基于爬虫的app快速开发与思考
2016-05-26
从“按空格”公众号 迁移至此
本文适用于有一定android开发经验的开发人员.
有幸跟大伙儿分享下本人基于爬虫技术开发app的前后经历。本文不会过多的讲解项目代码,重点是分享下本人使用jsoup达到的实际效果,做了哪些事情,衍生出了哪些问题及其解决办法,本文涉及到的所有代码和相关资源及使用说明均已传到github上面(具体链接地址在文章最下方),大家可以下载下来去看。
问题一:开发一款app内容从哪来
内容问题,首先想到的就是爬虫,因为爬取目标特别明确,所以无需采用爬虫框架,只需要简单的网页解析器即可,本人采用的是jsoup解析器,以悦读圈为例讲一下具体的使用
Jsoup解析器
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。具体使用可以参考这个链接地址http://www.open-open.com/jsoup/
Jsoup使用案例----悦读圈(下载地址https://www.pgyer.com/enjoyread)
基于Jsoup开发了一款悦读圈app,内容来源于网站:特别关注-成熟人士的读者文摘(http://www.de99.cn/index.html)
原网站:
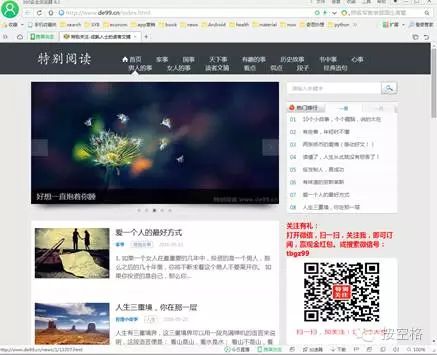
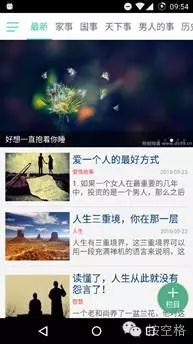
悦读圈App效果图:
用到的第三方资源
又拍云存储:内容分享时,修改过的html上传到又拍云存储上面,然后把这个链接地址分享到朋友圈或者其他地方就达到分享的目的了。
百度应用引擎:版本更新用,写了一个简单的HttpServlet返回版本更新数据接口,和一个APP上传页面,部署到百度应用引擎上
文章列表页解析
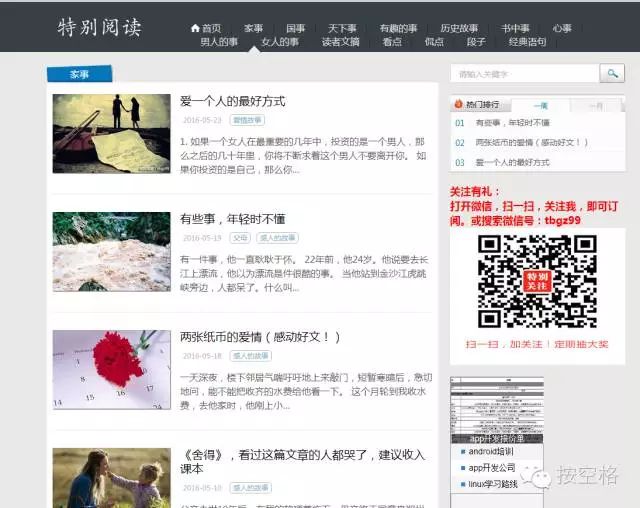
一般来讲文章列表包含的元素有:标题、一副图片、文章摘要、标签分类、发表时间、详情链接地址等,采用jsoup获取到该html并解析到你项目中的javabean对象,悦读圈解析时使用selector选择器较少,代码看上去不太整洁,也容易出错。建议各位开发的时候多用selector选择器。解析列表页时会获取到每篇文章的具体链接地址URL,以这个URL的MD5值作为文章的id使用,app中涉及到阅读历史、文章收藏,都可以通过该ID来唯一确定此文章。
内容详情页解析
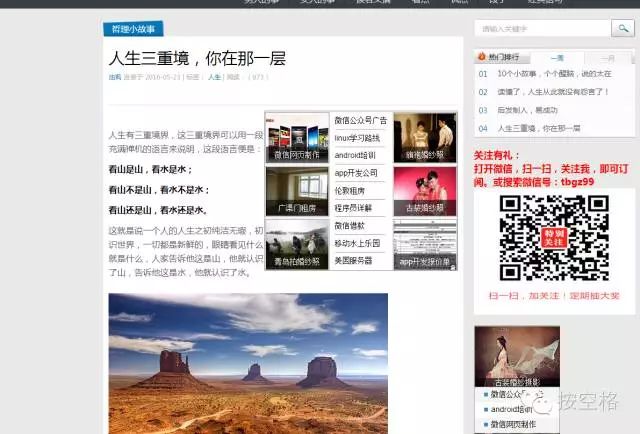
内容详情页的解析大同小异,采用jsoup获得返回的html页面,然后去除html中无用的导航,侧边栏,广告等div元素,只保留内容核心区域的div,然后图片需要根据手机屏幕做处理,改写img标签元素,如果宽度大于手机屏幕则进行等比缩放,把改写后的html字符串用android的webview进行加载,效果就看上去很不错了如果是有多页的文章还需要处理是否有下一页的逻辑
图片的处理
图片的处理比较关键,一般遇到的问题有:
1、图片比较大,服务器流量hold不住;
2、图片比较小,手机端显示过于模糊,影响用户体验;
3 、手机端控件加载图片时需要预先知道图片分辨率。
有的网站图片比较大,用原网址或者直接存储到第三方,而且必要的时候链接地址还得改成绝对地址。对于图片较小的图片,可以找到对应资源的大图片,然后裁切后上传到第三方存储,并将其地址存储到后台服务器,分辨率处理也可以采用此方法。
问题二:如何才能进行快速开发
要想快速开发或者批量制作或者维护方便,必须进行标准化,万事皆是如此。
以爬虫抓取到的网页内容完全可以由自己进行二次整理,然后做成符合自己要求的app,我大致将内容归结为两种,一种是纯图片型的,一种是文章带图片型的,于是我的app核心模块也是这两种内容的处理。基于此需求,如何进行app的快速开发整体思路如下:
Android工程框架构建
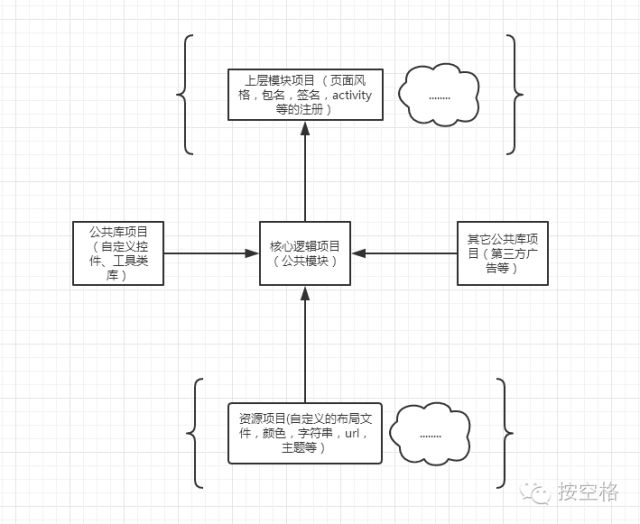
具体到AS中的项目结构
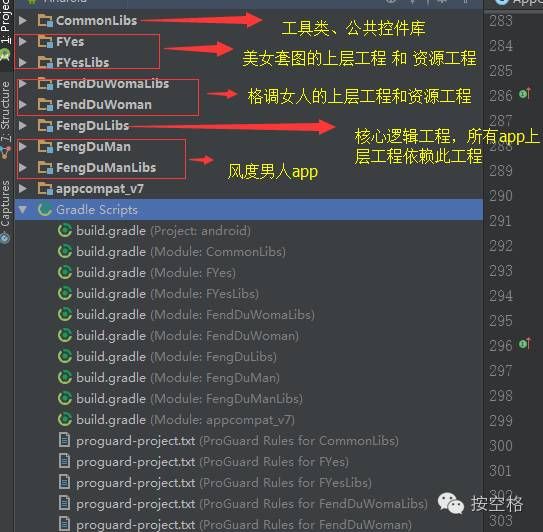
这是三个项目:分别是格调女人、风度男人、美女套图,核心代码只需要维护FengDuLibs工程即可,切换项目是需要修改FengDuLibs的build.gradle依赖工程(对应app的资源工程),首页面风格(模块组合、侧滑菜单选项、tab切换等)在上层工程中修改即可,当然需要核心工程FengDuLibs支持,修改UI、缓存路径、请求接口、主题等只需要在相应的资源类工程中修改即可。
仍需改进的地方
1:资源抓取
问题:就是每解析一个网站或者一个新的模块,都需要增加一个类或者说具体的实现,去解析相应的网页。
解决办法:
1:采用解释器模式用自定义的解释器逻辑去解析。
2:类似于解释器模式,但相对简单,因为采用了selector选择器,所以语法规则可以搞的相对简单一些,避免自己写的解释器出现深层递归嵌套等现象,严重影响效率
2:mvp模式显然更适合这种项目分层
参考资源
MyCollector资源抓取工程:https://github.com/stdroom/MyCollector.git
Web后台工程: https://github.com/stdroom/FengduServer.git
Android工程: https://github.com/stdroom/FengDuAppFactory.git
悦读圈工程(后台、前端其它)https://github.com/stdroom/bae_web.git
后台学习资源(淘淘商城、新巴巴运动网 视频教程及源码):http://pan.baidu.com/s/1jH9p0Dg密码: 68sv
推荐一款Github插件:Octotree。用这个看github代码会方便一些