0.abstract
本文主要对主流的三类object detector进行了speed-accuracy trade-off上的比较。
三类”meta-architectures”:faster rcnn 、r-fcn以及ssd
faster rcnn和r-fcn是region-based detector,不同的是,faste rcnn里面box classifier用的是强分类器,而r-fcn里面的box classifier相对可以看成弱分类器的组合。
ssd(这里包括了yolo等)是region-free detector
作者主要探讨了不同的feature extractor、image resolution、以及对于faster rcnn和r-fcn来说,number of proposals对检测器性能(精度、速度、内存使用)的影响
1.Motivation & contribution
目前主流的目标检测框架缺乏相互之间各方面的对比,因此作者在tensorflow上将各个主流的检测算法都实现了一遍,用来对比不同检测算法,当然这里对比的都是各个算法的single model,也就是说不使用ensemble。
作者主要的两点发现是:
1. 在Faster R-CNN中,使用更少的proposals能够使系统的速度有显著提升,而且不会造成精确度上较多的损失,从而使得其与SSD、R-FCN等相比后更具竞争力。
2. 相比于Faster R-CNN和R-FCN,SSD对于特征提取器的质量更为不敏感。
2.Meta-architecture
文中主要关注三种最近的meta-architectures:SSD,Faster R-CNN和R-FCN。虽然提出这三种方法的论文中都使用了特定的特征提取器,本文中将会对这三种元结构从特征提取器中进行进行分离,从而使得它们可以使用任意的特征提取器。
Single Shot Detector (SSD):文中将SSD定义为使用单个前馈神经网络来直接预测类别和 anchor offsets,并不要求stage per-proposal分类操作。Multibox和RPN都使用了这一方法来预测类不可知(class-agnostic)的proposals。
Faster R-CNN:detection分两步走。第一步产生region proposals,中间层的一些特征(例如VGG16中的conv5)被用于预测box proposals。第二步利用这些box proposals在同一层来裁剪特征并将它们送入特征提取器的剩下几层(例如fc6和fc7)来获得所属类别并修正proposals。
R-FCN:与Faster R-CNN不同的是,R-FCN是在产生预测region proposals的那一层的前面一层对特征进行裁剪而非与预测同一层。这样做的好处在于每个区域所需的计算总量实现最小化。
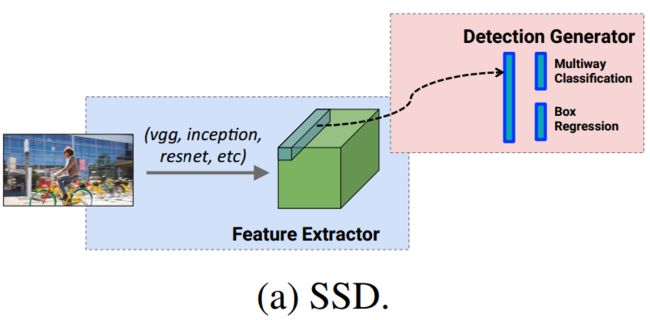
SSD结构,region-free / single shot 直接得出分类和anchor offsets
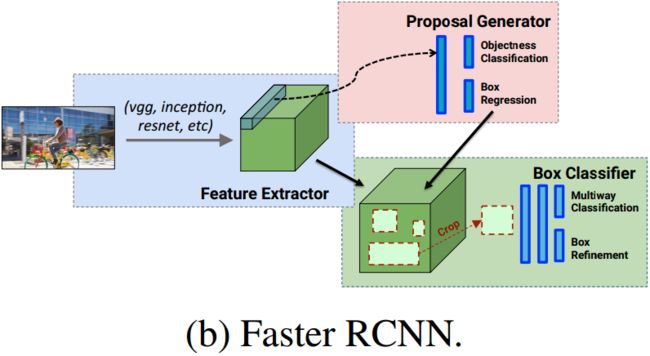
faster rcnn结构:region-based / 每一个proposal需要经过后面的sub-network 。 需要利用proposal generator先得出分类和proposals然后将box proposals再送回预测出它们的中间层进行对特征的crop,最后送入fc6和fc7(图中用蓝色矩形表示),得出最终结果(两个蓝色小矩形)
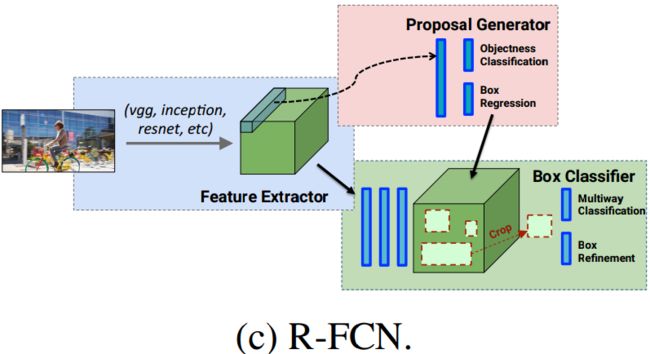
R-FCN结构:region-based / feature map经过一次sub-network,每一个proposal通过ps roi-pooling即可得到预测量。 Box Classifier这一步中box proposals被送回到特征层的最后一层(也就是图中三个蓝色矩形后面的那一层),紧接着就是预测层了(蓝色小矩形)。
3.Architecture configuration
3.1feature extractor
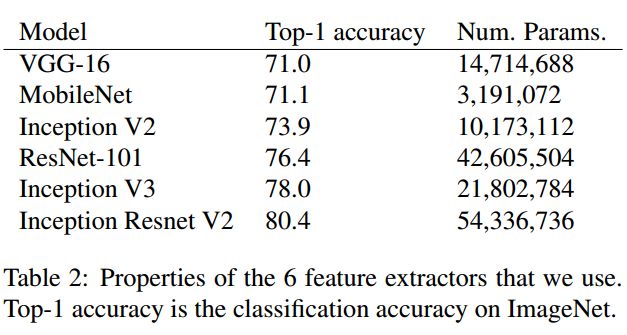
作者主要选择了6种常用的feature extractor:vgg16/resnet-101/inception-v2/inception-v3/inception resnet-v2/mobilenet
下图表示各个feature extractor在imagenet上的精度和参数的数目
3.2 number of proposals
对于faster rcnn和r-fcn,原论文都是选择300个proposal进行实验。作者在本论文中将proposal的数目在10到300取值进行实验。
3.3 output stride setting
对于resnet和inception resnet,output stride可以设置为16和8
3.4 loss function
所有实验模型的loss function都是采用smooth L1 loss
3.5 input size configuration
训练的时候每一个模型都训练一个high-resolution版本和low-resolution版本
对于Hi re:设置短边为600
对于Lo re:设置短边为300
3.6 traing and hyperparameter tuning
对于原版的faster rcnn和r-fcn,作者用的是4-stage training strategy,在本文中,作者用end-to-end的方式训练所有的模型
另外,作者将faster rcnn和r-fcn中的roi pooling替换成了crop_and_resize层(用双线性插值的方法将proposal resample到fixed size)
3.7 benchmarking procedure
测试图片需要将短边resize到300或者500,测试时间是在500张图上的平均,内存占用是在3张图片上取平均;
测试集为COCO,标准为MAP@IOU[0.5:0.05:0.95]
4.Results
4.1accuracy vs time
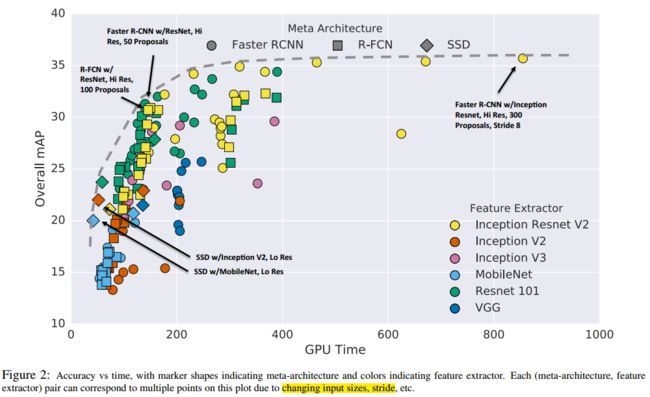
可以看到:
最快的模型应该是SSD w/MobileNet Lo Res
较好的speed/accuracy折衷是 faster rcnn w/Resnet Hi res 50 proposals和R-FCN w/Resnet Hi Res 100 proposals.
精度最高的是faster rcnn w/Inception resnet Hi res 300 proposals output_stride=8
总的来说:
R-FCN和SSD模型速度较快,Faster R-CNN速度相对较慢但是精确度较高。但是如果我们限制region proposal的个数,Faster R-CNN也可以达到相同速度。图中也画出了一条虚线,即optimality frontier,意味着如果要到达这条虚线上的点的精确度那么就必须牺牲速度。
4.2 the effect of feature extractor
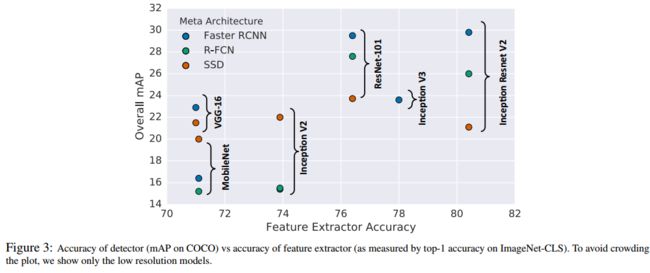
图三表明在分类和检测这两个方面的确有很大的联系,但仅限于FasterR-CNN和R-FCN。
对于faster rcnn和r-fcn,一般来说,feature extractor在classification teask上的准确率越高,对应的detector的performance越好,对于SSD来说,对feature extractor的性能不那么敏感。
4.3 the effect of object size
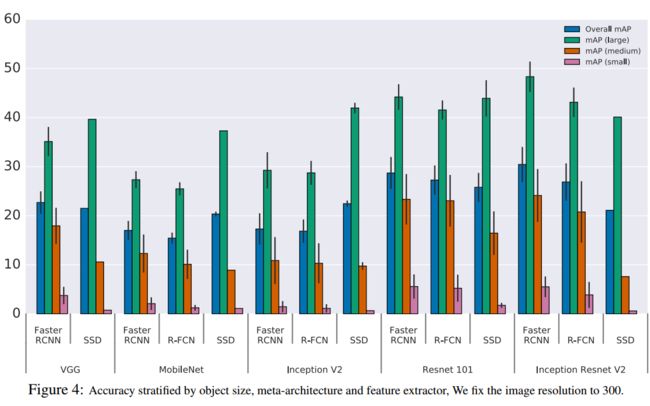
可以看到的是,所有的模型在大的目标上的检测效果都很好,SSD在小目标的检测效果上明显要比faster rcnn和r-fcn系列要差。
4.3 the effect of image size
图片的分辨率对检测的精确度有影响,本实验中降低两个百分点分辨率会持续导致精确度的下降,但同时也减少了使用时间
4.4 the effect of the number of proposals
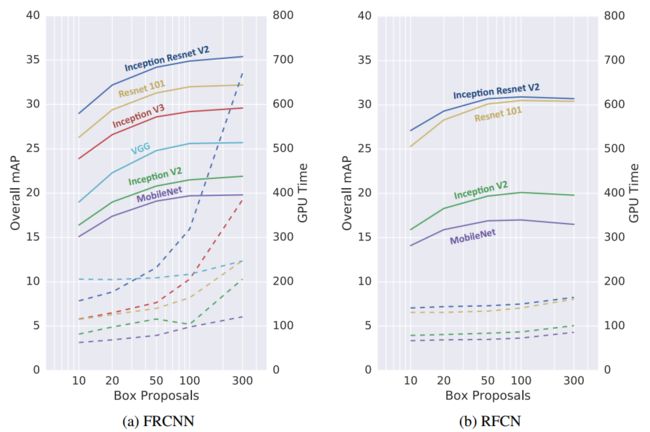
横轴表示proposal的数量,实线表示mAP,虚线表示GPU time。可以看到,对于faster rcnn来说,可以在不怎么损失mAP的情况下,减少proposal的数量,从而提高速度。
但是对于r-fcn来说,减少proposal的数目并不能得到更好的speed-accuracy trade.
这是因为r-fcn把原来faster rcnn的roi pooling移到了网络的最后一层,这样所有proposal的计算量就大大减少了,降低proposal的数目对速度的影响也就不大。
4.5 memory analysis
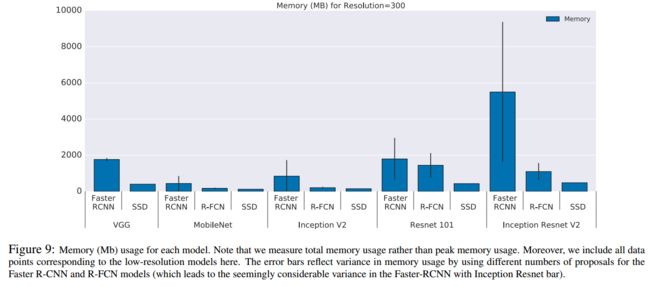
不同模型的GPU内存占用量,实现表示使用不同数目的proposal带来的variance。
4.6
作者在实验中还发现,mAP@0.75和常用的COCO指标mAP@[0.5:0.95]高度相关,因此,在0.75IOU下表现好的模型,在所有的IOU阈值下的表现应该也都不错。
4.7 state-of-art performance on COCO

最后,作者将实验中几个表现较好并且相互之间比较互补的模型ensemble起来,得到了state-of-art的性能。