事件分发机制
ACTION_DOWN

结论:
- 对于 dispatchTouchEvent,onTouchEvent,return true是终结事件传递。return false 是回溯到父View的onTouchEvent方法。
- ViewGroup 想把自己分发给自己的onTouchEvent,需要拦截器onInterceptTouchEvent方法return true 把事件拦截下来。
- ViewGroup 的拦截器onInterceptTouchEvent 默认是不拦截的,所以return super.onInterceptTouchEvent()=return false;
- View 没有拦截器,为了让View可以把事件分发给自己的onTouchEvent,View的dispatchTouchEvent默认实现(super)就是把事件分发给自己的onTouchEvent。
关于ACTION_MOVE 和 ACTION_UP
结论1:你在执行ACTION_DOWN的时候返回了false,后面一系列其它的action就不会再得到执行了。简单的说,就是当dispatchTouchEvent在进行事件分发的时候,只有前一个事件(如ACTION_DOWN)返回true,才会收到ACTION_MOVE和ACTION_UP的事件。
结论2:如果在某个控件的dispatchTouchEvent 返回true消费终结事件,那么收到ACTION_DOWN 的函数也能收到 ACTION_MOVE和ACTION_UP。
结论3:在哪个View的onTouchEvent 返回true,那么ACTION_MOVE和ACTION_UP的事件从上往下传到这个View后就不再往下传递了,而直接传给自己的onTouchEvent 并结束本次事件传递过程。
HashMap
equals和==的区别
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作
equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。
快速排序
https://bbs.csdn.net/topics/392461831
冒泡排序
recyclerVeiw 缓存机制
https://www.jianshu.com/p/9306b365da57
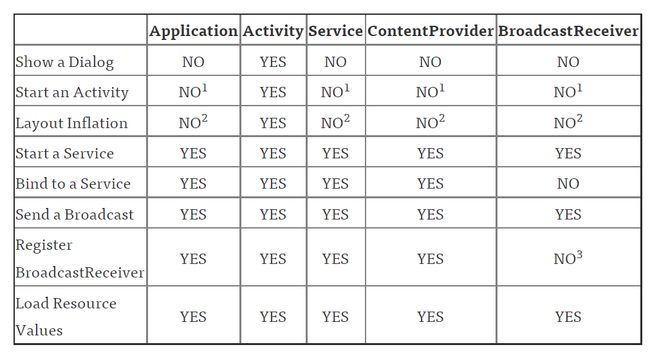
Context
Context 直接子类
Application、Activity和Service
那么Context到底可以实现哪些功能呢?这个就实在是太多了,弹出Toast、启动Activity、启动Service、发送广播、操作数据库等等等等都需要用到Context。由于Context的具体能力是由ContextImpl类去实现的,因此在绝大多数场景下,Activity、Service和Application这三种类型的Context都是可以通用的。不过有几种场景比较特殊,比如启动Activity,还有弹出Dialog。出于安全原因的考虑,Android是不允许Activity或Dialog凭空出现的,一个Activity的启动必须要建立在另一个Activity的基础之上,也就是以此形成的返回栈。而Dialog则必须在一个Activity上面弹出(除非是System Alert类型的Dialog),因此在这种场景下,我们只能使用Activity类型的Context,否则将会出错。
MyApplication myApp = (MyApplication) context.getApplicationContext();
MyApplication myApp = (MyApplication) getApplication();
区别:
实际上这两个方法在作用域上有比较大的区别。getApplication()方法的语义性非常强,一看就知道是用来获取Application实例的,但是这个方法只有在Activity和Service中才能调用的到。那么也许在绝大多数情况下我们都是在Activity或者Service中使用Application的,但是如果在一些其它的场景,比如BroadcastReceiver中也想获得Application的实例,这时就可以借助getApplicationContext()方法了
Handler消息机制
描述:在多线程的应用场景中,将工作线程中需更新UI的操作信息 传递到 UI主线程,从而实现 工作线程对UI的更新处理,最终实现异步消息的处理
Handler:主线程与子线程的通信媒介
Looper:消息队列与处理者的通信媒介,
作用:从消息队列获取消息,将消息发送给处理者
注意:每个线程中只能有一个Looper,一个Looper可以绑定多个Handler,即多个线程可往一个Looper所持有的消息队列发送消息,提供线程间通信的可能
为什么主线程的Looper循环不会让程序崩溃?
ActivityThread 是主线程的入口,一个程序的 main 方法执行完成, 便代表着这个程序运行结束, 那么要使 application 一直得到运行,直到用户退出才结束程序, 那么我们势必得阻塞这个线程, 如果不阻塞, 一个APP 刚启动, main 方法结束,直接退出。
那么这个阻塞就是通过 Looper.loop() 来实现的
/**
* Run the message queue in this thread. Be sure to call
* {@link #quit()} to end the loop.
*/
public static void loop() {
final Looper me = myLooper();
...
final MessageQueue queue = me.mQueue;
...
for (;;) {
Message msg = queue.next(); // might block ---注意此处
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
...
try {
msg.target.dispatchMessage(msg); // 注意此处
end = (slowDispatchThresholdMs == 0) ? 0 : SystemClock.uptimeMillis();
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
}
}
我们看到这个方法在获取到调用这个方法的线程(即主线程)的 looper 后, 再通过 looper获取了 messageQueue,然后进入了一个死循环,我们看到官方的注释, 在 queue.next() 处, might block (当 messageQueue 为空时), 所以此时主线程就阻塞在这个地方了, 从而导致 main方法不会得到退出而因此避免掉 APP 一启动就 jj.
那么问题来了, 既然阻塞了主线程,那又是如何响应用户操作和回调 activity 的生命周期的方法的呢?
那是因为此时 messageQueue 中并没有消息, 因此主线程处于休眠状态,无需占用 cpu 资源, 而当 messageQueue 中有消息时, 系统会唤醒主线程,来处理这条消息.
那么我们在主线程中耗时为什么会造成 ANR 异常呢?
那是因为我们在主线程中进行耗时的操作是属于在这个死循环的执行过程中, 如果我们进行耗时操作, 可能会导致这条消息还未处理完成,后面有接受到了很多条消息的堆积,从而导致了 ANR 异常.
执行完Looper.prepareMainLooper() 之后,主线程从普通线程转成一个Looper线程。
Looper构造,时候给当前线程创建了消息队列MessageQueue,并且让Looper持有MessageQueue的引用。
Handler与looper关联
在Handler构造函数的时候会持有这个线程的Looper引用和这个线程的消息队列的引用,因为持有这个线程的消息队列的引用,意味着这个Handler对象可以在任意其他线程给该线程的消息队列添加消息,也意味着Handler的handlerMessage 肯定也是在该线程执行的
LruCache
https://blog.csdn.net/guolin_blog/article/details/9316683
[https://blog.csdn.net/u013637594/article/details/81866582]
LruCache内部原理的实现需要用到LinkHashMap
由此可见LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队尾元素,即最近最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队头。
RecyclerView 性能优化
https://www.jianshu.com/p/aedb2842de30
数据处理与视图绑定分离
bindViewHolder方法是在UI线程进行的,如果在该方法进行耗时操作,将会影响滑动的流畅性。数据优化
分页拉取远端数据,对拉取下来的远端数据进行缓存,提升二次加载速度;对于新增或者删除数据通过 DiffUtil 来进行局部刷新数据,而不是一味地全局刷新数据。布局优化
减少过渡绘制
减少 xml 文件 inflate 时间
减少 View 对象的创建
Rxjava操作符分类
- 转换操作符
- 过滤操作符
- 组合操作符
转换操作符
- map
它的作用就是对上游发送的每一个事件应用一个函数, 使得每一个事件都按照指定的函数去变化
Observable.create(new ObservableOnSubscribe() {
@Override
public void subscribe(ObservableEmitter emitter) throws Exception {
emitter.onNext(1);
emitter.onNext(2);
emitter.onNext(3);
}
}).map(new Function() {
@Override
public String apply(Integer integer) throws Exception {
return "This is result " + integer;
}
}).subscribe(new Consumer() {
@Override
public void accept(String s) throws Exception {
Log.d(TAG, s);
}
});
FlatMap
FlatMap将一个发送事件的上游Observable变换为多个发送事件的Observables,然后将它们发射的事件合并后放进一个单独的Observable里.
组件化的方案
- 集成模式:所有的组件被“app壳工程依赖”,组成一个完整的App
- 组件模式:可以独立开发的业务组件,每一个业务组件就是一个App
- app空壳工程:负责管理各个业务组件,和打包apk,没有具体的业务功能
- Common组件:属于功能组件,支持业务组件的基础,为业务组件提供需要的功能,例如网络请求,被各个业务组件依赖;
- 业务组件A:根据公司的业务而独立形成的一个工厂
- 功能组件:提供App开发的某些基础功能,如打印日志
- Main组件:也属于业务组件,指定App启动页面,主界面
实施流程图:

需要注意的点:
- application 属性和library属性
- 组件之间AndroidManifest合并问题
- 全局Context的获取及组件数据初始化
- library依赖问题
主要排除v4包跟support包问题 - 组件之间调用和通信
采用路由 - 组件之间资源名冲突
res文件命名最好是以组件名字开头
Android组件
[https://juejin.im/post/5c9867075188254c8c7eae73][https://www.jianshu.com/p/fe509262a1f7]
okHttp
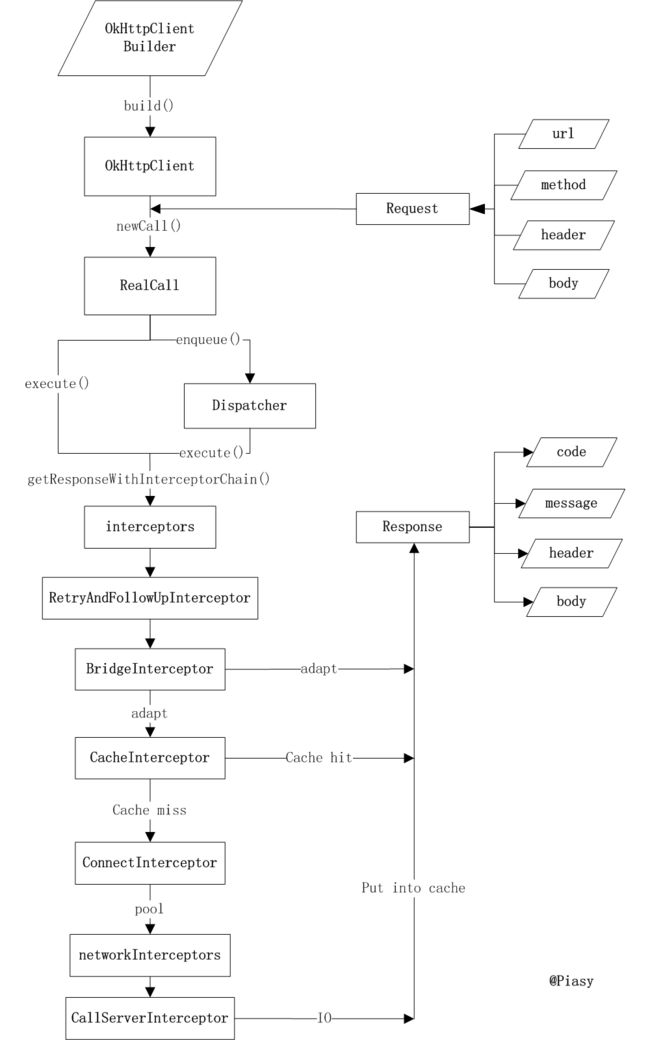
Dispatcher:
- 同步
Dispatcher在执行同步的Call:直接加入到runningSyncCall队列中,实际上并没有执行该Call,而是交给外部执行
/** Used by {@code Call#execute} to signal it is in-flight. */
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
- 异步
将Call加入队列:如果当前正在执行的call的数量大于maxRequest(64),或者该call的Host上的call超过maxRequestsPerHos(5),则加入readyAsyncCall排队等待,否则加入runningAsyncCalls并执行
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}
从ready到running,在每个call结束的时候都会调用finished
private void finished(Deque calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
//每次remove完后,执行promoteCalls来轮转。
if (promoteCalls) promoteCalls();
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
//线程池为空时,执行回调
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
private void promoteCalls() {
//如果当前执行的线程大于maxRequests(64),则不操作
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
for (Iterator i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
大家可以知道finished先执行calls.remove(call)删除call,然后执行promoteCalls(),在promoteCalls()方法里面:如果当前线程大于maxRequest则不操作,如果小于maxRequest则遍历readyAsyncCalls,取出一个call,并把这个call放入runningAsyncCalls,然后执行execute。在遍历过程中如果runningAsyncCalls超过maxRequest则不再添加,否则一直添加。所以可以这样说:
promoteCalls()负责ready的Call到running的Call的转化
具体的执行请求则在RealCall里面实现的,同步的在RealCall的execute里面实现的,而异步的则在AsyncCall的execute里面实现的。里面都是调用RealCall的getResponseWithInterceptorChain的方法来实现责任链的调用。
okHttp缓存机制
CacheControl对应HTTP里面的CacheControl
public final class CacheControl {
private final boolean noCache;
private final boolean noStore;
private final int maxAgeSeconds;
private final int sMaxAgeSeconds;
private final boolean isPrivate;
private final boolean isPublic;
private final boolean mustRevalidate;
private final int maxStaleSeconds;
private final int minFreshSeconds;
private final boolean onlyIfCached;
private final boolean noTransform;
/**
* Cache control request directives that require network validation of responses. Note that such
* requests may be assisted by the cache via conditional GET requests.
*/
public static final CacheControl FORCE_NETWORK = new Builder().noCache().build();
/**
* Cache control request directives that uses the cache only, even if the cached response is
* stale. If the response isn't available in the cache or requires server validation, the call
* will fail with a {@code 504 Unsatisfiable Request}.
*/
public static final CacheControl FORCE_CACHE = new Builder()
.onlyIfCached()
.maxStale(Integer.MAX_VALUE, TimeUnit.SECONDS)
.build();
}
- noCache()
对应于“no-cache”,如果出现在 响应 的头部,不是表示不允许对响应进行缓存,而是表示客户端需要与服务器进行再次验证,进行一个额外的GET请求得到最新的响应;如果出现请求头部,则表示不适用缓存响应,即记性网络请求获取响应。 - noStore()
对应"max-age",设置缓存响应的最大存货时间。如果缓存响满足了到了最大存活时间,那么将不会再进行网络请求 - 、maxAge(int maxAge,TimeUnit timeUnit)
对应"max-age",设置缓存响应的最大存货时间。如果缓存响满足了到了最大存活时间,那么将不会再进行网络请求 - maxStale(int maxStale,TimeUnit timeUnit)
对应“max-stale”,缓存响应可以接受的最大过期时间,如果没有指定该参数,那么过期缓存响应将不会被使用 - minFresh(int minFresh,TimeUnit timeUnit)
对应"min-fresh",设置一个响应将会持续刷新最小秒数,如果一个响应当minFresh过去后过期了,那么缓存响应不能被使用,需要重新进行网络请求 - 、onlyIfCached()
对应“onlyIfCached”,用于请求头部,表明该请求只接受缓存中的响应。如果缓存中没有响应,那么返回一个状态码为504的响应。
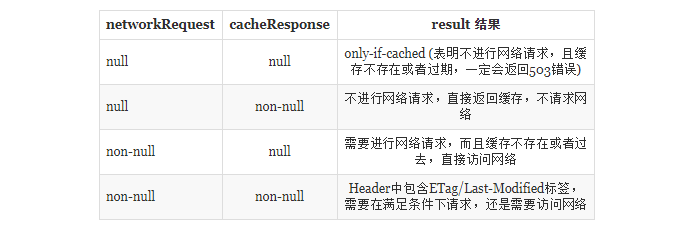
CacheStrategy类详解
OKHTTP使用了CacheStrategy实现了上面的流程图,它根据之前缓存的结果与当前将要发送Request的header进行策略,并得出是否进行请求的结果。
策略原理
CacheInterceptor 类详解
CacheInterceptor 负责将请求和返回 关联的保存到缓存中。客户端和服务器根据一定的机制(策略CacheStrategy ),在需要的时候使用缓存的数据作为网络响应,节省了时间和宽带。
简单的说下上述流程:
1、如果配置缓存,则从缓存中取一次,不保证存在
2、缓存策略
3、缓存监测
4、禁止使用网络(根据缓存策略),缓存又无效,直接返回
5、缓存有效,不使用网络
6、缓存无效,执行下一个拦截器
7、本地有缓存,根具条件选择使用哪个响应
8、使用网络响应
9、 缓存到本地
大体流程分析完,那么咱们再详细分析下。
首先说到了缓存就不得不提下OKHttp里面的Cache.java类和InternalCache.java那么咱们就简单的聊下这两个类
Cache.java类
1、Cache对象拥有一个DiskLruCache引用。
2、Cache构造器接受两个参数,意味着如果我们想要创建一个缓存必须指定缓存文件存储的目录和缓存文件的最大值
cache中包含增,删,改,查

DiskLruCache
