数据集成
数据挖掘需要的数据往往分布在不同的数据源中,数据集成就是将多个数据源合并存放在一个一致的数据存储(如数据仓库)中的过程。
在数据集成时,来自多个数据源的现实世界实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将元数据在最低层上加以转换、提炼和集成。
实体识别
实体识别是指从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处,常见形式如下。
- 同名异议
数据源A中的属性ID和数据源B中的属性ID分别描述的菜品编号和订单编号,即描述的是不同的实体。 - 异名同义
数据源A中的sales_dt和数据源B中的sales_date都是描述销售日期的,即A.sales_dt=B.sales_date。 - 单位不统一
描述同一个实体分别用的是国际单位和中国传统的计量单位。
检测和解决这些冲突就是实体识别的任务。
冗余属性识别
数据集成往往导致数据冗余,例如,
1)统一属性多次出现;
2)同一属性命名不一致导致重复。
仔细整合不同源数据能减少甚至避免数据冗余与不一致,从而提高数据挖掘的速度和质量。对于冗余属性要先分析,检测到后再将其删除。
有些冗余属性可以用相关分析检测。给定两个数值型的属性A和B,根据其属性值,用相关系数度量一个属性在多大程度上蕴含另一个属性。
数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的”形式,以适用于挖掘任务及算法的需要。
简单函数变换
简单函数变换是对原始数据进行某些数学函数变换,常用的变换包括平方、开方、取对数、差分运算等,即:

简单的函数变换常用来将不具有正态分布的数据变换成具有正态分布的数据。在时间序列分析中,有时简单的对数变换或者差分运算就可以将非平稳序列转换成平稳序列。在数据挖掘中,简单的函数变换可能更有必要,比如个人年收入的取值范围为10000元到10亿元,这是一个很大的区间,使用对数变换对其进行压缩是常用的一种变换处理方法。
规范化
数据规范化(归一化)处理是数据挖掘的一项基础工作。不同评价指标往往具有不同的量纲,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果。为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析。如将工资收入属性值映射到[-1,1]或者[0,1]内。
数据规范化对于基于距离的挖掘算法尤为重要。
(1)最小-最大规范化
最小-最大规范化也称为离差标准化,是对原始数据的线性变换,将数值值映射到[0,1]之间。
转换公式如下:
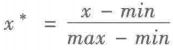
其中,max为样本数据的最大值,min为样本数据的最小值。max-min为极差。离差标准化保留了原来数据中存在的关系,是消除量纲和数据取值范围影响的最简单方法。这种处理方法的缺点是若数值集中且某个数值很大,则规范化后各值会接近于0,并且将会相差不大。若将来遇到超过目前属性[min,max]取值范围的时候,会引起系统出错,需要重新确定min和max。
(2)零-均值规范化
零-均值规范化也称标准差标准化,经过处理的数据的均值为0,标准差为1.转化公式为:
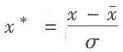
其中
(3)小数定标规范化
通过移动属性值得小数位数,将属性值映射到[-1,1]之间,移动的小数位数取决于属性值绝对值的最大值。
转化公式:
下面通过对一个矩阵使用上面3种规范化的方法处理,对比结果。其程序代码清单如下:
# _*_ coding:utf-8 _*_
# 数据规范化
import pandas as pd
import numpy as np
datafile = 'data/normalization_data.xls' # 参数初始化
data = pd.read_excel(datafile, header = None) # 读取数据
(data - data.min()) / (data.max() - data.min()) # 最小-最大规范化
(data - data.mean()) / data.std() # 零-均值规范化
data / 10 ** np.ceil(np.log10(data.abs().max())) # 小数定标规范化
执行上面的代码后,可以在命令行看到下面的输出:

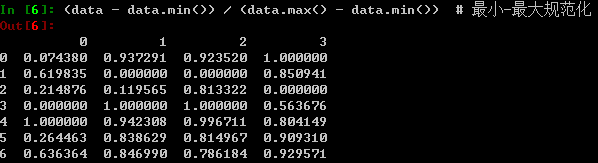

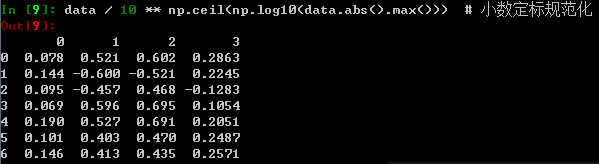
对于一个含有n个记录p个属性的数据集,分别对每一个属性的取值进行规范化。对原始的数据矩阵分别用最小-最大规范化、零-均值规范化、小数定标规范化进行规范化后的数据如上所示。
连续属性离散化
一些数据挖掘算法,特别是某些分类算法(如ID3算法、Apriori算法等),要求数据是分类属性形式。这样,常常需要将连续属性变换成分类属性,即连续属性离散化。
1.离散化的过程
连续属性的离散化就是在数据的取值范围内设定若干个离散的划分点,将取值范围分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。所以,离散化涉及两个子任务:确定分类数以及如何将连续属性值映射到这些分类值。
2.常用的离散化方法
常用的离散化方法有等宽法、等频法和(一维)聚类。
(1)等宽法
将属性的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定,或者由用户指定,类似于制作频率分布表。
(2)等频法
将相同数量的记录放进每个区间。
这两种方法简单,易于操作,但都需要人为地规定划分区间的个数。同时,等宽法的缺点在于它对离群点比较敏感,倾向于不均匀地把属性值分不到各个区间。有些区间包含许多数据,而另外一些区间的数据极少,这样会严重损坏建立的决策模型。等频法虽然避免了上述问题的产生,却可能将相同的数据值分到不同的区间以满足每个区间中固定的数据个数。
(3)基于聚类分析的方法
一维聚类的方法包括两个步骤,首先将连续属性的值用聚类算法(如K-Means算法)进行聚类,然后再将聚类得到的簇进行处理,合并到一个簇的连续属性值并做同一标记。聚类分析的离散化方法也需要用户指定簇的个数,从而决定产生的区间数。
# _*_ coding:utf-8 _*_
# 数据规范化
import pandas as pd
datafile = 'data/discretization_data.xls' # 参数初始化
data = pd.read_excel(datafile) # 读取数据
data = data[u'肝气郁结证型系数'].copy()
k = 4
d1 = pd.cut(data, k, labels = range(k)) # 等宽离散化,各个类比一次命名为0,1,2,3
# 等频率离散化
w = [1.0 * i / k for i in range(k + 1)]
w = data.describe(percentiles = w)[4:4+k+1] # 使用describe函数自动计算分位数
w[0] = w[0] * (1 -1e-10)
d2 = pd.cut(data, w, labels = range(k))
from sklearn.cluster import KMeans # 引入KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4) # 建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.reshape((len(data), 1))) # 训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort(0) # 输出聚类中心,并且排序(默认是随机序的)
w = pd.rolling_mean(c, 2).iloc[1:] # 相邻两项求中点,作为边界点
w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()


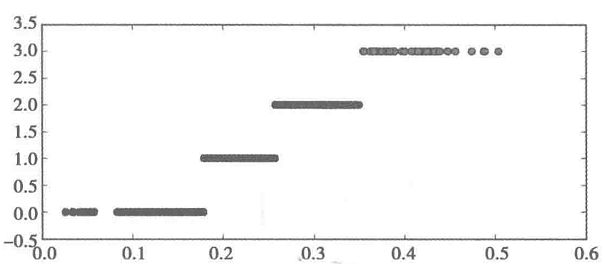
分别用等宽法、等频法和(一维)聚类对数据进行离散化,将数据分成4类,然后将每一类记为同一个标识,如分别记为A1、A2、A3、A4,再进行建模。
属性构造
在数据挖掘的过程中,为了提取更有用的信息,挖掘更深层次的模式,提高挖掘结果的精度,我们需要利用已有的属性集构造出新的属性,并加入到现有的属性集合中。
比如,进行防窃漏电诊断建模时,已有的属性包括供入电量、供出电量(线路上各大用户电量之和)。理论上供入电量和供出电量应该是相等的,但是由于在传输过程中存在电能损耗,使得供入电量略大于供出电量,如果该条线路上的一个或多个大用户存在窃漏电行为,会使得供入电量略明显大于供出电量。反过来,为了判断是否有大用户存在窃漏电行为,可以构造出一个新的指标——线损率,该过程就是构造属性。新构造的属性线损率按如下公式计算。

线损率的正常范围一般在3%~15%,如果远远超过该范围,就可以认为该条线路的大用户可能存在窃漏电等用户异常行为。
根据线损率的计算公式,由供入电量、供出电量进行线损率的属性构造代码,代码如下:
# _*_ coding:utf-8 _*_
# 线损率属性构造
import pandas as pd
# 参数初始化
inputfile = 'data/electricity_data.xls' # 供入供出电量数据
outputfile = 'data/electricity_data.xls' # 属性构造后数据文件
data = pd.read_excel(inputfile) # 读入数据
data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量']) / data[u'供入电量']
data.to_excel(outputfile, index = False) # 保存结果
小波变换
小波变换是一种新型的数据分析工具,是近年来兴起的信号分析手段。小波分析的理论和方法在信号处理、图像处理、语音处理、模式识别、量子物理等领域得到越来越广泛的应用,它被认为是近年来在工具及方法上的重大突破。小波变换具有多分辨率的特点,在时域和频域都具有表征信号局部特征的能力,通过伸缩和平移等运算过程对信号进行多尺度聚焦分析,提供了一种非平稳信号的时域分析手段,可以由粗及细地逐步观察信号,从中提取有用信息。
能够刻画某个问题的特征量往往是隐含在一个信号中的某个或者某些分量重,小波变换可以把非平稳信号分解为表达不同层次、不同频带信息的数据序列,即小波系数。选取适当的小波系数,即完成了信号的特征提取。下面是基于小波变换的信号特征提取方法。
(1)基于小波变换的特征提取方法
| 基于小波变换的特征提取方法 | 方法描述 |
|---|---|
| 基于小波变换的多尺度空间能量分布特征提取方法 | 各尺度空间内的平滑信号和细节信号能提供原始信号的时频局域信息,特别是能提供不同频段上信号的构成信息。把不同分解尺度上信号的能力求解出来,就可以将这些能量尺度顺序排列,形成特征向量供识别用 |
| 基于小波变换的多尺度空间的模极大值特征提取方法 | 利用小波变换的信号局域化分析能力,求解小波变换的模极大值特征来检测信号的局部奇异性,将小波变换模极大值的尺度参数s、平移参数t及其幅值作为目标的特征量 |
| 基于小波包变换的特征提取方法 | 利用小波分解,可将时域随机信号列映射为尺度域各子空间内的随机系数序列,按小波包分解得到的最佳子空间内随机系数序列的不确定性程度最低,将最佳子空间的熵值即最佳子空间在完整二叉树中的位置参数作为特征量,可以用于目标识别 |
| 基于适应性小波神经网络的特征提取方法 | 基于适应性小波神经网络的特征提取方法可以把信号通过分析小波拟合表示,进行特征提取 |
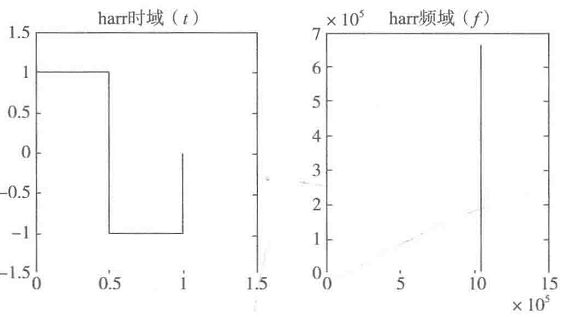
(2)小波基函数
小波基函数是一种具有局部支集的函数,并且平均值为0,小波基函数满足。常用的小波基友Haar小波基、db系列小波基等。Haar小波基函数如下图所示:
(3)小波变换
对小波基函数进行伸缩和平移变换:
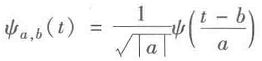
其中,a为伸缩因子,b为平移因子。
任意函数
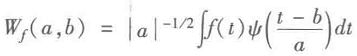
可知,连续小波变换为
其逆变换为:

(4)基于小波变换的多尺度空间能量分布特征提取方法
应用小波分析技术可以把信号在各频率波段中的特征提取出来,基于小波变换的多尺度空间能量分布特征提取方法是对信号进行频带分析,在分别以计算所得的各个频带的能量作为特征向量。
信号f(t)的二进小波分解可表示为:
其中A是近似信号,为低频部分;D是细节信号,为高频部分,此时信号的频带分布如下图所示:

信号总能量为:
选择第j层的近似信号和各层的细节信号的能量作为特征,构造特征向量:
利用小波变换可以对声波信号进行特征提取,提取出可以代表声波信号的向量数据,即完成从声波信号到特征向量数据的变换。本例利用小波函数对声波信号数据进行分解,得到5个层次的小波系数。利用这些小波系数求得各个能量值,这些能量值即可作为声波信号的特征数据。
# _*_ coding:utf-8 _*_
# 利用小波分析进行特征分析
# 参数初始化
inputfile = 'data/leleccum.mat' # 提取自Matlab的信号文件
from scipy.io import loadmat # mat是Python专用格式,需要用loadmat读取它
mat = loadmat(inputfile)
signal = mat['leleccum'][0]
import pywt # 导入PyWavelets
coeffs = pywt.wavedec(signal, 'bior3.7', level = 5)
# 返回结果为level+1个数字,第一个数组为逼近系数组数,后面的依次是细节系数数组