本文仿照fastAI的课程代码,建立宠物分类器。
1. 准备数据集
1.1 准备数据集目录
fastAI的URLs里面预定义了很多数据集的下载链接,但大部分都需要科学上网,而且下载速度很慢,所以此处我先用将其下载到本地,然后直接加载,比如:
# path = untar_data(URLs.PETS)
path =Path('/home/ray/DataSet/oxford-iiit-pet')
此处的path表示一个目录,可以查看该目录下还有哪些子目录:
path.ls()
[PosixPath('/home/ray/DataSet/oxford-iiit-pet/annotations'),
PosixPath('/home/ray/DataSet/oxford-iiit-pet/images')]
可以看出,path目录下有两个子目录,annotations和images,分别表示数据集的标签和图片,所以我们可以分别构建标签目录和图片目录:
path_anno = path/'annotations'
path_img = path/'images'
1.2 查看数据集图片和标签
在训练之前,需要充分了解图片和对应的标签,并且构建可以训练的fastAI独自的Learner。
查看文件的方法:
fnames = get_image_files(path_img)
fnames[:5]
[PosixPath('/home/ray/DataSet/oxford-iiit-pet/images/newfoundland_132.jpg'),
PosixPath('/home/ray/DataSet/oxford-iiit-pet/images/boxer_112.jpg'),
PosixPath('/home/ray/DataSet/oxford-iiit-pet/images/Abyssinian_213.jpg'),
PosixPath('/home/ray/DataSet/oxford-iiit-pet/images/Ragdoll_31.jpg'),
PosixPath('/home/ray/DataSet/oxford-iiit-pet/images/american_pit_bull_terrier_63.jpg')]
由此可以看出,每张图片的label都包含在文件名中,所以我们需要从文件名中提取出各自的label,提取方法可以是正则表达式,也可以是其他字符串处理方法。
fastAI中已经定义了一个函数:from_name_re表示用正则表达式从文件名中提取特定字符串,可以用于本案例。
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$' # 此处获取的时文件名,eg: /Ragdoll_31.jpg /american_pit_bull_terrier_63.jpg
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=64).normalize(imagenet_stats)
上面的pat就是正则表达式,提取的是比如:/Ragdoll_31.jpg /american_pit_bull_terrier_63.jpg等,注意里面含有斜杠。
可以通过data的show_batch来显示出批量图片,比如:
data.show_batch(rows=3, figsize=(7,6)),会显示3行3列的图片,为:

随机查看了图片之后,还需要查看label,可以用
print(data.classes)
len(data.classes)
来打印出所有类别,以及类别的个数。此处一共有37个类别。
2. 模型训练
此处使用简单的resnet34作为基本的模型,并且使用imagenet上预训练好的权重参数做进一步的微调,得到更适合本项目的分类器模型。代码为:
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
如果是第一次使用resnet34,会自动下载权重文件,一般文件比较大,下载很耗时,可以先下载resnet34模型,放置到/root/.cache/torch/checkpoints/resnet34-333f7ec4.pth中,这样就不用下载,直接使用即可。
如果想查看模型的结构,可以用learn.model
cnn_learner是fastAI中非常重要的一个类,继承自Learner,将ImageDataBunch,CNN模型resnet34等其他参数封装到一起。
Learner的训练可以使用:
learn.fit_one_cycle(4)
此处仅仅训练4个epochs,得到的结果是:
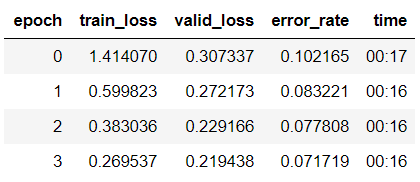
模型的保存:learn.save(’stage-1’)
3. 查看模型效果
多分类一般使用categorical_crossentropy作为loss func, 所以此处的loss非常重要,表示,我们经常需要打印出预测错误的类别的loss值,以帮助我们做误差分析。
下面打印出最高的loss,然后将loss最高的9张图片显示出来:
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
interp.plot_top_losses(9, figsize=(15,11))

同理,还可以查看混淆矩阵,通过对比可以看出到底是哪些类别之间最容易混淆。
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)

上面的混淆矩阵比较适合类别比较少的情况,如果有几百上千的类别,那么根本看不过来,所以还是下面的most_confused函数比较实用一些。
interp.most_confused(min_val=2)
[('staffordshire_bull_terrier', 'american_pit_bull_terrier', 8),
('Ragdoll', 'Birman', 7),
('american_pit_bull_terrier', 'staffordshire_bull_terrier', 5),
('beagle', 'basset_hound', 5),
('Egyptian_Mau', 'Bengal', 4),
('american_pit_bull_terrier', 'american_bulldog', 4),
('chihuahua', 'miniature_pinscher', 4),
('Persian', 'Ragdoll', 3),
('english_setter', 'english_cocker_spaniel', 3),
('British_Shorthair', 'Russian_Blue', 2),
('Maine_Coon', 'Bengal', 2),
('Maine_Coon', 'Persian', 2),
('Maine_Coon', 'Ragdoll', 2),
('Ragdoll', 'Persian', 2),
('Russian_Blue', 'Bombay', 2),
('Russian_Blue', 'British_Shorthair', 2),
('american_bulldog', 'american_pit_bull_terrier', 2),
('saint_bernard', 'american_bulldog', 2)]
4. 解冻再微调
上面的方法仅仅是使用resnet34的顶层全连接层来进行训练,而底层的CNN层使用的还是原来的ImageNet的权重,有时候,我们的数据集和ImageNet差别比较大,所以通过解冻底层CNN结构,然后再微调的方式,可能会得到更高的准确率,特别是对于那种数据集和ImageNet差别比较大的项目,这种解冻再微调的方法更容易提高准确率。
learn.unfreeze() # 解冻所有底层,使得训练时可以训练这些底层结构。
learn.fit_one_cycle(1) # one-cycle policy,用于寻找最佳的lr。
learn.lr_find() # 使用自身的lr_find()方法来寻找最合适的lr.
learn.recorder.plot() # 绘制loss-lr图,便于寻找最合适的lr
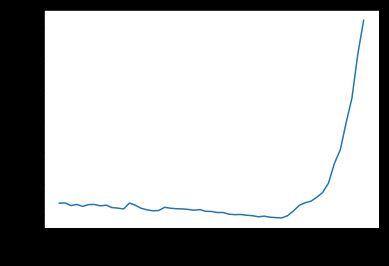
上面的learn是已经训练过4个epochs,所以得到的loss原本就比较低,所以下降的平缓一些,不过我们可以找到其下降最快的区间位于1e-6到1e-4之间,所以解冻再训练可以设置为:
learn.unfreeze()
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))

5. 使用resnet50
一般的,使用更深的网络有可能得到更高的精度,因为更深的网络参数更多,更能学习到这些类别之间的差异,但是,更深的网络会有更大的过拟合风险。
上面的resnet34得到了0.07-0.08左右的error_rate,所以这次换成resnet50,看看能不能降低这个error_rate.
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(),
size=299, bs=bs//2).normalize(imagenet_stats)
# 此处增大图片尺寸,更大的图片尺寸可能展示更多的细节,可能提高准确率,但需要更多GPU内存,会更耗时。
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
learn.lr_find()
learn.recorder.plot()

这次使用预训练模型训练8个epochs,为:
learn.fit_one_cycle(8)

也可以解冻再训练3个epochs:
learn.unfreeze()
learn.fit_one_cycle(3, max_lr=slice(1e-6,1e-4))
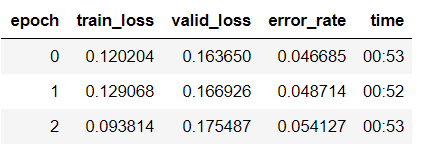
由此可以看出,error_rate降低到了0.05左右,所以效果有提升。