更新 2018-08-09 本项目暂时告一段落咯~
这个项目目前只留下一个词云没有做完,其余内容都过了一遍。
学到的东西包括:
scrapy爬虫的设置
- requests(一个用来发送HTTP请求的简单库)
- BeautifulSoup(一个从HTML和XML中解析数据的库)
MongoDB的用法
- MongoBooster可视化工具
Pyecharts可视化工具
re正则表达式库
- 贪婪模式
- 懒惰模式
系列文章
python爬虫实战(1) -- 抓取boss直聘招聘信息
python爬虫实战(2) -- MongoDB和数据清洗
python爬虫实战(3) -- 数据可视化
实验内容:使用pyecharts将之前爬取的数据通过图形化显示出来
参考:https://segmentfault.com/a/1190000012429530
其实这次没得参考啦,因为原作者没写过程,直接把最后的图表丢出来了T_T
我先自己研究一下吧~
01 pyecharts初体验
请教大牛后得知,想要实现这种效果,需要使用pyecharts
于是我使用pip install pyecharts
过程略坎坷,遇到几次报错,不太明白,智能重复上述命令,结果两三次之后,安上了。
跑个代码实验一下
import pyecharts
bar = pyecharts.Bar(title="myBar",subtitle="xxx data")
attr =['a','b','c','d','e','f']
v1 = [1,2,3,4,5,6]
v2 = [3,5,2,1,5,1]
bar.add('test1',attr,v1,is_stack=True)
bar.add('test2',attr,v2,is_stack=True)
bar.render()
一实验发现,能生成html文件,good
但是Jupyter notebook生成的都是空白!类似下面这样:
这样可不方便呀,于是百度了很多办法,终于找到pyecharts的开发者回复的一种解决方案:
安装之前先执行一次
pip uninstall pyecharts
卸载原有版本后再pip install pyecharts==0.1.9.5
试验后,发现这个办法可行,现在Jupyter notebook可以显示啦~
附上2个参考
1.惊艳的可视化--飞机航行图 http://python.tedu.cn/know/320402.html
2.pyecharts官方文档(图表配置极其强大,什么都有,词云、热力图、等等) https://pyecharts.readthedocs.io/zh/latest/zh-cn/jupyter_notebook/
http://pyecharts.org/#/zh-cn/jupyter_notebook?id=%E7%A4%BA%E4%BE%8B
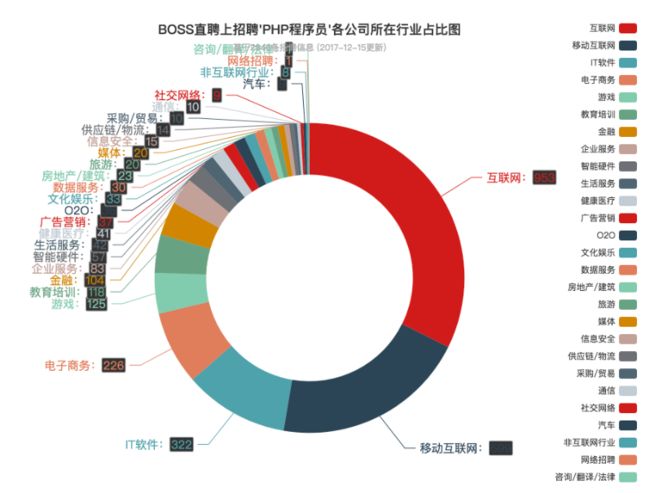
02 提取数据并绘制饼图
先绘制一个工作经验分布饼图
代码如下
experience = ["应届生","1年以内","1-3年","3-5年","5-10年","10年以","不限"]
value = []
for i in range(len(experience)):
value.append(db.Python_jobs.count_documents({"experience": experience[i]}))
print(value)
import pyecharts
chart_experience = pyecharts.Pie("工作经验扇形图")
chart_experience.add('test1',experience,value,is_label_show = True)
chart_experience
效果如下
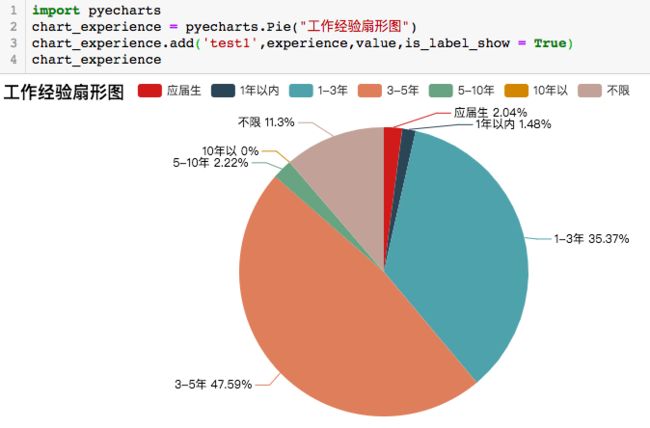
- 主要难点
在于mongodb提取数据的数据库命令
以及list循环
- 命令小记
len(list) 获取list元素个数
list.append() 向list中添加新元素
db.collection.count_documents('name':'value') 获取表中某变量的个数
03 用柱状图显示薪资
实现思路:
1 从数据库中取出所有应届生最低工资,累加,除以应届生数量,得到应届生最低薪资水平均值,放入salary_low
2 以此类推,循环取出其他工作经验的最低薪资平均值,放入salary_low中
3 以此类推,得到salary_high,与salary_low计算得到salary_avg
4 通过pyecharts显示出来
5 其中的数据结构就是list,exp是list,每个工作经验包含salary_low/avg/high
代码:
#04 薪资分布柱状图
from pyecharts import Bar
exp = ["应届生","1年以内","1-3年","3-5年","5-10年","10年以上","不限"]
salary_low = []
salary_high = []
salary_avg = []
i = 0
for i in range(len(exp)):
items = db.Python_jobs.find({'experience':exp[i]})
low_sum = 0
high_sum = 0
for item in items:
dictionnary = item['salary']
#print(dictionnary)
low_sum = dictionnary['low'] + low_sum
high_sum = dictionnary['high'] + high_sum
try:
salary_low.append(round(low_sum/value[i]))
salary_high.append(round(high_sum/value[i]))
salary_avg.append(round((salary_low[i]+salary_high[i])/2))
except:
salary_low.append(round(value[i]))
salary_high.append(round(value[i]))
salary_avg.append(round(value[i]))
#print(salary_low)
#print(salary_high)
#print(salary_avg)
bar = Bar("Python工程师薪资")
bar.add("最低薪资", exp, salary_low, is_label_show = True)
bar.add("平均薪资", exp, salary_avg, is_label_show = True)
bar.add("最高薪资", exp, salary_high, is_label_show = True)
bar
实现效果:
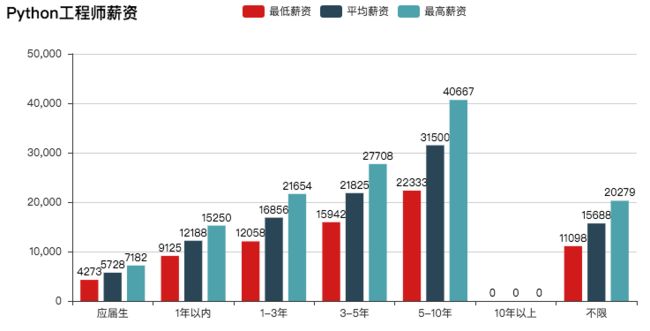
04 用扇形图显示领域
思路
数据总量 540条招聘信息
一、分几类(industryField相同算一类)
二、每一类多少条招聘信息
找了很久,终于找到mongodb中的Mapreduce方法可以用来实现
db.Python_jobs.mapReduce(
function() { emit(this.industryField,1); },
function(key, values) {return Array.sum(values)},
{
out:"non"
}
)
(执行完上面这条命令,其实把数据存入了另一个collection “non”中
显示的结果和上面的代码+find()一样)
在mongobooster查询结果如下
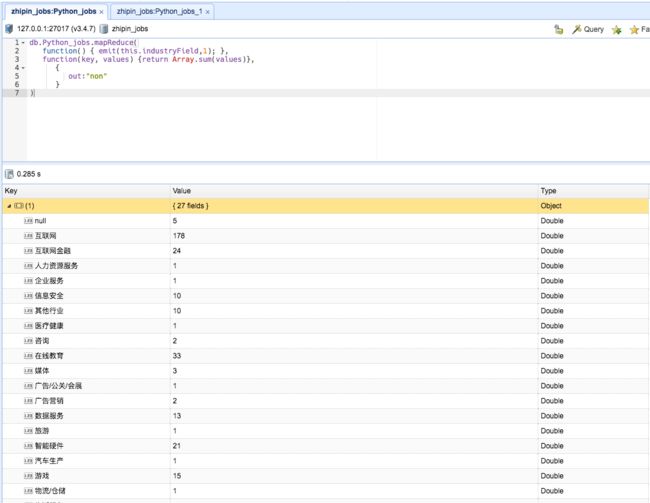
对Mapreduce()函数的说明
map: function() {emit(this.cat_id,this.goods_number); }, # 函数内部要调用内置的emit函数,cat_id代表根据cat_id来进行分组,goods_number代表把文档中的goods_number字段映射到cat_id分组上的数据,其中this是指向向前的文档的,这里的第二个参数可以是一个对象,如果是一个对象的话,也是作为数组的元素压进数组里面;
reduce: function(cat_id,all_goods_number) {return Array.sum(all_goods_number)}, # cat_id代表着cat_id当前的这一组,all_goods_number代表当前这一组的goods_number集合,这部分返回的就是结果中的value值;
out: pyecharts处理结果如下
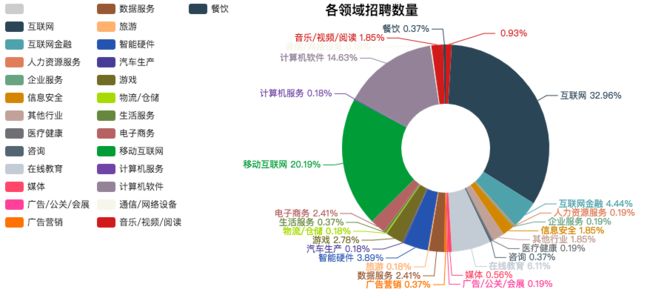
代码如下:
#04.1 数据处理
industryFieldKey = []
industryFieldValue = []
cursor = db.non.find() #这个non就是之前db指令生成的新collection
for c in cursor: #如果不用cursor的话,只能看到16进制的游标值
#print(c)
industryFieldKey.append(c['_id'])
industryFieldValue.append(c['value'])
print(industryFieldKey)
print(industryFieldValue)
#04.2 可视化
from pyecharts import Pie
pie = Pie("各领域招聘数量", title_pos='center', width = 1000)
pie.add("", industryFieldKey, industryFieldValue, center=[60, 50], radius=[30, 70], label_text_color=None,
is_label_show=True, legend_orient='vertical',
legend_pos='left')
pie
欠缺之处 使用Mapreduce处理的时候没有排序输出,所以图像显示比较乱
后面有时间再完善吧~
学到的内容:
- Mapreduce 可以统计分组以及各分组数量
- mongodb collection中的内容,需要通过curser循环打印出来
05 用词云显示技术名词
思路
1 逐个打开页面
2 爬取label,放入MongoDB中
3 Mapreduce,排序
小发现
之前经常遇到jupyter notebook停止输出的问题
今天受不了了,google一下发现原来是这样:
[ * ]表示正在执行
编程[ * ]之后不要再重复敲了,否则就会停止输出
如果不小心敲了,那就点击上方栏目上的方块,停止运行,就好了。

1.逐个打开页面,print(label)完成 (更新于0801)
tags = soup.find("div", {"class": "job-tags"})
print(tags.text)
效果如下
2.将tags的内容保存到MongoDB中去
问题:取出来的值连在一起,而且存入数据库时前后都有\n
目前方法:
tags = soup.find("div", {"class": "job-tags"})
print(tags.text)
item['positionLables'] = tags.text
数据库存储效果:
研究内容:
如何使用soup.find将网页中PythonHadoop以list形式存入数据库?
3.使用第二层soup.find,提取list
tags = soup.find("div", {"class": "job-tags"})
lists = tags.find_all("span")
print(lists)
效果如下
[python爬虫, Web前端, Diango]
能够提取list了,只是还有需要去掉
更新 2018-08-04
从这个列表中提取字符真是搞死我了,这个列表不是普通的列表,里面不是字符串
列表类型是
里面的字符类型是
所以今天用正则去匹配的时候总是出问题!
如何把 taglists = [python爬虫, Web前端, Diango]
变成 taglists = ["python爬虫", "Web前端", "Diango"]
成立难倒我的课题
没关系,今天学到了正则表达式,也是蛮好的
import re
key = r"python爬虫"#这段是你要匹配的文本
p1 = r"(?<=).+?(?=)"#这是我们写的正则表达式规则,你现在可以不理解啥意思
pattern1 = re.compile(p1)#我们在编译这段正则表达式
matcher1 = re.search(pattern1,key)#在源文本中搜索符合正则表达式的部分
print matcher1.group(0)#打印出来
输出结果
python爬虫
科普两个点
- 第一点是?<=与?=
?<= 表示在匹配字符前必须有, ?=表示在匹配字符后必须有
比如 p = r"(?<=A)XX(?=B)"
表示要匹配的字符是XX
但是必须满足AXXB的形式 - 第二点是+? 贪婪模式和懒惰模式
[email protected]
p1 = r"@.+." #想匹配@到"."之间,即hit
结果是"@hit.edu."
为什么多了? 因为正则表达式默认是贪婪模式
[email protected]
p1 = r"@.+?." #在+之后加上?
结果是"@hit."
+?将贪婪模式改成了懒惰模式
放一个正则表达式讲的特别好的例子
https://www.cnblogs.com/chuxiuhong/p/5885073.html Python 正则表达式入门(初级篇)
有一本讲正则表达式的书挺不错的 《正则表达式必知必会》
更新 2018-08-09
做出了一周的努力,仍然没有办法使用soup find()方法提取岗位label,拖延已久,暂时告一段落吧。
这个项目目前只留下一个词云没有做完,其余内容都过了一遍。
学到的东西包括:
scrapy爬虫的设置
- requests(一个用来发送HTTP请求的简单库)
- BeautifulSoup(一个从HTML和XML中解析数据的库)
MongoDB的用法
- MongoBooster可视化工具
Pyecharts可视化工具
re正则表达式库
- 贪婪模式
- 懒惰模式
下一个研究内容是大数据分析工具 Hive,感兴趣的小伙伴请关注我的主页哟~