Hadoop和Spark
Apache Hadoop是一个开源软件库,可以跨计算机集群分布式处理大型数据集。它具有高度可扩展性,可以加载到单个服务器上,也可以分布在数千台不同的机器上。它包括几个模块,包括用于分布式文件存储的Hadoop分布式文件系统(HDFS),用于大数据集并行处理的Hadoop MapReduce,以及用于大规模数据处理(包括统计学习)的通用引擎Spark。
sparklyr
学习使用Hadoop和Spark可能非常复杂。他们使用自己的编程语言来指定函数和执行操作。在本课程中,我们将与Spark进行交互,sparklyr来自Rt的一个包来自RStudio的同一作者和tidyverse。这允许我们:
使用dplyr界面从R连接到Spark
与存储在Spark群集上的SQL数据库进行交互
实施分布式统计 学习算法
有关设置和使用的详细说明,请参见此处sparklyr。
安装
首先你需要安装sparklyr:
install.packages("sparklyr")
您还需要安装本地版本的Spark才能在您的计算机上运行它:
连接到Spark
您可以连接到Spark的本地实例以及远程Spark群集。让我们使用该spark_connect()函数连接到我们计算机上构建的本地集群:
用Spark学习机器
您可以sparklyr在Apache Spark中使用适合各种机器学习算法。caret::train()您可以ml_根据要使用的算法使用一组函数,而不是使用它们。
加载数据
让我们继续使用泰坦尼克号数据集。首先,titanic将包含我们用于过去统计学习练习的数据文件的包加载到本地Spark集群中:
library(titanic)
(titanic_tbl <- copy_to(sc, titanic::titanic_train, "titanic", overwrite = TRUE))
整理数据
您可以使用dplyr语法在Spark中整理和重塑数据,以及Spark机器学习库中的专用函数。
Spark SQL转换
这些是使用Spark SQL的功能转换(也就是对列/行进行改变或过滤)。这允许您在仍然使用dplyr语法的同时创建新列并修改现有列。这里让我们修改4列:
Family_Size - 创造一些兄弟姐妹和父母
Pclass - 将乘客类格式化为字符而不是数字
Embarked - 删除少量丢失的记录
Age - 估计平均年龄的失踪年龄
我们sdf_register()在操作结束时使用将表存储在Spark集群中。
Spark ML转换
Spark还包括几个转换功能的功能。我们可以直接sparklyr访问其中几个。例如,要转换Family_Sizes为垃圾箱,请使用ft_bucketizer()。因为这个函数来自Spark,所以它在内部使用sdf_mutate(),而不是mutate()。
titanic_final_tbl <- titanic2_tbl %>%
mutate(Family_Size = as.numeric(Family_size)) %>%
sdf_mutate(
Family_Sizes = ft_bucketizer(Family_Size, splits = c(1,2,5,12))
) %>%
mutate(Family_Sizes = as.character(as.integer(Family_Sizes))) %>%
sdf_register("titanic_final")
> ft_bucketizer()等同cut()于R.
数据拆分
随机将数据划分为训练/测试集。
训练模型
Spark ML包括几种类型的机器学习算法。我们可以使用这些算法来使用训练数据拟合模型,然后使用测试数据评估模型性能。
逻辑回归
Model survival as a function of several predictors
ml_formula <- formula(Survived ~ Pclass + Sex + Age + SibSp +
Parch + Fare + Embarked + Family_Sizes)
# Train a logistic regression model
(ml_log <- ml_logistic_regression(train_tbl, ml_formula))
其他机器学习算法
使用其他机器学习算法运行相同的公式。请注意,方法之间的培训时间差异很大。
验证数据
比较结果
要选择最佳模型,请通过检查性能指标(电梯,精度和曲线下面积(AUC))来比较测试集结果。
模型升降机
Lift比较模型与随机猜测相比预测生存的程度。下面的函数计算测试数据中每个评分十分位数的模型升力
# Lift function
calculate_lift <- function(scored_data) {
scored_data %>%
mutate(bin = ntile(desc(prediction), 10)) %>%
group_by(bin) %>%
summarize(count = sum(Survived)) %>%
mutate(prop = count / sum(count)) %>%
arrange(bin) %>%
mutate(prop = cumsum(prop)) %>%
select(-count) %>%
collect() %>%
as.data.frame()
}
Initialize results
ml_gains <- data_frame(
bin = seq(from = 1, to = 10),
prop = seq(0, 1, len = 10),
model = "Base"
)
Calculate lift
for(i in names(ml_score)){
ml_gains <- ml_score[[i]] %>%
calculate_lift %>%
mutate(model = i) %>%
bind_rows(ml_gains, .)
}
Plot results
ggplot(ml_gains, aes(x = bin, y = prop, color = model)) +
geom_point() +
geom_line() +
scale_color_brewer(type = "qual") +
labs(title = "Lift Chart for Predicting Survival",
subtitle = "Test Data Set",
x = NULL,
y = NULL)
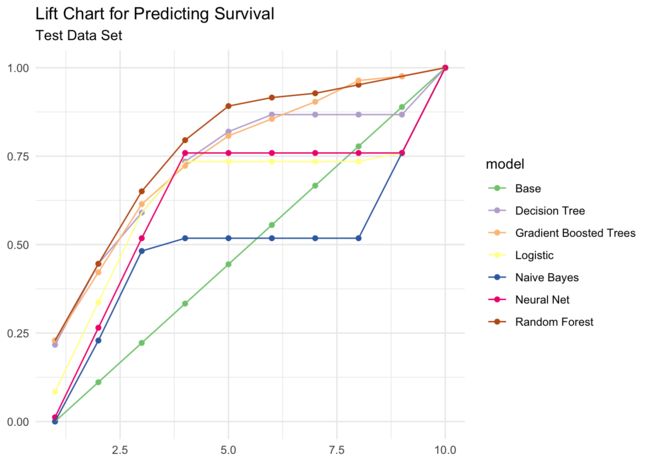
提升图表显示基于树的模型(随机森林,梯度提升树和决策树)提供了最佳预测。
准确性和AUC
接收器操作特性(ROC)曲线是说明二元分类器性能的图形图。他们可视化真阳性率(TPR)与假阳性率(FPR)之间的关系。
理想模型将所有正面结果完美地归类为真假,并将所有负面结果归类为假(即TPR = 1且FPR = 0)。第二个图上的线是通过计算不同切点阈值(即.1,.2,.5,.8)的预测结果而得出的。0.1,0.2,0.5,0.8并连接点。如果您随机猜测,对角线表示预期的真/假阳性率。曲线下面积(AUC)总结了模型同时在这些阈值点上的良好程度。面积为1表示对于任何阈值,模型总是做出完美的前奏。这几乎不会发生在现实生活中。良好的AUC值介于.6之间0.6和.80.8。虽然我们无法使用Spark绘制ROC图,但我们可以根据预测提取AUC值。
Function for calculating accuracy
calc_accuracy <- function(data, cutpoint = 0.5){
data %>%
mutate(prediction = if_else(prediction > cutpoint, 1.0, 0.0)) %>%
ml_classification_eval("prediction", "Survived", "accuracy")
}
Calculate AUC and accuracy
perf_metrics <- data_frame(
model = names(ml_score),
AUC = 100 * map_dbl(ml_score, ml_binary_classification_eval, "Survived", "prediction"),
Accuracy = 100 * map_dbl(ml_score, calc_accuracy)
)
perf_metrics
Plot results
gather(perf_metrics, metric, value, AUC, Accuracy) %>%
ggplot(aes(reorder(model, value), value, fill = metric)) +
geom_bar(stat = "identity", position = "dodge") +
coord_flip() +
labs(title = "Performance metrics",
x = NULL,
y = "Percent")

总体而言,基于树的模型表现最佳 - 它们具有最高的准确率和AUC值。
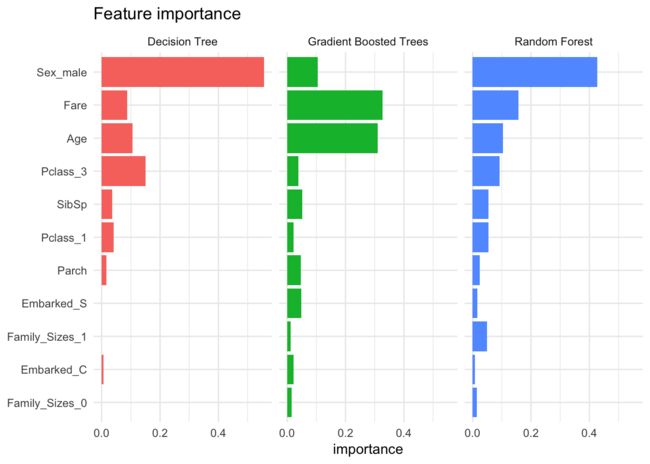
特征重要性
将每个模型确定的特征作为生存的重要预测因子进行比较也很有趣。树模型实现了特征重要性度量(la randomForest::varImpPlot()。性别,票价和年龄是一些最重要的特征。
Initialize results
feature_importance <- data_frame()
Calculate feature importance
for(i in c("Decision Tree", "Random Forest", "Gradient Boosted Trees")){
feature_importance <- ml_tree_feature_importance(ml_models[[i]]) %>%
mutate(Model = i) %>%
rbind(feature_importance, .)
}
Plot results
feature_importance %>%
ggplot(aes(reorder(feature, importance), importance, fill = Model)) +
facet_wrap(~Model) +
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Feature importance",
x = NULL) +
theme(legend.position = "none")
比较运行时间
培训模型的时间很重要。有些算法比其他算法更复杂,因此有时您需要在准确性和效率之间取得平衡。以下代码评估每个模型n时间并绘制结果。请注意,渐变增强树和神经网比其他方法花费更长的时间训练。
Number of reps per model
n <- 10
Format model formula as character
format_as_character <- function(x){
x <- paste(deparse(x), collapse = "")
x <- gsub("\\s+", " ", paste(x, collapse = ""))
x
}
Create model statements with timers
format_statements <- function(y){
y <- format_as_character(y[[".call"]])
y <- gsub('ml_formula', ml_formula_char, y)
y <- paste0("system.time(", y, ")")
y
}
Convert model formula to character
ml_formula_char <- format_as_character(ml_formula)
Create n replicates of each model statements with timers
all_statements <- map_chr(ml_models, format_statements) %>%
rep(., n) %>%
parse(text = .)
Evaluate all model statements
res <- map(all_statements, eval)
Compile results
result <- data_frame(model = rep(names(ml_models), n),
time = map_dbl(res, function(x){as.numeric(x["elapsed"])}))
Plot
result %>%
ggplot(aes(time, reorder(model, time))) +
geom_boxplot() +
geom_jitter(width = 0.4, aes(color = model)) +
scale_color_discrete(guide = FALSE) +
labs(title = "Model training times",
x = "Seconds",
y = NULL)
sparking water(H2O)和机器学习
LOOCV在哪里?k在哪里ķ - 交叉验证?好吧,sparklyr还在开发中。它不允许你做Spark可以做的每一件事。我们上面用来估计模型的函数是Spark的分布式机器学习库(MLlib)的一部分。MLlib包含交叉验证功能 -只是有没有对他们的接口sparklyr 还。1真正的拖累。
如果您认真考虑使用Spark并需要交叉验证和其他更强大的机器学习工具,另一个选择是H2O,一种替代的开源跨平台机器学习软件包。该rsparkling软件包提供了访问H2O的分布式机器学习功能通过sparklyr。H2O具有许多与MLlib相同的功能(如果不是更多sparklyr),但实现它有点复杂。因此,我们将大部分代码集中在MLlib算法上。
H2O和逻辑回归
作为一个快速演示,我们使用H2O估算一个10倍CV的逻辑回归模型。首先,我们需要加载一些额外的包
library(rsparkling)
library(h2o)
我们将重用之前修改的泰坦尼克号表titanic_final_tbl。但是要将它与H2O函数一起使用,我们需要将其转换为H2O数据框:
titanic_h2o <- titanic_final_tbl %>%
mutate(Survived = as.numeric(Survived),
SibSp = as.numeric(SibSp),
Parch = as.numeric(Parch)) %>%
select(Survived, Pclass, Sex, Age, SibSp, Parch, Fare, Embarked, Family_Sizes) %>%
as_h2o_frame(sc, ., strict_version_check = FALSE)
接下来我们可以使用估计逻辑回归模型h2o.glm()。
此函数不使用公式传递独立变量和因变量; 相反,它们作为字符向量参数传递给x和y
family = "binomial" - 确保我们运行逻辑回归,而不是连续因变量的线性回归
training_frame - 包含训练集的数据框(这里我们使用整个数据框,因为我们也使用交叉验证)
lambda_search = TRUE - 优化器函数计算参数值的参数
nfolds = 10 - 使用10倍交叉验证估算模型
glm_model <- h2o.glm(x = c("Pclass", "Sex", "Age", "SibSp", "Parch",
"Fare", "Embarked", "Family_Sizes"),
y = "Survived",
family = "binomial",
training_frame = titanic_h2o,
lambda_search = TRUE,
nfolds = 10)