正则表达式##
py的正则表达式只能通过字符串来表示,配合re模块使用。由于有转义字符的存在,为了简便,一般都会附加r
import re
email = "[email protected]"
print re.match(r"^\w+@(hotmail|126|163|qq|gmail).(com|cn)(.cn)?$", email)
phone = "13918459376"
print re.match(r"^1[3|5|7|8]\d{9}$", phone)
idCard = "310114199101191314"
print re.match(r"(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)", idCard)
当然,re也有匹配分离和提取的功能,通过re.split和match.group(n)来实现
实用模块##
collections
集合类工具模块
- namedtuple:以tuple为基础定义一个类,并未其中的各个分量指定key名
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
p = Point(1, 2)
不过tuple不能改变值,算是个遗憾,不过真正做起来,namedtuple也是不够用的
- deque:链表(不过为何没有中间插入?)
from collections import deque
q = deque([0, 1, 2, 3, 4, 5, 6])
q.append(7)
print q
q.pop()
print q
q.appendleft(-1)
print q
q.popleft()
print q
- defaultdict:带默认值的KV表,当访问不存在的key是返回默认值
from collections import defaultdict
d = defaultdict(lambda: "")
d["id"] = 5
d["name"] = "op"
print d["sex"]
# 打印空字符串
- OrderedDict:排过序的dict,按定义的顺序遍历
from collections import OrderedDict
d = OrderedDict([("z", 12), ("y", 55), ("")])
- Counter:统计字符出现的个数
from collections import Counter
cc = Counter()
for c in "i am a Chinese":
cc[c] += 1
print c
base64
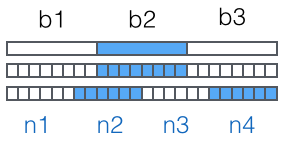
Base64编码过程
对二进制数据,以每次取三个字节数据的规则,依次取数据。这样一次获取的数据是3 8=24bit,再把它分为四组24=46bit,由此得出四个索引(所以字符索引表的最大长度的2^6),根据索引得到对应的字符替换真数据中的字符。所得出的字符串就是Base64编码之后的字符串了。
hashlib
提供哈希加密,MD5、SHA1等。使用和JS无异
itertools
提供操作迭代对象的函数
- count(n):生成n~无限的自然数列
for i in itertools.count(1): # 1 2 3 .....
- cycle([n1, n2, ...]):循环迭代给出的序列
for i in itertools.cycle([1, 2, 3]): # 1 2 3 1 2 3 1 ...
- repeat(n, [max]):循环迭代指定的参数(1),可以通过指定第二个参数控制其迭代的次数
for i in itertools.repeat(1, 5): # 1 1 1 1 1
- chain(a1, a2, ...):相当于Array.concat()
for i in itertools.chain([1, 2, 3], [4, 5, 6]): # 1 2 3 4 5 6
- groupby(n):将序列中相同的项提取出来,迭代的周期返回这个项和项出现的次数(序列)
for ket, group in itertools.groupby("AAABBBCCCCCCDDEE"):
print key, list(group)vv
- imap():可以用来处理无限序列的map版本
- ifilter():可以用来处理无限序列的filter版本
如果用map和filter处理无限序列,会无输出报错
XML
跟一般的XML库一样,分两种解析方式:DOM和SAX,DOM占用的内存消耗大,但一旦解析完成便可以随意操作;SAX的快速解析,遇到什么就输出什么,用事件驱动
HTMLParser
用于解析HTML的接口类,用回调的方式处理遇到的TAG,而且语法没有XML那么严格。编写爬虫会用到
from HTMLParser import HTMLParser
class MyWebPageParser(HTMLParser):
def handle_starttag(self, tag, attrs):
# 处理TAG头
def handle_starttag(self, tag):
# 处理TAG尾
def handle_startendtag(self, tag, attrs):
# 处理单TAG
def handle_data(self, data):
# 处理内容
def handle_comment(self, comment):
# 处理注释
def handle_entityref(self, name):
# 处理引用(估计是PIL(Pillow)##
py的图片处理模块,最新根据官网的文档,通过pip安装Pillow(不再是简写PIL),用from PIL import XXX引入(不再是import Image)
$ pip install Pillow
from PIL import Image
img = Image.open("media/test.jpg")
安装和使用参照:https://pillow.readthedocs.io/en/latest/installation.html
详细参照官方文档:http://effbot.org/imagingbook/