在上一篇关于使用Google Cloud AutoML训练图像标签模型之后,我们将研究如何训练另一种模型来识别和定位图像中的对象,即对象检测模型!
与图像标记(或图像分类)相反,在该模型中,模型根据某些类别或类别标记输入图像,而对象检测模型将改为从图像中检测对象(您已经训练过的对象)及其位置。
下面展示这两种技术之间差异的图片:

如你所见,在正确的图像上,我们不仅得到检测到的物体(狗),而且还得到包含狗的区域周围的边界框。
当您要操作检测到的对象时,此类模型非常有用,例如,可能要从图像中提取狗的图像,并用其他东西替换它。对于这种情况,这种模型和ML任务可能非常有用!
训练这样的模型可能听起来很困难。但值得庆幸的是,为了帮助使机器学习民主化,作者提供了Google的Cloud AutoML Vision,它是Google提供的工具,可以帮助简化这种机器学习模型的训练过程,而无需编写任何代码!
使用AutoML还可以避免使用高端PC来训练模型。您可以将训练过程快速卸载到Google的服务器上,然后将模型的训练后的边缘风格导出为tflite文件,以在Android / iOS应用上运行。
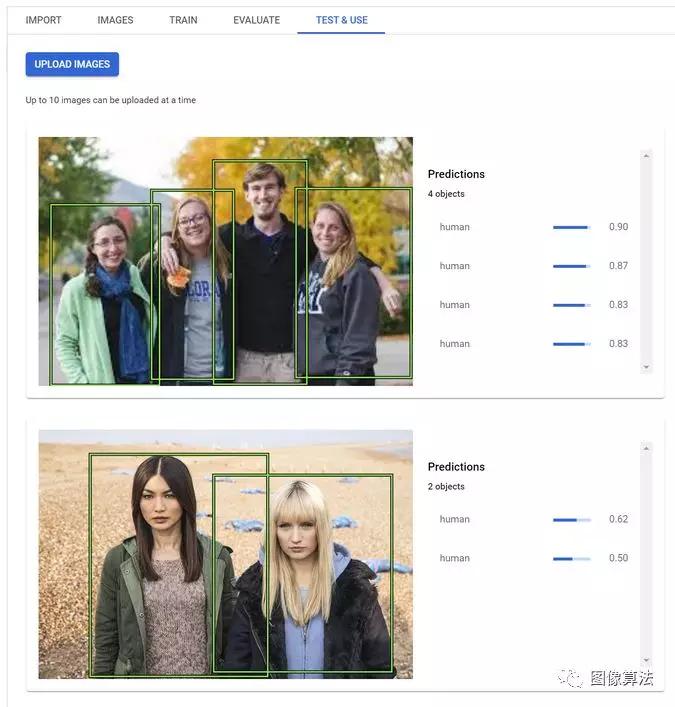
我最近使用该产品为AfterShoot应用训练了一个自定义对象检测模型,该模型可以从给定图像中识别人。模型的运作方式如下:
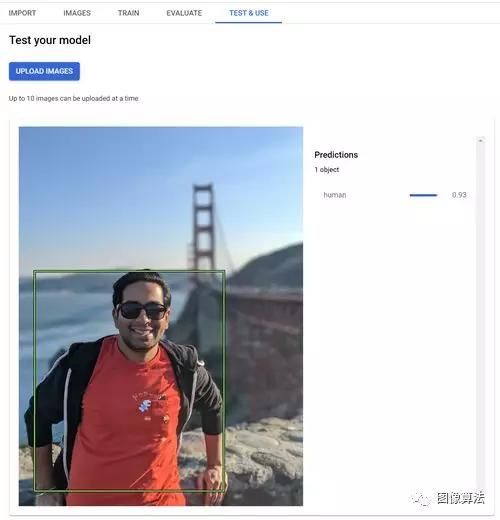
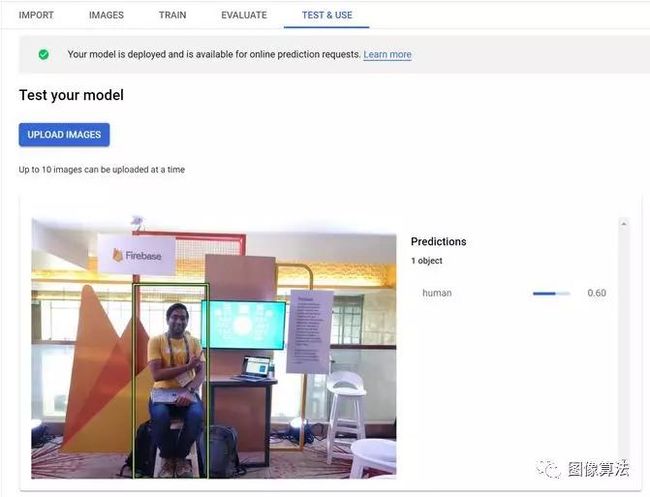
现在,让我们探讨如何在不到30分钟的时间内训练自己的类似模型。
步骤1:建立Google云端专案
转到https://console.cloud.google.com并使用您的帐户登录,或者如果尚未注册,请注册。
您所有的Firebase项目都将Google Cloud的一部分用作后端,因此您可能会在Firebase控制台中看到一些现有项目。从生产中不使用的项目中选择一个,或创建一个新的GCP项目。
步骤2:创建用于对象检测的新数据集
进入控制台后,打开右侧的侧栏并导航至最底部,直到找到“视觉”选项卡。点击那个。
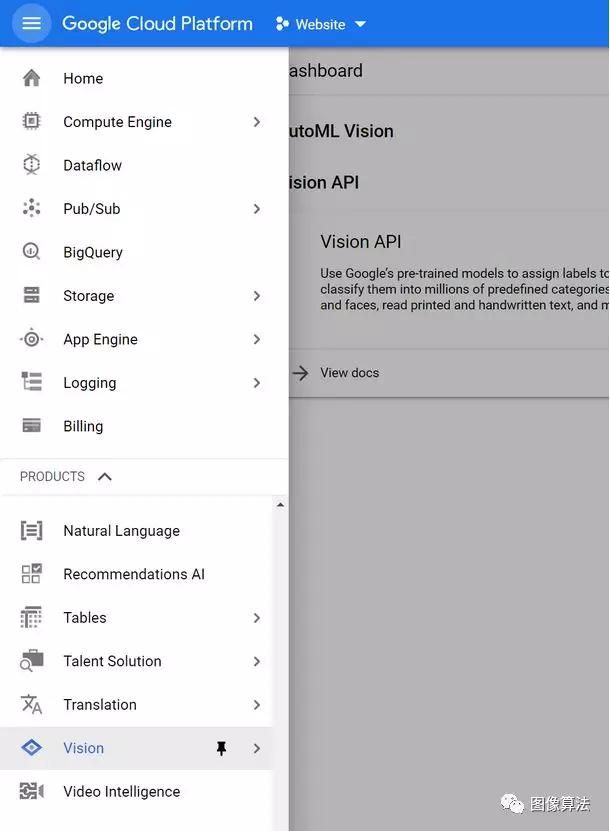
到达此处后,单击“对象检测”卡上显示的“入门”按钮。确保所需的项目显示在顶部的下拉框中:
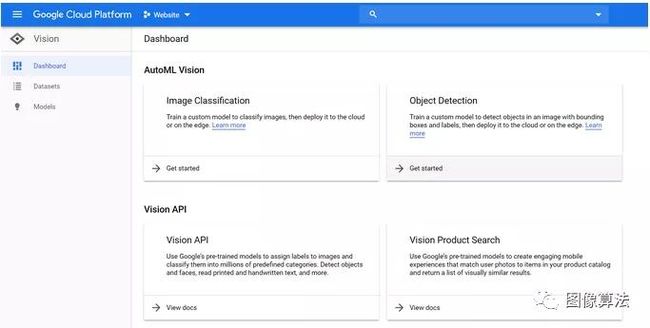
可能会提示您启用AutoML Vision API。您可以通过单击页面上显示的Enable API按钮来实现。
最后,单击“新建数据集”按钮,为其指定一个适当的名称,然后在模型目标中选择“对象检测”。
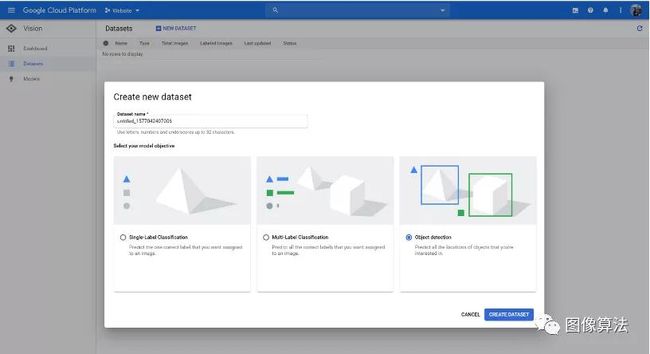
步骤3:导入图片
创建数据集后,系统会要求您上传一些要在训练过程中使用的图像,以及用于存储这些图像的Cloud Storage Bucket的位置。
由于此模型将用于检测人类,因此作者已经准备了一个包含人类图像的数据集。
在本地准备好数据集后,请单击“选择图像”,然后选择要在其上训练模型的所有图像。之后,单击GCS路径旁边的“浏览”按钮,然后选择名为your-project-name.appspot.com的文件夹:
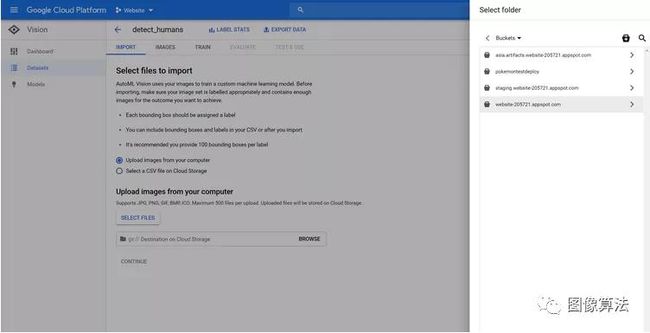
完成后,按“继续”并等待导入过程完成。
步骤4:概述要识别的对象
导入完成后,单击“图像”选项卡,您应该在那里看到所有导入的图像。从此处,单击“添加新标签”按钮,然后命名要在图像中标识的标签。我个人想从图片中识别人,因此我将创建一个称为“人”的标签:
创建标签后,下一步就是教模型人类的模样!为此,请打开导入的图像,并开始在每个图像中的人周围绘制边框:
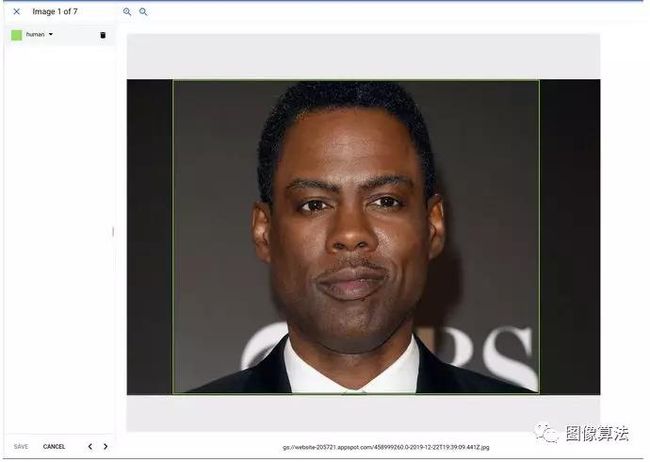
在要检测的对象周围绘制框后,不要忘记保存。
至少需要对10张图片进行此操作,但Google建议您对100张图片进行此操作,以提高准确性。标记了足够的图像后,我们将继续进行下一步。
步骤5:训练TensorFlow Lite模型
注释完足够的图像后,就可以训练模型了。为此,转到“培训”选项卡,然后单击“开始培训”按钮。
单击此按钮后,系统将提示您一些选择。如果要让tflite模型可以在本地运行,请确保选择Edge而不是Cloud-Based。
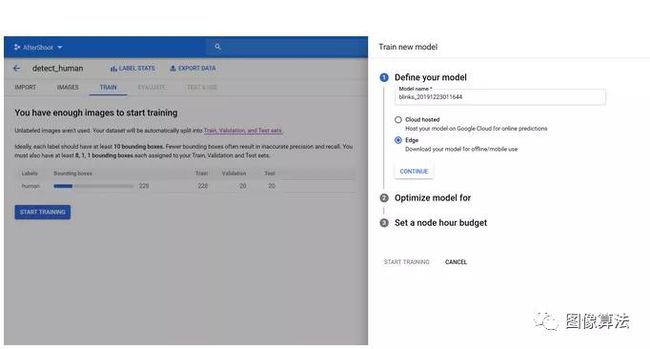
如果要使用tflite文件作为输出,请确保选择“ Edge”。
按继续,然后选择所需的模型精度。请注意,更高的精度意味着模型变慢,反之亦然:
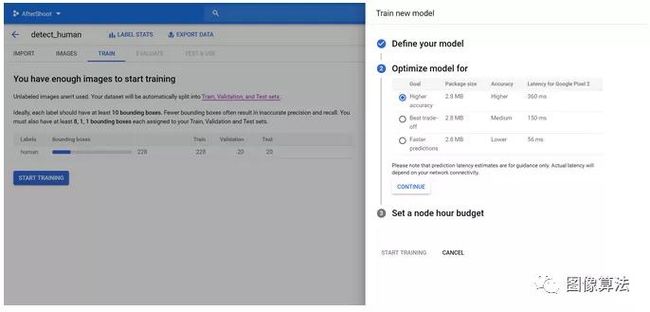
最后,选择您喜欢的预算并开始训练。
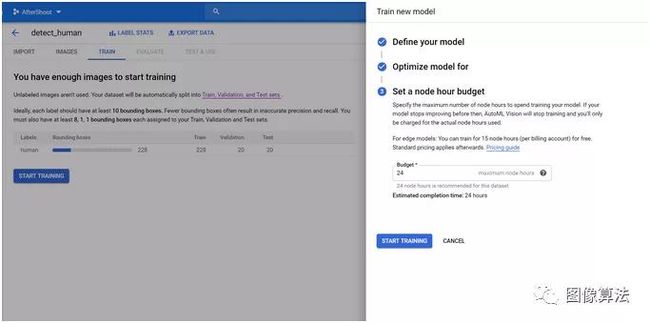
一旦模型训练开始,请坐下来放松一下!训练好模型后,您会收到一封电子邮件。
步骤6:部署和测试经过训练的模型
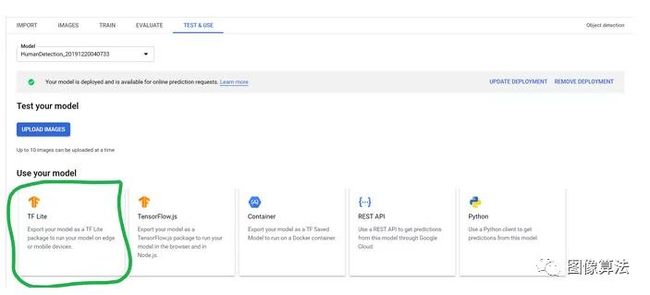
训练完模型后,您可以进入“测试和使用”选项卡并部署训练后的模型。
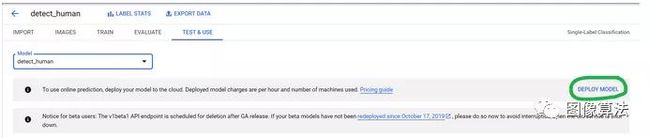
部署模型后,您可以将图像上传到Cloud Console并测试模型的准确性。
你还可以在本地系统上下载tflite文件,然后将其加载到您的应用中以在该处实现相同的功能:
如果要检测更多对象或需要更准确的模型,则可以向数据集中添加更多图像,为它们添加注释,并重新训练模型。
更多论文地址源码下载地址:关注“图像算法”微信公众号