斥资源对比,可以看到,有如互斥粒度降到表级别,TPS也跟着提高。
注意:在真实的事务操作中,可能一个客户端事务会操作多张表,那这多张表的任意一张表都会被当做互斥资源。
在目前主流数据库的实现上,基本上都提供了
锁表的方式提供资源互斥资源访问,通过锁全表的方式进行的事务隔离处理,在操作时序上,是排队性质进行的,这种事务隔离的级别最高,即:序列化读(SERIALIZABLE READ)。
我们可以简单地来理解序列化读的实现方式:锁全表
锁全表的方式会导致对同一个表操作的客户端事务操作变成排队性质的序列化操作。现在看下另外一个场景:
假设现在有客户端A和客户端B,在事务操作时,共同使用一张表T_USER,但是他们操作的行信息有所不同:
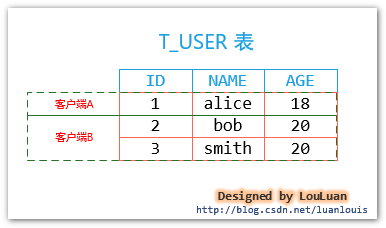
上图中,虽然
客户端A和
客户端B 以互斥的方式访问表
T_USER,但是操作的数据并没有真正的互斥,那我们可以继续将锁的粒度细化,从
锁表这一级,再次细化到
锁行记录这一级,这将进一步提高系统的并发处理能力。经过
行锁细化后,其隔离级别就降到了
可重复读。
1.2 可重复读(REPEATABLE_READ)
将上述的例子展开,通过模型的方式体现,如下图所示:
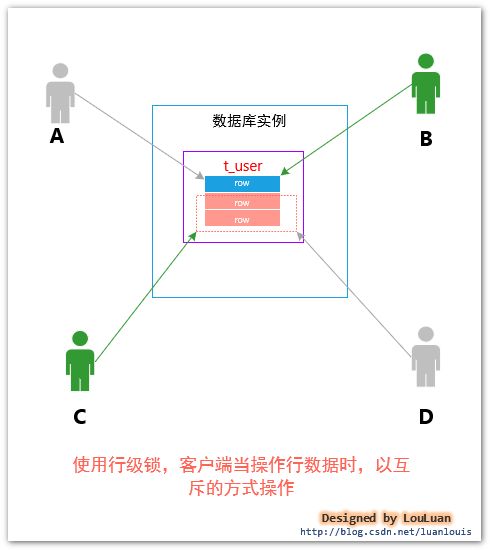
客户端A和客户端B同时尝试访问相同的行数据;而客户端C和客户端D也是同时尝试访问相同的行数据。在此竞争过程中,可以看到,最多可以有两个客户端可以同时访问表T_USER,和序列化读相比,整个客户端的并发量又提高了一个量级!
用客户端时序关系表示如下:
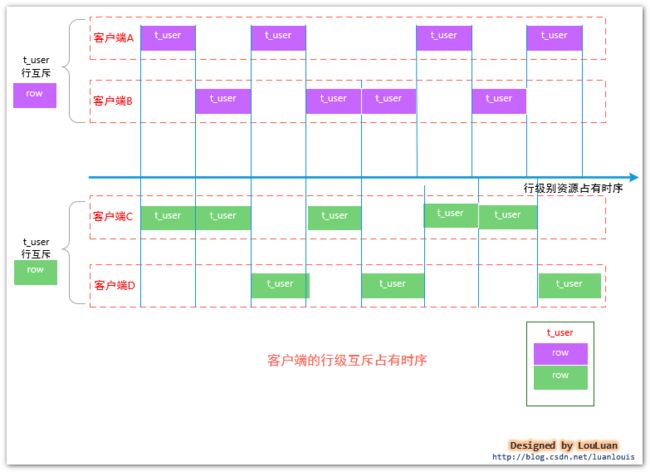
看到这个结果,是不是有这样的感觉:哇塞,既然使用行锁并发能力这么高,为什么还要 锁表方式的序列化读(SERIALIZABLE READ)?
解答这个问题之前,我们来看下这种行锁方式有什么问题。
通过行锁的方式,能够锁定客户端锁操作的行;而在事务进行的过程中,可能会往对应的表中插入新的数据,而这个新的数据,起初并不数据锁定范围,使用SQL语句操作数据库数据时,可能会返回更多的满足条件的数据,加入新的行锁,如下图所示:
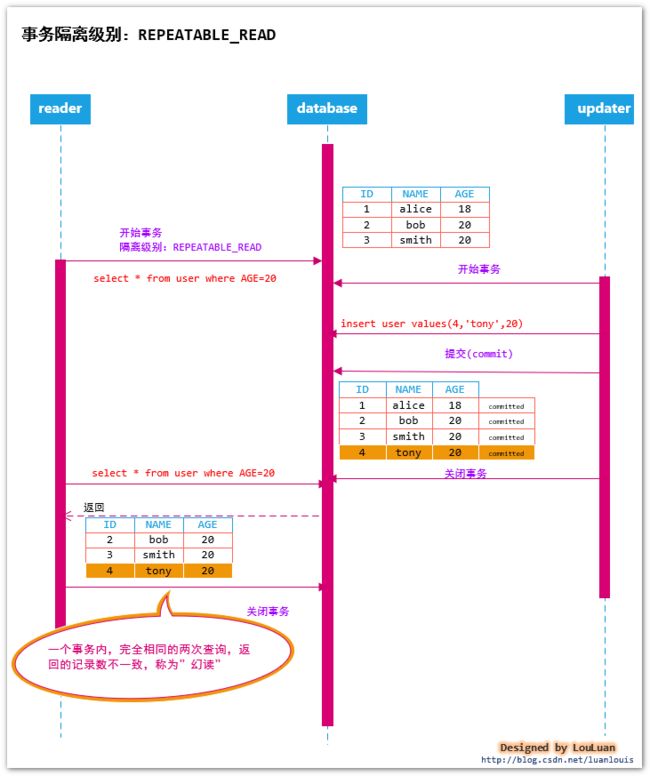
如上图所示:在同一个事务内,完全相同的两次查询,返回的记录数不一致,好像多读了数据一样,这种情况,称为幻读(Phantom Read)
使用这种行锁的方式进行资源隔离的方式,在数据库隔离级别上被称为 可重复读 (REPEATABLE READ)
注意:虽然使用行锁互斥的方式进行数据库操作,但是会出现
幻读的情况,避免幻读的方式,可以使用表级锁---即提高事务的隔离界别---序列化读(SERIALIZABLE READ)
1.3 读已提交(READ_COMMITTED)
实际上,数据库在实现原子性(Atomic)时,对于某一表的特定行,其实有两个状态:Uncommited、Commited,我们将资源在行数据的基础上继续细分,如下图所示:
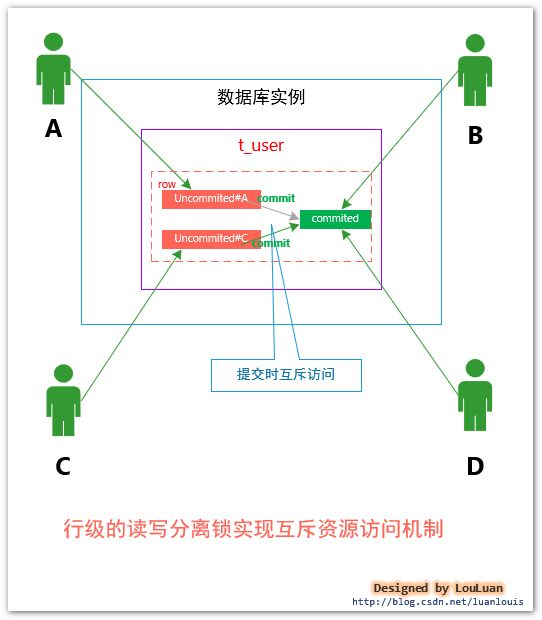
为了进一步提高数据库的并发能力,如上图所示,将在某一行数据上,使用读写分离锁的机制:客户端B和客户端D直接使用读锁读取数据,读锁是共享锁,所以可以同时进行;而客户端A和客户端C 事务操作上,会存在两个环节:Uncommited---> Commited,在真正 commit的时候,则使用写锁以互斥的方式完成事务,把互斥访问资源的时机压缩的更短。
上述的客户端B和客户端D只读取已提交的数据的方式,在隔离级别中,被称为读已提交(READ_COMMITED).
通过上述的流程,我们的数据库的并发能力又能提高一个量级,一切是多么“美好”!
但是这个只是想象中的美好而已,接下来看它存在的问题。假设我们有如下的数据库操作:
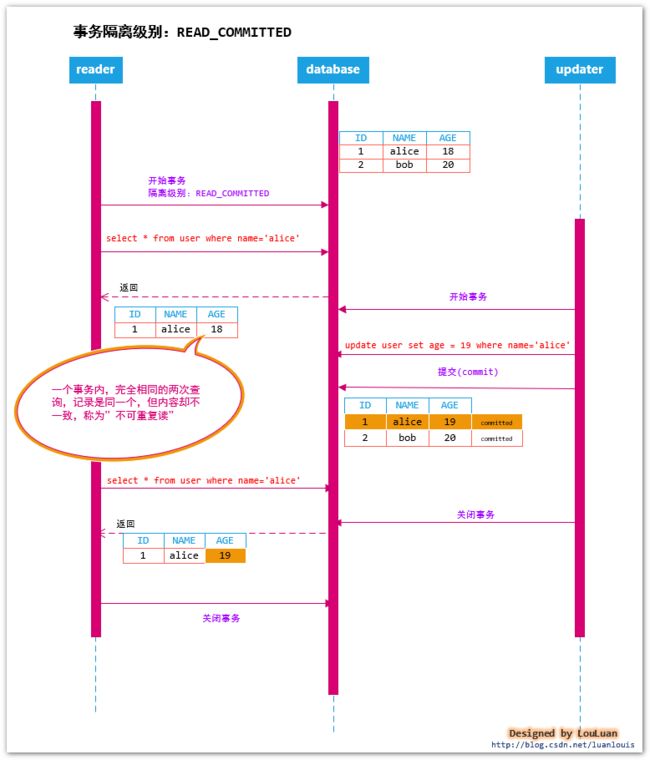
上述的例子中,reader在一个事务中,相同的查询条件,返回的行记录是同一条,但是这一条的记录的AGE列值从18变成19,虽然是相同的行记录,但是内容不一致,这种现象叫做不可重复读(NO-REPEATABLE-READ)。
虽然读已提交(READ COMMITED)隔离级别的并发读能力提高了很多个量级,但是在一个事务内,会造成不可重复读(NO-REPEATABLE-READ)的情况。
读已提交的不可重复读现象对开发同学有什么启示?
不可重复读会导致一条行数据两次读取数据可能不一致,这就要求我们在数据库事务操作上,尽可能少用查询出来的结果作为参数执行后续的updateSQL 语句,尽可能使用状态机来保证数据的完整性。这方面的知识可以单独开一个课题来讨论 :如何使用数据库来保证业务数据的逻辑完整性?
1.4 读未提交(READ_UNCOMMITTED)
上述的读已提交(READ_COMMITTED)的本质,是将资源互斥访问的粒度控制到 committed的行数据上,而实际上,还可以继续将资源互斥的访问粒度,细化到未提交(UNCOMMITED)的行数据上,如下图所示:
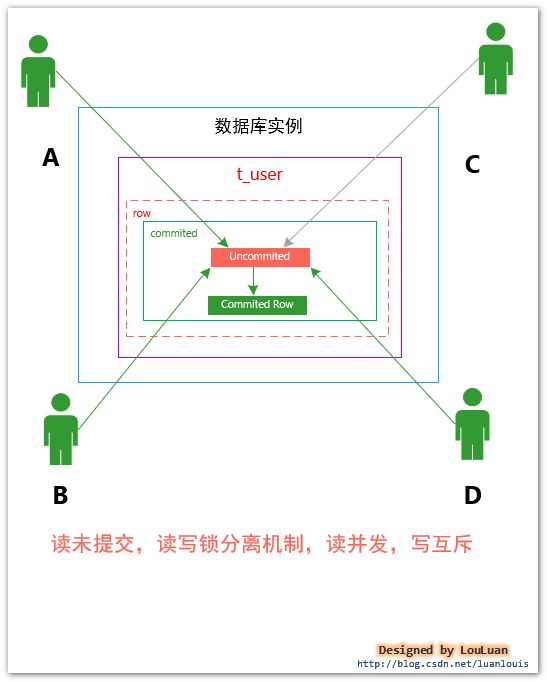
这种方式,由于更细化了资源锁的粒度,其客户端的并发能力又得到了进一步的提升。但是,与此同时,会存在新的问题---脏读现象,具体流程示例如下图所示:
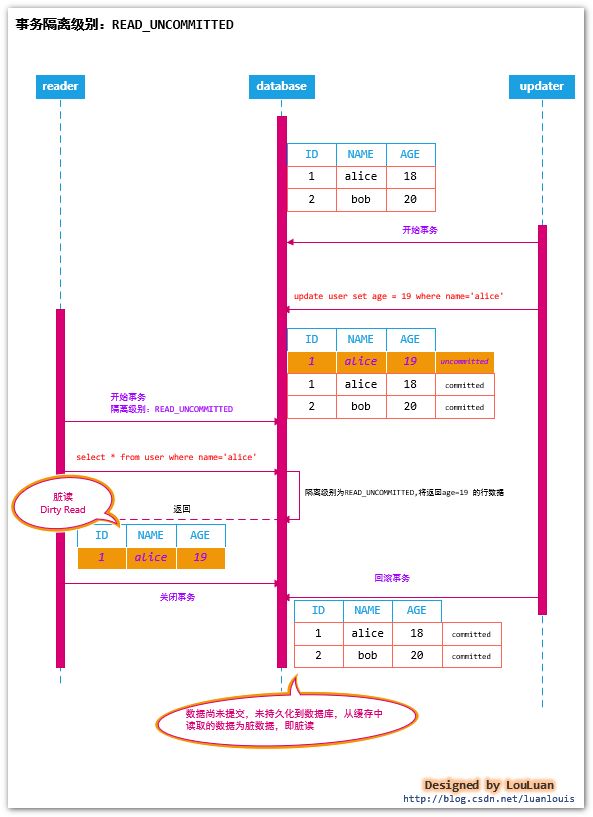
如上图所示:客户端reader在事务的过程中,读取到了其他客户端updater尚未提交的数据,之后客户端reader 可能将其当做已经持久化的数据进行业务操作,而实际上,客户端updater可能将其数据回退;在此过程中,客户端reader读取的数据就成了脏数据,客户端reader的读数据行为为:脏读(Dirty Read)
1.5 小结
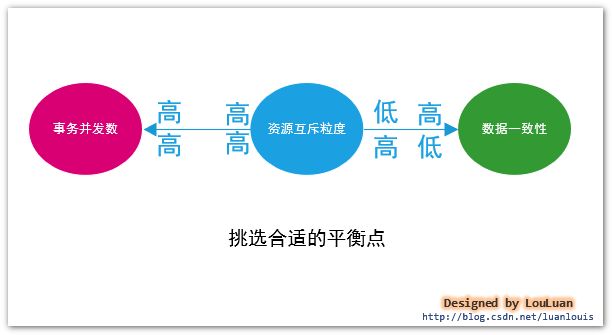
对上述的四种事务隔离级别的阐述中,我们使用了从资源互斥访问的角度做了解释。资源互斥粒度控制的越细,客户端事务的并发能力就越高,但是与此同时,会相应地降低数据的一致性。
事务的并发数和数据数据一致性这两个是两个相反的理想指标。而数据库研发的方向就是尽可能提高同时提高两个指标,尽可能减少之间的反作用影响。
2. 数据库隔离级别和数据一致性的关系
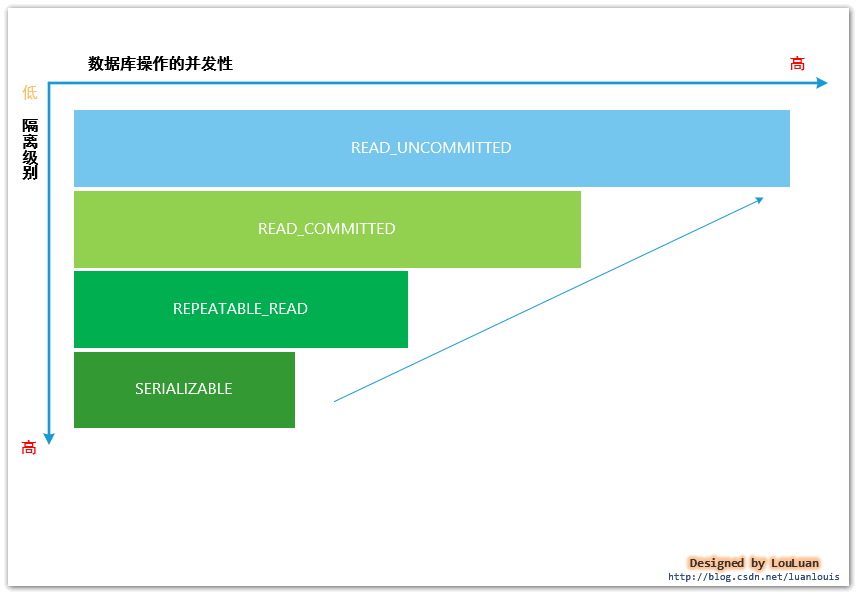
数据库的隔离级别一般分为四个级别,从隔离级别由高到低排序的话,分别是:SERIALIZABLE ---> REPEATABLE READ---> READ_COMMITTED --->READ_UNCOMMITED,其分别表示如下几种含义:
-
SERIALIZABLE序列化读,隔离级别最高,客户端以互斥的方式访问数据库资源,统一时间内,同一个资源只能被一个客户端访问,好像客户端在排队请求访问,所以称为序列化读。 -
REPEATABLE_READ可重复读,可重复读能够保证,一个客户端在一个事务内,多次访问同一个资源时,返回结果是一样的,顾名思义,称为可重复读,这种隔离级别可能会造成幻读现象。 -
READ_COMMITTED读已提交,即客户端在一个事务内,每次查询读取的数据都是从数据库读取最新的已提交的数据;这种隔离界别可能会造成不可重复读和幻读现象。 -
READ_UNCOMMITTED读未提交,即客户端在一个事务内,可以读取到其他客户端事务的尚未提交的数据;这种隔离级别可能会造成脏读、不可重复读、幻读现象。
 隔离级别和数据一致性矩阵图
隔离级别和数据一致性矩阵图
数据库之所以有四种隔离级别,是基于对应的并发能力相关,如下图所示,隔离级别越高,数据库的并发处理能力就越低;反之,隔离级别越低,数据库的并发处理能力就越高。
3. 总结
本文通过资源的角度从上到下分析了数据库隔离级别设计的基本理念,以及相应的数据一致性的关系,帮助大家对数据库隔离级别有更清晰的认识。
关注我的公众号,持续精品好文推送~
