原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的。
相关背景
为什么要对网络进行压缩和加速呢?最实际的原因在于当前存储条件和硬件的计算速度无法满足复杂网络的需求,当然也许十几年或更远的将来,这些都将不是问题,那么神经网络的压缩和加速是否仍有研究的必要呢?答案是肯定的,我认为对网络压缩和加速的最根本原因在于对高效率模型的追求,当前很多复杂网络中的很多参数是冗余的,对实际模型结果没什么贡献,我们怎么能容忍这些无意义的参数竟然和有意义的参数享受相同的“待遇”——相同的存储空间和计算时间。尤其当存储空间和计算时间受限的情况下,我们更加无法容忍那些无意义的参数。当我们可以构造训练出一种模型,其所有的参数都是不可替代的,那么压缩和加速的工作就终于可以走向历史舞台了,但这种情况是不可能发生的,至少在近几十年不可能发生,因为当前神经网络对于研究者来说仍是一个黑箱。
神经网络刚刚被提出来时,对于如何将其应用与图像仍是个很大的问题,最单纯的想法是将图片按像素点排列成向量,再走多层感知机的老路,但由于参数太多,存储不便,计算速度太慢,始终无法得到进一步发展。终于一个神奇而又简单的想法逆转了这个困境——伟大的权值共享,于是卷积神经网络将整个模型的参数减少了若干倍。虽然由于当时硬件条件限制,对卷积神经网络的研究也一度陷入瓶颈,直到2012年AlexNet一鸣惊人。但权值共享应该称得上是神经网络压缩和加速的第一次伟大尝试。卷积神经网络也是权值共享的神经网络的一种。接下来的模型加速和压缩,都是针对卷积神经网络模型的。
针对卷积神经网络模型的压缩,最早提出的方法应该是网络裁枝,LeCun在1989年就提出根据损失函数对各个参数的二阶导,来估计各个参数的重要性,再删去不重要的参数。后来又是到2012年之后,压缩方法更加多样,总体大约分为4种:网络裁枝、模型量化、低秩估计、模型蒸馏。下面我将对4种方法进行逐一介绍。
网络剪枝
我们先来看看当前深度学习平台中,卷积层的实现方式,其实当前所有的深度学习平台中,都是以矩阵乘法的方式实现卷积的(如图1左侧):

图1 卷积与矩阵乘法
网络裁枝有两个大问题需要考虑:
同时连接权重为参数矩阵的第j列;从输入矩阵(输入特征图经过im2col变换得到的矩阵)角度看,输入矩阵的第i行与输出矩阵第i行所有点都是连接的;从参数矩阵(参数张量经过reshape得到的矩阵)角度看,参数矩阵第j列为输出矩阵第j列所有点的连接权重。假设我们对图中输出矩阵紫色节点裁掉1个连接,即令参数矩阵(中间的矩阵)紫色列中某个参数为0,那么根据之前的分析,该参数的删去,一定会影响输出矩阵虚线列中的所有节点。这就是卷积神经网络裁枝的复杂性。第二,若无规律的删掉一些连接,即令一些参数为0,实际上无法压缩,因为在网络存储中,0也是按32位浮点数存储的,与其他参数的存储量相同。所以我们不能仅仅将删掉的参数设为0,而是要彻彻底底地删掉这些矩阵。
最简单的一种想法:直接删掉参数矩阵的某一列,对应的就是删掉一个filter,相应的输出特征图将少一个通道。而在下一个卷积操作时,这个输出特征图将变成输入特征图,带入到图1右侧的输入矩阵,少一个通道即少一个列,那么为了保证矩阵乘法正确,参数矩阵必须要对应删去一行,即所有filter都要删去一个通道,整体变化如图2所示。从上述介绍我们发现:若对某层卷积以filter单位裁枝,那么到下一层一定会有以channel单位的裁枝,这就是filter-level裁枝(图4中所示)
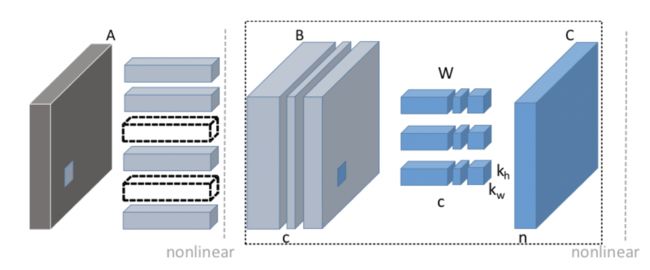
图2 filter-level剪枝[1]
第二个想法:我们若将3*3的kernel删成2*3或更小的kernel,对应到参数矩阵,即删掉了若干行,同样绝对有压缩的效果,而这种裁枝并没有改变channel的个数,虽然输入矩阵的列数需要减少,但这是在im2col操作中进行的(以kernel和stride不同设置,会生成不同的输入矩阵),对输入特征图与输出矩阵没有任何影响。
对第二个想法,我们可以进一步改进:如果将3*3的kernel删成某个固定的形状,例如下图中,那么我们可以修改im2col操作,保证卷积的正确性,这就是Group-level的裁枝(图4中所示)

图3 另类kernel(白色为0值)
第三个想法:如果我们不急着删去参数,而是将那些没用的参数设为0,当整个参数矩阵中有很多的0时,稀疏矩阵闪亮登场,于是矩阵的乘法可以用稀疏矩阵的乘法来代替,从而起到模型压缩和加速的效果。图4中,Fine-grained,vector-level,kernel-level中一些裁剪方法,需要使用到稀疏卷积的方法来实现。
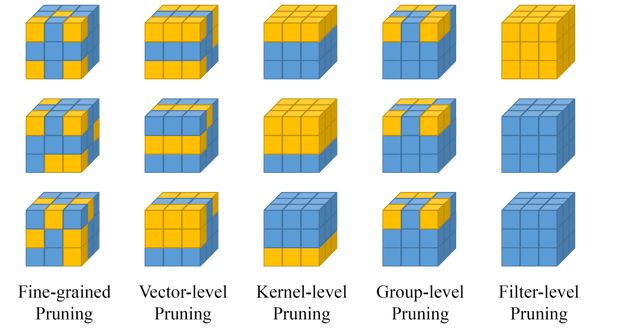
图4 裁枝类型图示[2]
上述是从矩阵方面,对裁枝方法进行了讲解,其实我们忽略了一个重要的问题:究竟什么样的参数需要裁掉呢?一般有两种方法:损失函数对参数的二阶导,和参数的绝对值大小。第一种方法,损失函数对参数的二阶导越小,说明这个参数的更新对损失函数的下降的贡献越小,说明这个参数不重要,可以删去。第二种方法,参数绝对值越小,说明输出特征图与该参数几乎无关,因此可以删去。相比较而言,第一种方法是尽可能保证损失函数不变,对结果影响相对较小,但计算复杂;第二种方法是尽可能保证每层输出特征图不变,而不管损失函数,计算方便,但对结果可能相对较大。但无论哪种方法都需要对裁剪后网络做参数调优。
低秩估计
低秩估计的方法其实就是运用了矩阵分解和矩阵乘法的结合律。此时我们仍需要回到图1左侧的示意图:对输入矩阵我们无法做分解,因为不同的前向传递中矩阵是变化的,但是参数矩阵是固定的呀,那么何不分解参数矩阵呢?低秩估计就是这么个想法:
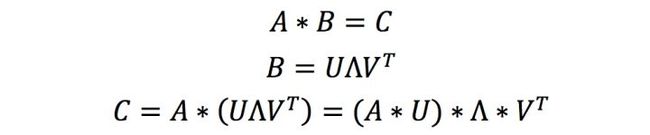
看上面的这个式子是不是感觉特别简单,只要我们可以用若干小矩阵对参数矩阵进行估计,那么输出矩阵就可以通过上面的式子得到。
在当前的很多对低秩估计的研究中,笔者认为奇怪的一点是:对矩阵分解后,将分解后的矩阵乘法又转回成卷积操作,例如上式中将原参数矩阵分解成3个小矩阵,那么在实现中就是用3个卷积来实现分解后的矩阵乘法。笔者认为这种操作实际上是增加了计算量,因为卷积需要经过im2col过程才可以转变成矩阵乘法,所以为什么不直接实现新的层或Op来做3个矩阵乘法呢?那么相对于用卷积实现,其实是少了2个im2col的过程。当然这是笔者的思考,还没有经过实验验证,如果有不同的想法或者实验结果,希望可以拿出来一起分享。
除矩阵分解以外,我们也可以直接对张量进行分解,而且卷积也符合结合律,那么上式中的乘法即变成了卷积,矩阵变成了张量,如下式以tucker分解为例:

同样可以得到更小的参数张量和与原输出相似的输出矩阵。下面我们以Tucker张量分解为例,分析一下低秩估计方法的压缩和加速效果。Tucker分解是对张量直接进行分解,其分解效果如图5所示

图5 Tucker分解
原卷积经过分解成3个计算量更小的卷积,卷积核通道数如图中所示,那么分解前后计算量为
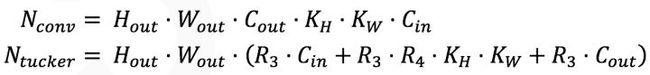

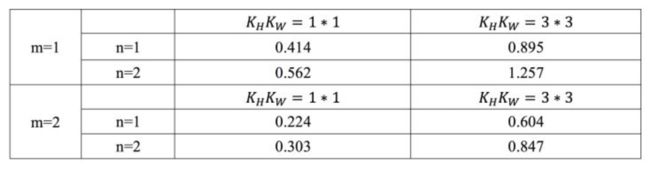
由表所示,若要求加速至少2倍,在卷积核大小为3*3,卷积输出通道数等于输入通道数时,tucker分解的中间卷积通道数最大是原来的0.604倍。当然中间通道数越小,可实现的加速和压缩效果越好;而为了保证准确率,中间通道数越大,分解后的张量还原回原张量的误差越小,这就是速度与准确率之间的权衡,也是低秩估计方法的共性。
低秩估计的方法的优势在于,没有改变基础运算的结构,不需要额外定义新的操作。分解后的网络仍是用卷积操作来实现的,所以其适用面比较广泛。分解方法多种多样,任何矩阵或张量分解的方法都可以应用其中,但一般分解后的网络都需要参数调优,以保证分解后网络模型的准确率。
低秩估计方法存在一个待解决的问题,就是保留多少秩是不明确的。保留太多的秩可以保证准确率,但加速压缩效果不好;保留秩太少,加速压缩效果好,但准确率很难保证。曾经有工作提出先训练低秩的参数矩阵,即在损失函数中加入对参数矩阵秩的考虑,然后再对训练好的低秩网络做低秩估计,由于本身参数矩阵中很多列向量都是线性相关的,所以可以保留很少的秩进行分解。
模型量化
无论是网络裁枝,还是低秩估计,我们从矩阵乘法入手(图1很重要),想方设法将参与计算的矩阵变小,直观地减少参数量和计算量。相比于前两种方法(他们注重计算数量的减少),模型量化则着眼于参数本身,实际上模型量化的大多方法并没有改变模型的计算数量。
如果我们可以用有限的几个参数来估计连续的实数域,那么就不用每个位置都存参数了,我们只需要存储有限的几个参数,和每个位置对那几个参数的索引不就行了么?索引可以用整数来表示,如果我们存储的参数为256个,那么只需要8-bit整数就可以索引,相比于所有位置都存32bit的浮点数,模型的存储量可以下降到原来的1/4。
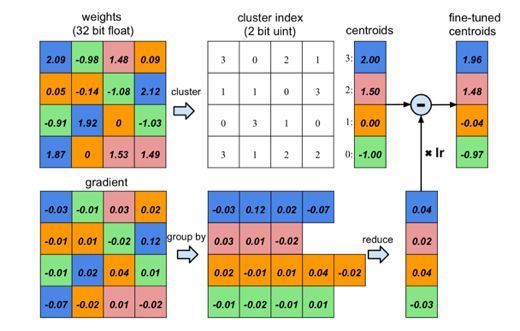
图6 参数聚类编码[3]
再进一步,如果我们将计算也改成8-bit整数的计算,移动端和嵌入式设别的CPU处理整数的计算速度要快于浮点数,那么这种网络不就可以在不改变连接数和参数个数的前提下,压缩和加速网络了么?这种想法就是模型的定点化。
将32-bit浮点数运算转化为更低位的整数运算,常见的是8-bit整数运算或1-bit二值运算。思想十分简单,以8-bit整数为例,记录当前参数的最大值和最小值,设为mini, maxi。则所有参数量化结果为
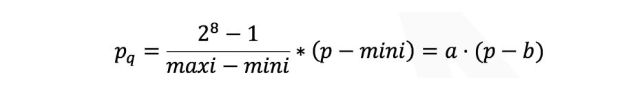
于是所有浮点数都可以转化为整数运算,但这种方法存在2个困难:第一,若两个值的mini, maxi值不相等,运算比较复杂;第二,由于存在系数和偏差,所以浮点数的加法与乘法需要额外一些运算才能还原。对这两个个问题,我们可以采用简单的代数运算的得到结果,以乘法为例。
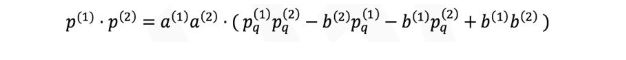
有兴趣的读者可以进一步参考gemmlowp库中的说明文档,或者自己推导一下加法的运算。那么基础理论就到此为止,在当前的深度学习平台中,Tensorflow给出了定点化的Op操作,下面我将详细介绍Tensorflow平台的定点化流程,如图7所示。
输入数据为浮点数类型,第一经过QuantizeV2节点,得到量化后的数据,该节点实际输出有三个:量化数据,最大值,最小值。即通过这三个数据即可恢复原始浮点数;第二进行量化的卷积操作,输入为量化数据、数据的最大值最小值、量化参数、参数的最大值最小值,共6个,输出有3个,量化卷积结果(32-bit整数)、量化结果的最大值和最小值;第三,量化结果与其范围输入到Requantize节点,做复量化,目的在于将32-bit整数重新量化成8-bit整数;第四,经过Dequantize节点,将8-bit整数还原成浮点数类型。实际上这种单元的输入与输出仍是浮点数,那么我们是否可以将网络完全转化为整数的运算呢?这就是tensorflow定点化的最后一步:
在对所有卷积做上述量化操作后,遍历整个网络,倘若存在Dequantize节点与QuantizeV2节点相邻的情况,就删掉这两个相邻节点,如图7(b)所示。所以最终网络完成了由浮点数到整数的转变
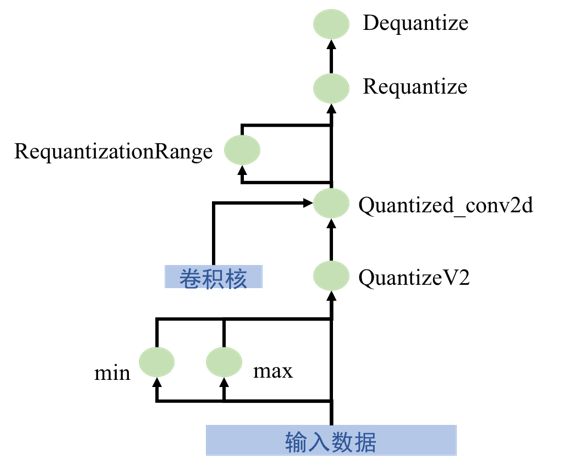
(a)运算单元

(b)去除冗余节点
图7 tensorflow量化计算过程
注意:经过笔者的实验,Tensorflow在移动端的Tensorflow Lite,就是利用上述的方法,专门针对移动设别的硬件条件做了优化,定点化的模型实际有4倍的提速。但是笔者在PC端使用定点化量化模型,虽然压缩效果不错,但并没有提速效果,网络前向传递速度反而有下降,笔者在Tensorflow社区与github中进行了调查,也有很多研究者遇到了相同的问题,且并没有很好的解释,如果有读者经过实验验证了定点化在PC端的可行性,或可以指出问题所在,希望可以拿出来一起交流。
模型蒸馏
前三个方法是在一个特定模型结构的基础上,对网络进行压缩和加速,而模型蒸馏则“剑走偏锋”直接设计了一个简单结构的小网络,那小网络的准确率怎么和大网络比呢?Hinton前辈提出了一个非常简单且有效的方法——网络蒸馏。主要思想是用预训练好的网络(通常结构较复杂,准确率较高),来指导小网络的训练,并使小网络达到与复杂网络相近的准确率。大网络类比于老师,小网络类比于学生,老师经过漫长时间的“训练”摸索出一套适用于某个任务的方法,于是将方法提炼成“知识”传授给学生,帮助学生更快地学会处理相似的任务。整个思想中最大的难题在于如何有效地表达“知识”,并有效地指导小网络的训练。其整体结构如图8所示

图8 模型蒸馏结构
图中蓝色部分为教师网络,网络参数由预训练好的参数初始化,并在训练过程中固定;绿色部分为学生网络,网络结构相对简单,通过训练学习参数;红色部分为指导损失函数,一般选取均方误差损失函数,用于指导学生网络学习教师网络的输出。原网络由相似结构的网络块组成,每个网络块中有若干个单元,小网络和大网络包含相同个数的网络块,但每个网络块中的单元个数比大网络小。整个网络的损失函数包括原本任务的损失函数,和大网络对小网络的指导损失函数,其中指导损失函数为每个网络块输出特征图的均方误差,如下式所示






图9 两个损失函数的相互误导
如图9所示为两个损失函数的相互误导,假设仅有x,y两个参数,z方向代表损失函数的值,两个蓝色线分别表示指导损失函数与任务损失函数与x,y两个参数的关系,设某次迭代前,参数恰好到了两条线的交点,即两个损失函数相等(实际中很难这样),红色箭头表示向量,是两个损失函数更新的方向和大小,那么参数的实际更新大小和方向即为两个向量的和,其方向可能并不是向参数最优解更新。当参数个数更多时,参数空间更加复杂,更容易引起训练的错误。
笔者经过实验,发现如果先单独对指导损失函数进行训练,然后再加入任务损失函数联合训练,得到的模型效果将会比直接联合训练得到的模型好很多。如果读者有不同的发现或理论推导,希望可以一起交流。
其实现如今的研究工作中,对模型蒸馏没有很成熟的理论支撑,大多研究也仅是以形而上的方式,类比Hinton提出的方法。尤其在损失函数设计和指导位置选取上,并没有明确的说明,只是经验性地使用均方误差为损失函数(表达两个特征图或特征向量的距离),选取网络最后一层特征向量或特定结构的输出特征图作为指导位置。所以模型蒸馏方法仍有很大的研究空间。
总结
本文介绍了比较常见的4种卷积神经网络压缩和加速方法,其中网络裁枝与低秩估计的方法从矩阵乘法角度,着眼于减少标量乘法和加法个数来实现模型压缩和加速的;而模型量化则是着眼于参数本身,直接减少每个参数的存储空间,提升每次标量乘法和加法的速度,从而实现模型的压缩和加速;模型蒸馏方法却是从宏观结构入手,直接构造了结构简单,参数少的小网络,将难点转移成对小网络的训练上。
在实际应用中针对特定的网络模型,这些方法可以互相融合,同时处理一个网络。甚至对于一些较深层的网络,可以在某些层使用裁枝方法,在其他层使用低秩估计方法。对卷积神经网络模型压缩和加速的研究才刚刚开始,还有很多值得探索的方法有待挖掘。
参考文献
1、He Y, Zhang X, Sun J. Channel pruning for accelerating very deep neural networks[C]//International Conference on Computer Vision (ICCV). 2017, 2: 6.
2、Cheng J, Wang P, Li G, et al. A Survey on Acceleration of Deep Convolutional Neural Networks[J]. arXiv preprint arXiv:1802.00939, 2018.
3https://blog.csdn.net/yixianfeng41/article/details/73009210
4http://www.xiongfuli.com/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2016-06/tensor-decomposition-tucker.html
5、Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
6、Romero A, Ballas N, Kahou S E, et al. Fitnets: Hints for thin deep nets[J]. arXiv preprint arXiv:1412.6550, 2014.
7、Kim J, Park S U K, Kwak N. Paraphrasing Complex Network: Network Compression via Factor Transfer[J]. arXiv preprint arXiv:1802.04977, 2018.
8、Li Q, Jin S, Yan J. Mimicking Very Efficient Network for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 7341-7349.
9、Wei Y, Pan X, Qin H, et al. Quantization Mimic: Towards Very Tiny CNN for Object Detection[J]. arXiv preprint arXiv:1805.02152, 2018.
10、Mehta R, Ozturk C. Object detection at 200 Frames Per Second[J]. arXiv preprint arXiv:1805.06361, 2018.
推荐文章
[1]机器学习-波澜壮阔40年SIGAI 2018.4.13.
[2]学好机器学习需要哪些数学知识?SIGAI 2018.4.17.
[3]人脸识别算法演化史SIGAI 2018.4.20.
[4]基于深度学习的目标检测算法综述SIGAI 2018.4.24.
[5]卷积神经网络为什么能够称霸计算机视觉领域?SIGAI 2018.4.26.
[6]用一张图理解SVM的脉络 SIGAI 2018.4.28.
[7]人脸检测算法综述SIGAI 2018.5.3.
[8]理解神经网络的激活函数SIGAI 2018.5.5.
[9]深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读SIGAI 2018.5.8.
[10]理解梯度下降法SIGAI 2018.5.11.
[11]循环神经网络综述—语音识别与自然语言处理的利器SIGAI 2018.5.15
[12]理解凸优化SIGAI 2018.5.18
[13]【实验】理解SVM的核函数和参数SIGAI 2018.5.22
[14] 【SIGAI综述】行人检测算法SIGAI 2018.5.25
[15]机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上) SIGAI 2018.5.29
[16]理解牛顿法SIGAI 2018.5.31
[17]【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题 SIGAI 2018.6.1
[18]大话Adaboost算法SIGAI 2018.6.2
[ 19]FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法SIGAI 2018.6.4
[20]理解主成分分析(PCA)SIGAI 2018.6.6
[21]人体骨骼关键点检测综述SIGAI 2018.6.8
[22]理解决策树SIGAI 2018.6.11
[23]用一句话总结常用的机器学习算法SIGAI 2018.6.13
[24]目标检测算法之YOLOSIGAI 2018.6.15
[25]理解过拟合SIGAI 2018.6.18
[26]理解计算:从√2到AlphaGo ——第1季 从√2谈起SIGAI 2018.6.20
[27]场景文本检测—CTPN算法介绍SIGAI 2018.6.20
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。
更多原创干货请搜索关注SIGAI微信公众号
作者:SIGAI
链接:https://www.jianshu.com/p/cbb50e52a190
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。