以下列出在时间过程中常用到的几种 Python 脚本操作以及相关功能实现脚本。

一、字符串操作
描述:包括字符串拼接、取子串、拆分、格式化等。
字符串拼接的六种方式
1)通过 “+” 连接多个字符串
s = 'a' + 'b'
print('s = ' + s) // s = ab
Tips:“+” 加号连接符只能拼接两个字符类型数据,不能拼接非 str 类型型,如 int 等数值类型数据。
2)通过 "," ;连接多个字符
s = 'a' + 'b'
print('s =', s, s) // s = ab ab
Tips:打印一个字符可以以多个 “,” 分隔,连接的字符串直接会多出一个空格,所以不用再多加空格。
3)通过 "%" 链接一个字符串和一组变量进行格式化输出
s = '%s is from %s.' % ('Coral', 'China')
print(s) // Coral is from China.
Tips:几种格式化占位符(%s-字符串,%d-整数,%f-浮点数,%x-十六进制),多个占位符就用一个 () tuple 包围。
4)通过字符串函数 join 连接字符串列表
str_list = ['python', 'java']
s = ''
print(s.join(str_list)) // pythonjava
Tips:join 为字符串函数,方法参数为一个列表,通过字符串调用可依次连接列表中的每一个元素。
字符串运算符
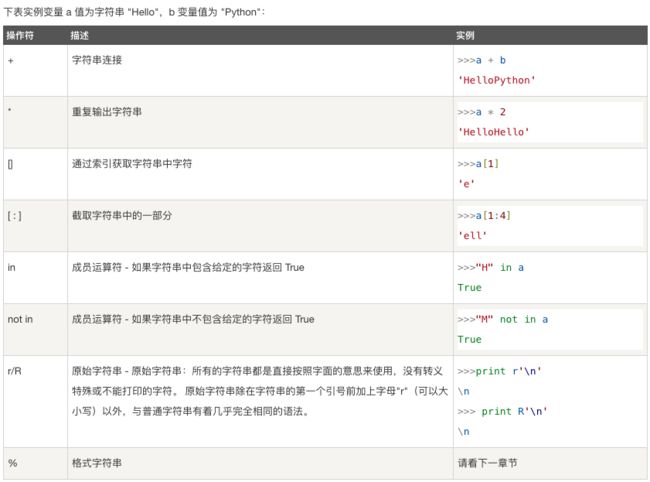
二、集合操作
描述:list、tuple、dict 相关操作
列表list增删查改取值操作
# 定义列表
a_list = []
# 取值
print(a_list[0])
# 遍历列表
for item in a_list:
print(item)
# 新增数据
a_list.append('Google')
# 取列表长度
print(len(a_list))
# 删除某个元素
del a_list[0]
其他高级操作:http://www.runoob.com/python/python-lists.html
元组tuple增删查改取值操作
tuple 中的元素值是不允许修改,所以是不能低元素值进行赋值操作以及新增、删除某个元素,但是可以对元组进行连接组合以及删除整个元组。
# 定义元组
a_tuple = ()
b_tuple = (1, 2)
# 以下修改元组元素时非法操作
# b_tuple[0] = 1
# 连接两个元组为一个新的元组
c_tuple = a_tuple + b_tuple
# 删除整个元组
del a_tuple
字典dict增删查改取值操作
# 1)定义字典
a_dict = {'id': 1, 'name': 'xss'}
# 2)字典元素取值
print(a_dict['id'])
# 3)遍历key
# 方式一
for key in a_dict:
print(a_dict[key])
#方式二(等价于方式一)
key_list = a_dict.keys()
for key in key_list:
print(a_dict[key])
# 4)遍历 value
for value in a_dict.values():
print(value)
# 5)遍历字典项
for k_v in a_dict.items():
print(k_v) # ('id', 1) ('name', 'xss')
# 6)遍历字典key和value
for k, v in a_dict.items():
print(k + ':' + v)
其他操作
如何对集合变量进行判空?
a_list = [] / {} / ()
if not a_list:
print('a_list is not empty')
如何取集合长度?
a_list = [1, 'xs']
a_len = len(a_list)
三、命令行操作
# encoding:utf-8
import re
import os
# python 调用 shell 脚本的两种方式:
# os.system(cmd)
# os.popen(cmd)
# 区别:前者返回值仅为0(成功),1,2;后者会将执行的 cmd 的输出作为返回值,所以如果需要手机返回值则使用第二种执行方式。
# 功能:执行一般shell命令
def execute_cmd(cmd):
os.system(cmd)
# 功能:获取 cmd 命令执行后的结果列表
def get_execute_cmd_result(cmd):
return os.popen(cmd).readlines()
# 功能:获取adb启动activity命令结果列表
def execute_adb_start_cmd(cmd):
outputs = get_execute_cmd_result(cmd)
items = {}
for line in outputs:
m = re.search(r'(.*)(: )(.*)', line.strip())
if m:
# print('---')
# print(m.group(0)) # 完整输出
# print(m.group(1)) # : 前面部分/key
# print(m.group(2)) # :
# print(m.group(3)) # : 后面部分/value
items[m.group(1)] = m.group(3)
return items
四、文件IO操作
# encoding:utf-8
import shutil
import json
import os
'''
方法说明:
- 普通文件直接读写;
- 按行读取文件;
- 拷贝文件;
-----以下为未实现功能-----
- 按字节读取大文件;
- 按字节写入文件;
- 新增 / 删除文件;
- 查找某个目录下的所有子文件;
- 查找某个特定的文件或目录;
'''
def read_file(file_path):
f = open(file_path, 'r')
content = f.read()
f.close()
return content
def read_byte_file(file_path):
f = open(file_path, 'rb')
content = f.read()
f.close()
return content
# 读取 json 文件数据
def read_json_file(file_path):
with open(file_path, 'r') as f:
return json.load(f) # 返回为list类型
# 写入 json 数据
def write_json_content(file_path, data):
with open(file_path, 'w') as f:
json.dump(data, f)
# 按行读取文件内容
def read_file_by_line(file_path):
lines = []
f = open(file_path, 'r')
for line in f.readlines():
lines.append(line.strip())
return lines
# 按字节读取大文件
def read_file_by_byte(file_path, buffer_size):
f = open(file_path, 'r')
result = ''
content = f.read(buffer_size)
result += content
while len(content) > 0:
content = f.read(buffer_size)
result += content
f.close()
return result
# 将某个文件内容按行读到另一个文件中
def write_file(input_file, output_file):
output = open(output_file, 'w')
with open(input_file, 'r') as f:
for line in f.readlines():
output.writelines(line)
def write_content(content, output_file):
output = open(output_file, 'w')
output.write(content)
def write_byte_content(content, output_file):
output = open(output_file, 'wb')
output.write(content)
# 一次性写入
def write_string_content(content, output_file):
output = open(output_file, 'w+')
output.write(content)
# 文件复制
def copy_file(src_file, dist_file):
# 文件复制可使用 shutil
shutil.copyfile(src_file, dist_file)
# 列出某个目录下的文件
def list_file(dir):
files = []
if os.path.isdir(dir):
list_dir = os.listdir(dir)
for f in list_dir:
if os.path.isfile(os.path.join(dir, f)):
print(f)
files.append(f)
return files
# 列出某个目录下的所有文件
def list_all_file(dir):
files = []
if os.path.isdir(dir):
list_dir = os.listdir(dir)
for f in list_dir:
if os.path.isfile(f):
files.append(f)
else:
f = os.path.join(dir, f)
list_all_file(f)
return files
五、函数高级用法
描述:以函数为参数进行传递。
六、Q&A总结
出现中文字符运行不通过问题怎么办?
— 在文件顶行添加 # encoding:utf-8 即可解决字符乱码运行出错问题。Pycharm 中 .py 文件无法相互 import 引用?
— 参考:
https://blog.csdn.net/qq_19339041/article/details/80088237
https://blog.csdn.net/zhanguang000/article/details/53197600如何安装和使用第三方库?
—Python 之所以强大,主要在于其丰富的第三方库。pip 是 python 第三方库的包管理工具。由于 在 mac 上 python2 和 python3 是共存的,所有 python3 对应的包管理工具的命令就是: pip3 。
— 如何安装 pip3 ? 如果通过 homebrew 安装 python3 则同时会安装 pip3,所有可通过 homebrew 安装 python3:
$brew install python3 // no need sudo
# 安装 pip3
$python3 get-pip.py
# 通过 pip3 下载第三方库 lxml
$pip3 install lxml