解决车辆的可变性需要全局特征来区分形状、颜色或品牌。解决相机可变性需要汽车部件跨方向的局部特征,如大灯、保险杠或贴花。
该文贡献:
- 使用metric loss+softmax loss作为损失函数,并使用归一化来投影从metric损失到softmax损失的特征。同时证明了使用LN比BN好。
- 通过使用全局注意网络来减少输入conv1层的稀疏性,改进了全局特征提取。同时,利用一种新颖的局部注意机制,从全局特征中自动检测和提取基于部分的特征。全局和局部特征在一个统一的网络中被合并。GLAMOR学会了在没有汽车零件、区域、方位或视图指导的情况下提取局部特征。GLAMOR使用单一的统一模型,相比于其它网络中的多个分支,模型更小,速度更快。
使用的基础模型和相关参数设置:(直接看英文就好)
Our base model uses ResNet18 as the backbone feature extractor, with group norm instead of batch norm. We show competitive results with our smaller model compared to most existing works that use larger models as the backbone extractor plus submodels, indicating our base model construction method is robust and well-suited for re-id (see Table 2). Images are resized to 208 × 208 with (i) random flipping, h = 0.5, (ii) normalization, and (iii) random erasing with pr = 0.5. We use only triplet loss, with α = 0.3 and batch hard mining and train with Adam optimizer, with lr =1e94, decaying every 20 epochs with decay factor 0.6. The base model achieves mAP of 64.48, with rank-1 63.9% and rank-5 86.2% after training for 100 epochs. With warmup learning rate, we achieve higher mAP. We test warmup-1 and warmup-2 (see 3.1), with base learning rate 1e94. Then, lr is decayed with γ = 0.6 every 20 epochs. Warmup-1 achieves mAP of 67.34; warmup-2 achieves lower mAP of 65.98, indicating smaller increases are more useful for re-id.、
还需要注意:
our base model is a ResNet with stride of 1 in the final pooling layer2 and no dense layers for the output features。
在该基础网络上,再是加上本文的改进方法:(i) 损失组合&标准化,也就是triplet loss+softma loss。(ii) 全局&局部注意力。

我看这篇论文主要是看下它的全局注意力和局部注意力,损失和标准化就没仔细看了。
全局注意力公式:
![]()
他的全局注意力机制只能放在第一个conv之后,残差块之前,为了使得更多的信息可以流向网络的后半部分,同时为了避免信息的损失,没有使用像CBAM中的平均池化和最大池化。
局部注意力他没有写注意力公式,使用的是Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV)这篇论文里的,即基于空间+通道的注意力机制
最终它得到的fatures:
![]()
MG表示全局注意力,FG表示输入到conv的特征,ML表示局部注意力,FL表示第一个bottleneck之后的特征。
最后是结果:
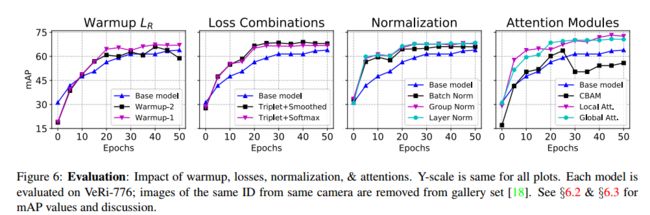
分别对应warm up、loss、标准化、注意力的实验。

veri-776上面对比最先进的结果。
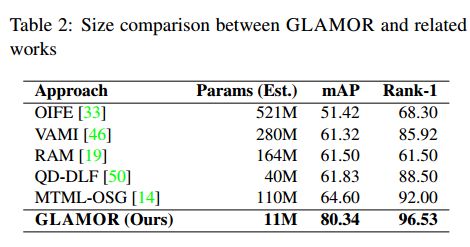
与其他相关工作对比。
看的比较浅,如有错误,请批评指正。