转载请注明出处
如果学习深度学习在点云处理上的应用,那PointNet一定是你躲不开的一个模型。这个模型由斯坦福大学的Charles R. Qi等人在PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation一文中提出。下面我将结合手中的一些资料谈一谈我对这篇文章的理解。
简介
深度学习已经成为了计算机视觉领域的一大强有力的工具,尤其在图像领域,基于卷积神经网络的深度学习方法已经攻占了绝大多数问题的高点。然而针对无序点云数据的深度学习方法研究则进展相对缓慢。这主要是因为点云具有三个特征:无序性、稀疏性、信息量有限。
以往学者用深度学习方法在处理点云时,往往将其转换为特定视角下的深度图像或者体素(Voxel)等更为规整的格式以便于定义权重共享的卷积操作等。
PointNet则允许我们直接输入点云进行处理。
输入输出
输入为三通道点云数据,也可以有额外的通道比如颜色、法向量等,输出整体的类别/每个点所处的部分/每个点的类别。对于目标分类任务,输出为个分数,分别对应个可能的类别。对于语义分割任务,输出个分数,分别对应个点相对于各类别的分数。
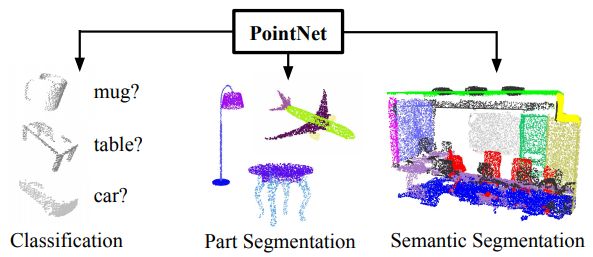
点云特征
PointNet网络结构的灵感来自于欧式空间里的点云的特点。对于一个欧式空间里的点云,有三个主要特征:
无序性:虽然输入的点云是有顺序的,但是显然这个顺序不应当影响结果。
点之间的交互:每个点不是独立的,而是与其周围的一些点共同蕴含了一些信息,因而模型应当能够抓住局部的结构和局部之间的交互。
变换不变性:比如点云整体的旋转和平移不应该影响它的分类或者分割
网络结构
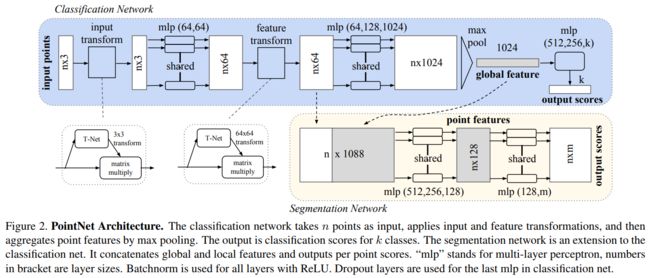
如图所示, 分类网络对于输入的点云进行输入变换(input transform)和特征变换(feature transform),随后通过最大池化将特征整合在一起。 分割网络则是分类网络的延伸,其将整体和局部特征连接在一起出入每个点的分数。图片中"mpl"代表"multi-layer perceptron"(多层感知机)。
其中,mlp是通过共享权重的卷积实现的,第一层卷积核大小是1x3(因为每个点的维度是xyz),之后的每一层卷积核大小都是1x1。即特征提取层只是把每个点连接起来而已。经过两个空间变换网络和两个mlp之后,对每一个点提取1024维特征,经过maxpool变成1x1024的全局特征。再经过一个mlp(代码中运用全连接)得到k个score。分类网络最后接的loss是softmax。
网络特点
针对无序输入的对称函数
为了让模型具有输入排列不变性(结果不受输入排列顺序的影响),一种思路是利用所有可能的排列顺序训练一个RNN。作者在这里采用的思路是使用一个对称函数,将个向量变为一个新的、与输入顺序无关的向量。(例如,和是能处理两个输入的对称函数)。
将点云排序是一个可能的对称函数,不过作者在这里采用一个微型网络(T-Net)学习一个获得变换矩阵的函数,并对初始点云应用这个变换矩阵,这一部分被称为输入变换。随后通过一个mlp多层感知机后,再应用一次变换矩阵(特征变换)和多层感知机,最后进行一次最大池化。
作者认为以上这个阶段学习到的变换函数是如下图所表示的函数和,保证了模型对特定空间转换的不变性(注意到深度学习实际上是对复杂函数的拟合)。
个人的理解是其中作为一个对称函数,是由最大池化实现的(注意到映射是n-对称的);而是mlp结构,代表了一个复杂函数(在图中是将一个3维向量映射成1024维向量的函数)。
(这里变换矩阵的学习过程个人认为有一些玄学,我自己并不能很好地理解其如何获得旋转不变性。不过深度学习领域有很多无法解释的东西。感兴趣可以参考一下文末的源码)
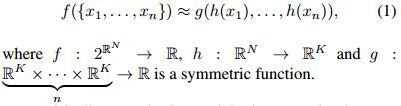
整合局部和全局信息
对于点云分割任务,我们需要将局部很全局信息结合起来。
这里,作者将经过特征变换后的信息称作局部信息,它们是与每一个点紧密相关的;我们将局部信息和全局信息简单地连接起来,就得到用于分割的全部信息。
理论分析
除了模型的介绍,作者还引入了两个相关的定理:

定理1证明了PointNet的网络结构能够拟合任意的连续集合函数。
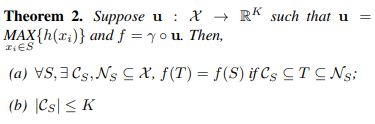
定理2(a)说明对于任何输入数据集,都存在一个关键集和一个最大集,使得对和之间的任何集合,其网络输出都和一样。这也就是说,模型对输入数据在有噪声和有数据损坏的情况都是鲁棒的。定理2(b)说明了关键集的数据多少由maxpooling操作输出数据的维度K给出上界(框架图中为1024)。个角度来讲,PointNet能够总结出表示某类物体形状的关键点,基于这些关键点PointNet能够判别物体的类别。这样的能力决定了PointNet对噪声和数据缺失的鲁棒性。[引自美团知乎专栏]
下图给出了一些关键集和最大集的样例:

后记
我们知道,激光雷达所采集到的数据是3D点云。点云的处理应用也越来越广泛,比较常见的应用场景是自动驾驶和工业机器人。
尽管激光雷达(Lidar)的成本依然很高,但考虑到它具有更高的距离测量精度,越来越多的无人驾驶公司开始研究基于激光雷达的无人驾驶方案。据笔者了解,Momenta、Nullmax于近期(2018年)开始组建激光雷达团队,而Pony、阿里巴巴AI lab、美团、Waymo等则一直研发集成激光雷达的无人驾驶方案。尽管Tesla的马斯克曾经对Lidar大为嘲讽,笔者在与VisLab负责人Alberto Broggi的交流时对方也表示Lidar与图像互补性不是很高(比如他们都会在强光或者雨雾中失效)。我的感觉是,纯粹基于图像的自动驾驶感知方案还不能达到技术落地的要求,或者无法提供足够的安全冗余。因而了解一下点云的处理技术对于自动驾驶从业者还是很有帮助的,毕竟随着更多资本的涌入,激光雷达的成本也会有所降低。
此外我也了解到有一些利用激光雷达进行目标识别和定位的机械臂,应该也是一个比较火的方向。
参考:
Momenta高级研究员陈亮论文解读
美团无人配送的知乎专栏:PointNet系列论文解读
hitrjj的CSDN博客:三维点云网络——PointNet论文解读
github源码
痛并快乐着呦西的CSDN博客:三维深度学习之pointnet系列详解
作者的其他相关文章:
图像分割:全卷积神经网络(FCN)详解
基于视觉的机器人室内定位
目标检测:YOLO和SSD 简介
论文阅读:InLoc:基于稠密匹配和视野合成的室内定位
论文阅读:StreetMap-基于向下摄像头的视觉建图与定位方案
模型源码(部分)
输入变换
def input_transform_net(point_cloud, is_training, bn_decay=None, K=3):
""" Input (XYZ) Transform Net, input is BxNx3 gray image
Return:
Transformation matrix of size 3xK """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
input_image = tf.expand_dims(point_cloud, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay)
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='tmaxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay)
with tf.variable_scope('transform_XYZ') as sc:
assert(K==3)
weights = tf.get_variable('weights', [256, 3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases = tf.get_variable('biases', [3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases += tf.constant([1,0,0,0,1,0,0,0,1], dtype=tf.float32)
transform = tf.matmul(net, weights)
transform = tf.nn.bias_add(transform, biases)
transform = tf.reshape(transform, [batch_size, 3, K])
return transform
主体部分
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, '../utils'))
import tf_util
from transform_nets import input_transform_net, feature_transform_net
def placeholder_inputs(batch_size, num_point):
pointclouds_pl = tf.placeholder(tf.float32, shape=(batch_size, num_point, 3))
labels_pl = tf.placeholder(tf.int32, shape=(batch_size))
return pointclouds_pl, labels_pl
def get_model(point_cloud, is_training, bn_decay=None):
""" Classification PointNet, input is BxNx3, output Bx40 """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
end_points = {}
with tf.variable_scope('transform_net1') as sc:
transform = input_transform_net(point_cloud, is_training, bn_decay, K=3)
point_cloud_transformed = tf.matmul(point_cloud, transform)
input_image = tf.expand_dims(point_cloud_transformed, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv2', bn_decay=bn_decay)
with tf.variable_scope('transform_net2') as sc:
transform = feature_transform_net(net, is_training, bn_decay, K=64)
end_points['transform'] = transform
net_transformed = tf.matmul(tf.squeeze(net, axis=[2]), transform)
net_transformed = tf.expand_dims(net_transformed, [2])
net = tf_util.conv2d(net_transformed, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv3', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv4', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv5', bn_decay=bn_decay)
# Symmetric function: max pooling
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='maxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='fc1', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,
scope='dp1')
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='fc2', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,
scope='dp2')
net = tf_util.fully_connected(net, 40, activation_fn=None, scope='fc3')
return net, end_points
def get_loss(pred, label, end_points, reg_weight=0.001):
""" pred: B*NUM_CLASSES,
label: B, """
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=pred, labels=label)
classify_loss = tf.reduce_mean(loss)
tf.summary.scalar('classify loss', classify_loss)
# Enforce the transformation as orthogonal matrix
transform = end_points['transform'] # BxKxK
K = transform.get_shape()[1].value
mat_diff = tf.matmul(transform, tf.transpose(transform, perm=[0,2,1]))
mat_diff -= tf.constant(np.eye(K), dtype=tf.float32)
mat_diff_loss = tf.nn.l2_loss(mat_diff)
tf.summary.scalar('mat loss', mat_diff_loss)
return classify_loss + mat_diff_loss * reg_weight
if __name__=='__main__':
with tf.Graph().as_default():
inputs = tf.zeros((32,1024,3))
outputs = get_model(inputs, tf.constant(True))
print(outputs)