一 相关背景
网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一段用来自动化采集网站数据的程序。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络爬虫不仅能够为搜索引擎采集网络信息,而且还可以作为定向信息采集器,定向采集某些网站下的特定信息,如:汽车票价,招聘信息,租房信息,微博评论等。
二 应用场景
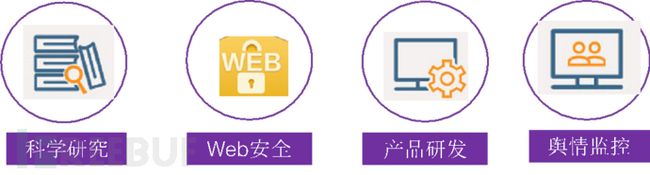
图1 应用场景
爬虫技术在科学研究、Web安全、产品研发、舆情监控等领域可以做很多事情。如:在数据挖掘、机器学习、图像处理等科学研究领域,如果没有数据,则可以通过爬虫从网上抓取;在Web安全方面,使用爬虫可以对网站是否存在某一漏洞进行批量验证、利用;在产品研发方面,可以采集各个商城物品价格,为用户提供市场最低价;在舆情监控方面,可以抓取、分析新浪微博的数据,从而识别出某用户是否为水军。
三 本文目的
本文简要介绍对于定向信息采集所需了解基本知识和相关技术,以及python中与此相关的库。同时提供对与数据抓取有关库的封装实现,目的是减少不必要的配置,便于使用,目前仅包含对urllib2, requests, mechanize的封装。地址:https://github.com/xinhaojing/Crawler
四 运行流程
对于定向信息的爬取,爬虫主要包括数据抓取、数据解析、数据入库等操作流程。其中:
(1)数据抓取:发送构造的HTTP请求,获得包含所需数据的HTTP响应;
(2)数据解析:对HTTP响应的原始数据进行分析、清洗以提取出需要的数据;
(3)数据入库:将数据进一步保存到数据库(或文本文件),构建知识库。
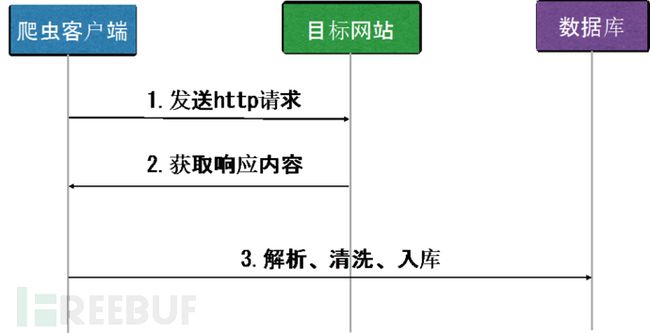
图2.1 基本运行流程
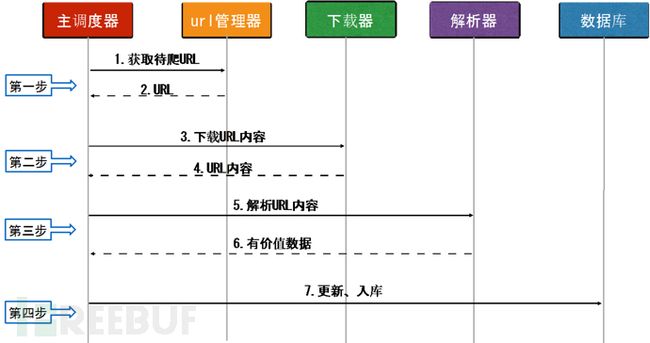
图2.2 详细运行流程
五 相关技术
爬虫的相关技术包括:
(1)数据抓取:了解HTTP请求和响应中各字段的含义;了解相关的网络分析工具,主要用于分析网络流量,如:burpsuit等。一般情况,使用浏览器的开发者模式即可;
(2)数据解析:了解HTML结构、JSON和XML数据格式,CSS选择器、Xpath路径表达式、正则表达式等,目的是从响应中提取出所需的数据;
(3)数据入库:MySQL,SQLite、Redis等数据库,便于数据的存储;
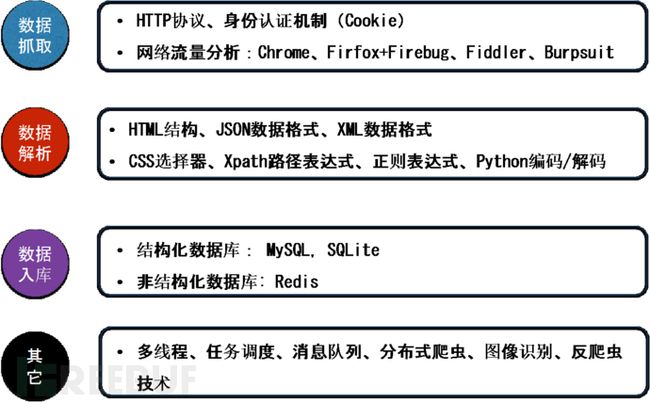
图3 相关技术
以上是学习爬虫的基本要求,在实际的应用中,也应考虑如何使用多线程提高效率、如何做任务调度、如何应对反爬虫,如何实现分布式爬虫等等。本文介绍的比较有限,仅供参考。
六 python相关库
在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter;在数据解析方包括:lxml、beautifulsoup4、re、pyquery。
对于数据抓取,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,常见类型有:get/post。其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通过加载浏览器驱动,获取浏览器渲染之后的响应内容,模拟程度更高。
具体选择哪种类库,应根据实际需求决定,如考虑效率、对方的反爬虫手段等。通常,能使用urllib2(urllib3)、requests、mechanize等解决的尽量不用selenium、splinter,因为后者因需要加载浏览器而导致效率较低。
对于数据解析,主要是从响应页面里提取所需的数据,常用方法有:xpath路径表达式、CSS选择器、正则表达式等。其中,xpath路径表达式、CSS选择器主要用于提取结构化的数据,而正则表达式主要用于提取非结构化的数据。相应的库有lxml、beautifulsoup4、re、pyquery。
表1 相关库文档
| 类库 | 文档 | |
|---|---|---|
| 数 据 抓 取 | urllib2 | https://docs.python.org/2/library/urllib2.html |
| requests | http://cn.python-requests.org/zh_CN/latest | |
| mechanize | https://mechanize.readthedocs.io/en/latest/ | |
| splinter | http://splinter.readthedocs.io/en/latest/ | |
| selenium | https://selenium-python.readthedocs.io/ | |
| 数 据 解 析 | lxml | http://lxml.de/ |
| beautifulsoup4 | https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html http://cuiqingcai.com/1319.html | |
| re | http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html | |
| pyquery | https://pythonhosted.org/pyquery/ |
七.相关介绍
1数据抓取
(1)urllib2
urllib2是python自带的一个访问网页及本地文件的库,通常需要与urllib一起使用。因为urllib提供了urlencode方法用来对发送的数据进行编码,而urllib2没有对应的方法。
以下是对urllib2简易封装的说明,主要是将相关的特性集中在了一个类函数里面,避免一些繁琐的配置工作。
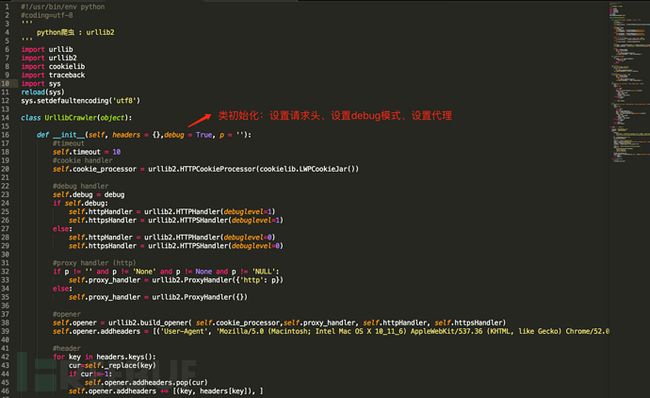
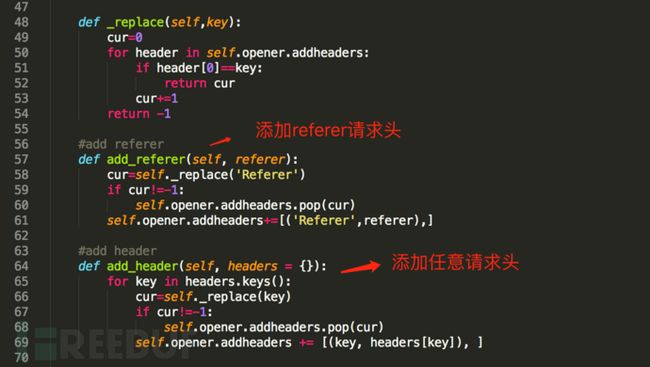
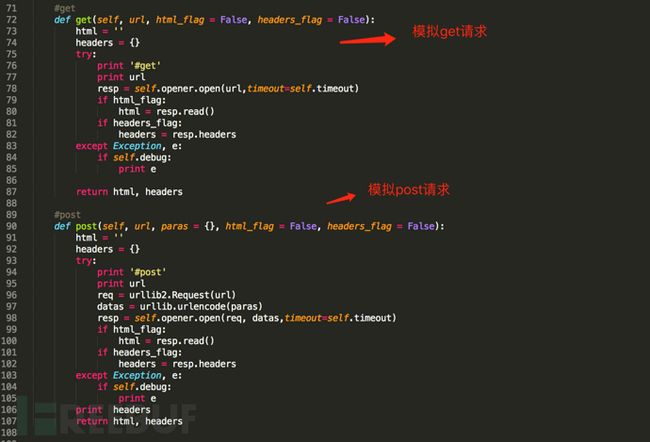
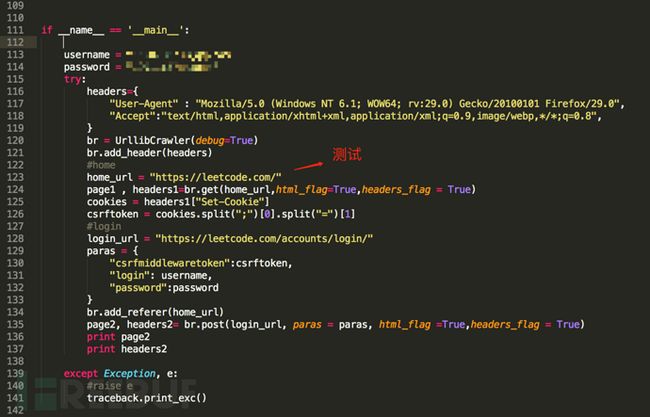
图4 urllib2封装说明
(2)requests和mechanize
requests是Python的第三方库,基于urllib,但比urllib更加方便,接口简单。其特点包括,关于http请求:支持自定义请求头,支持设置代理、支持重定向、支持保持会话[request.Session()]、支持超时设置、对post数据自动urlencode;关于http响应:可直接从响应中获得详细的数据,无需人工配置,包括:状态码、自动解码的响应内容、响应头中的各个字段;还内置JSON×××。
mechanize是对urllib2部分功能的替换,能够更好的模拟浏览器行为,在web访问控制方面做得很全面。其特点包括:支持cookie设置、代理设置、重定向设置、简单的表单填写、浏览器历史记录和重载、referer头的添加(可选)、自动遵守robots.txt、自动处理HTTP-EQUIV和刷新等。
对requests和mechanize简易封装后的接口与urllib2一样,也是将相关特性集中在了一个类函数里面,这里不在重复说明,可参考所给代码。
(4)splinter和selenium
selenium(python)和splinter可以很好的模拟浏览器行为,二者通过加载浏览器驱动工作。在采集信息方面,降低了分析网络请求的麻烦,一般只需要知道数据页面对应的URL即可。由于要加载浏览器,所以效率方面相对较低。
默认情况下,优先使用的是Firefox浏览器。这里列出chrome和pantomjs(无头浏览器)驱动的下载地址,方便查找。
chrome和pantomjs驱动地址:
chrome : http://chromedriver.storage.googleapis.com/index.html?path=2.9/
pantomjs : http://phantomjs.org/download.html
2 数据解析
对于数据解析,可用的库有lxml、beautifulsoup4、re、pyquery。其中,beautifulsoup4比较常用些。除了这些库的使用,可了解一下xpath路径表达式、CSS选择器、正则表达式的语法,便于从网页中提取数据。其中,chrome浏览器自带生成Xpath的功能。
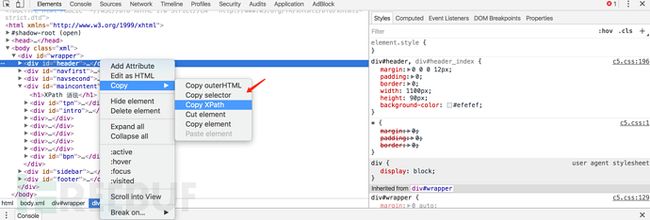
图5 chrome查看元素的xpath
如果能够基于网络分析,抓取到所需数据对应的页面,接下来,从页面中提取数据的工作就相对明确很多。具体的使用方法可参考文档,这里不在详细介绍。
八 反爬虫
1. 基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、referer等。针对这种情况,只要在请求中带上对应的字段即可。所构造http请求的各个字段最好跟在浏览器中发送的完全一样,但也不是必须。
2. 基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一设定的阈值,给予封锁。针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用代理的IP地址(或通过使用User-Agent列表解决,每次从列表里随机选择一个使用)。这样的反爬虫方法可能会误伤用户。
3. 希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别。
4. 基于JavaScript的反爬虫手段,主要是在响应数据页面之前,先返回一段带有JavaScript代码的页面,用于验证访问者有无JavaScript的执行环境,以确定使用的是不是浏览器。
通常情况下,这段JS代码执行后,会发送一个带参数key的请求,后台通过判断key的值来决定是响应真实的页面,还是响应伪造或错误的页面。因为key参数是动态生成的,每次都不一样,难以分析出其生成方法,使得无法构造对应的http请求。
比如网站http://www.kuaidaili.com/,使用就是这种方式,具体可参见https://www.v2ex.com/t/269337。
在首次访问网站时,响应的JS内容会发送带yundun参数的请求,而yundun参数每次都不一样。


图6动态参数yundun
目前测试时,该JavaScript代码执行后,发送的请求不再带有yundun参数,而是动态生成一个cookie,在随后的请求中带上该cookie,作用类似于yundun参数。
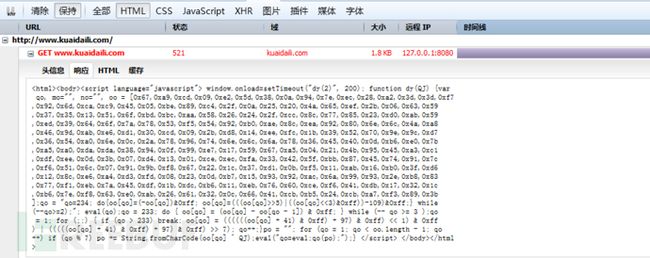
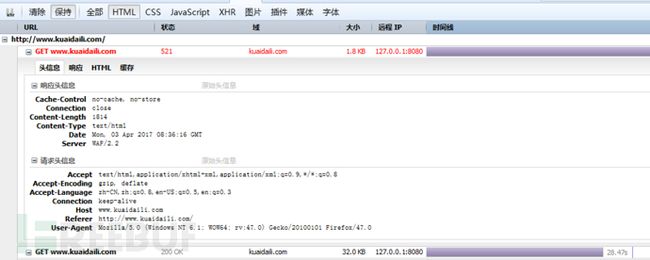
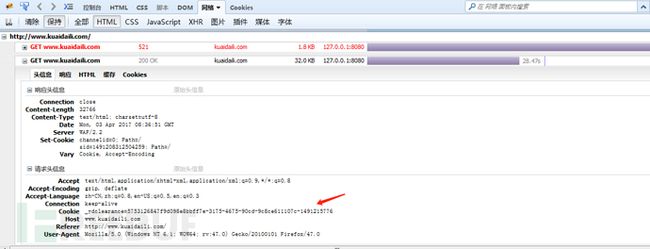
图7 动态cookie
针对这样的反爬虫方法,爬虫方面需要能够解析执行JavaScript,具体的方法可使用selenium或splinter,通过加载浏览器来实现。
更详细的反爬虫技术和应对方法可参考:
1.https://zhuanlan.zhihu.com/p/20520370
2.https://segmentfault.com/a/1190000005840672
3.http://v.qq.com/page/j/o/t/j0308hykvot.html
九 参考
[1] http://www.test404.com/post-802.html
[2] http://blog.csdn.net/shanzhizi/article/details/50903748
[3] http://blog.chinaunix.net/uid-28930384-id-3745403.html
[4] http://blog.csdn.net/cnmilan/article/details/9199181
[5] https://zhuanlan.zhihu.com/p/20520370
[6] https://segmentfault.com/a/1190000005840672
[7] https://www.v2ex.com/t/269337