为了安装tensorflow,导致我Linux系统重装,Windows系统差点也没了,哎。。。
本人笔记本电脑有一个256 SSD和1TB机械硬盘,固态装C盘,机械硬盘装D、E和F,各330G,系统为Win10,显卡为NVIDIA1060。后来打算装manjaro双系统,进行编程和机器学习、深度学习的开发工作,于是F盘分了一半约160G给manjaro系统,其中根目录和家目录等单独划分分区挂载,根目录分区大小为30G,此是前话。
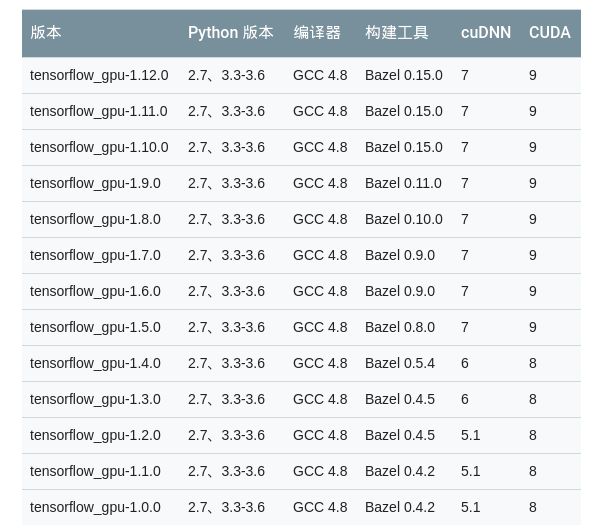
在安装tensorflow之前自己先装了pytorch,因为觉得这个框架代码更优雅,代码风格自己更喜欢。后来在安装tensorflow时发现还挺麻烦,需要独立cuda和cudnn库,不同版本的tensorflow依赖于不同版本的cuda和cudnn,而cuda和cudnn依赖于gcc,如下图所示。
而manjaro系统属于arch系,各软件包滚动更新速度很快,基本总是保持最新,比如系统默认python环境竟然时3.7.2,我的个乖乖,自己的系统里安装的gcc是此时最新的8.2.1,与cuda所需的gcc6冲突,如果要装gcc6还要卸载gcc8,而其他软件包会依赖于gcc8,况且安装旧版本包这种行为一点都不arch,于是使用tensorflow官方预编译好的whl文件安装就不太现实了,只能自己在本机上编译构建了,幸好网上搜到了一篇最近的、讲得很好很详细、和自己情况正相符的一篇帖子:编译 Tensorflow 1.10 + CUDA9.2 + MKL,在这里向作者由衷的表示感谢!
于是便红红火火按照教程开始来装了,于是问题旧开始出现了。
首先问题是当下载了tensorflow源码之后发现自己不能切换安装版本,如果选择默认master以外的分支,则报无法引用到/tensorflow/tools/bazel.rc文件的错误,于是只能在master分支装吧,不管了。
如图:
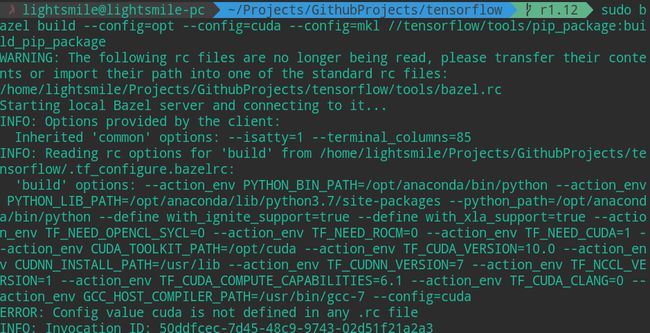
同时发现自己访问github下载文件的速度太慢了,导致bazel程序运行失败,后来找到了相关博客如git clone速度太慢的解决办法进行配置,发现还是未解决,自己在命令前加proxychains代理也不行,因为是程序内部调用系统网络去下载文件,代理命令无效,经过多次尝试后,自己打算通过浏览器下载一个文件试试,如https://github.com/bazelbuild/rules_closure/archive/9889e2348259a5aad7e805547c1a0cf311cfcd91.tar.gz,发现下载的挺快的,是因为代理,而自己直接调用wget命令发现好慢,同时还发现了该文件的最终下载域名为:codeload.github.com,后来自己参考那个教程在https://www.ipaddress.com/里搜索得到了对应的ip并将其和ip加到hosts文件中,如图所示:

速度一下就快了不少,虽说只有几十k,但是也比之前的几十几百b强,同时安装也不报下载文件失败访问不了文件的错误了。
后来又遇到:invalid conversion from 'const char*' to 'char*'这样的代码error,于是网上找到了invalid conversion from 'const char' to 'char' 的解决方法这篇文章,于是便修改了报错处的源码,重新继续编译,看着编译进行的挺顺利,自己还蛮开心的,可谁知命运给自己开的玩笑才刚刚开始。
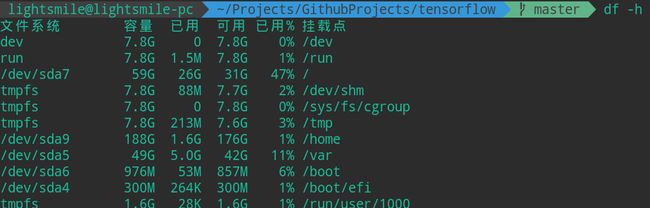
经过了漫长的编译时间,突然又报错了,说是什么文件访问失败,没有剩余空间了,当时我就蒙了,这是咋回事,后来发现:根目录所在分区满了,安装过程中所有文件都保存在根目录所在分区,即已经到了30G了,使用df -h命令查看所在分区使用率已经到了100%,我擦!!!
这可如何是好,没想到编译个tensorflow这么占存储空间,后来网上查找相关案例和解决方案,暂时只是把用不到的大软件卸载了,如Clion,发现效果不明显,还是占用了29G多,于是心想:老子不装了,不装了还不行吗,回归pytorch,pytorch才是老纸的真爱,卸载之后发现:使用率还是90%,这这这,后来想到满了那就扩充啊,于是就在网上找扩充根目录分区的方法教程,然而历史说明正是这一步开始使我踏进了深渊。
网上搜了不少方法,发现许多都不好使,同时分区满了我装个软件都装不了了,感觉要炸!发现有个说法说在拓展分区之前要先挂载,于是我就尝试着把根目录所在分区给挂载掉了,在卸载时还提示错误,说device is busy,于是网上找到类似如linux umount命令介绍与device is busy解决方法的答案,于是敲下了罪恶的umount -l /,后来系统崩了,重启,发现又好了,哈哈。
后来就想着硬盘F盘还有剩余空间,想划分出来给根目录所在分区,经过尝试之后发现直接划分不行,因为自己没有搞lvm,不能通过卷组或逻辑卷相关的指令操作来进行,后来发现了一个可行的法子是把硬盘中根目录所在分区位置后面的空间腾出来,然后便可以扩充了,把原来的数据放到其他位置就可以了,于是通过这样的操作进行了var挂载分区的移动,感觉还不错,其中主要参考的是linux(manjaro)磁盘迁移/opt /home,而在进行boot分区的移动时发现自己未成功进行boot分区的重新挂载,于是系统又崩了,重启也报错了,进入grub rescue模式中,此时有点慌了,后来找到类似该篇博客grub rescue救援模式的处理所说内容,重新挂载了boot目录,并且重新生成grub配置文件,于是问题解决了。
之后在进行home分区的操作时自己忘记了备份,直接挂载和格式化掉了(通过 mkfs.ext4 /dev/sda*),发现出了问题之后重新登录都登录不了,因为相关用户信息都没了,只能进入命令行界面,同时home目录为空,后来在各分区找了半天发现没有找到备份,这时自己真的慌掉了,还有不少数据呢,比如项目代码、还有博客环境配置和博客原文件等,找了半天都没能找到可行的办法,因为系统都登录不进去,连修复软件啥的都安装不了,况且天色已晚,于是就先睡了。
等到第二天自己想到可以在window系统上安装然后修复那个分区的数据吧?于是先尝试了DiskGenius软件,发现好像它识别的分区不全,并且也只能恢复文件,会丢失文件名等信息,这样也仅是得到一些文件,不是整体的恢复分区,而后又下载了testdisk软件,经过一阵蒙蔽的操作之后,发现自己的D盘和E盘也不见了,赶忙重启发现还是没有,由于许多软件都是安装在D盘上,所以导致window系统下的环境也出问题了,要炸啊,幸亏自己的chrome浏览器在C盘装的,又下载了DiskGenius,发现还要注册,还挺麻烦,于是又尝试下了绿色破解版,经过扫描,找到了丢失的D盘和E盘,只是其他数据全部都没有了(指manjaro系统下全部信息)。哎,一声长叹之后只能重新再装系统了。
只是可惜了当时探索了不少软件,同时还有不少有用的数据资料,还有自己最新的代码,以及最新的博客环境配置文件和最新的博客原文件。
而后再划分分区安装的时候,有了之前的教训和探索,自己对分区的理解更加深刻,于是在划分时感觉熟悉了好多,把整个300G空间全部给新系统了,同时多分配了一些空间给根目录和var目录所在分区。
后来重装系统,还好自己当时写了安装记录的博客在网上可以看,于是又重新安装配置环境,配置NVIDIA独显,配置科学上网,后来心想以后再做记录先只在和有道上吧,自己的博客先不管了吧,毕竟环境也丢了,能找到的是好久之前的了,要配置还挺麻烦,博客内容自己自己也增删改的比较多,再捡起来比较耗时,于是暂时就不考虑维护自己的博客了,之前也尝试在知乎专栏和上写文章,发现支持Markdown效果很好,而知乎则导入效果很差,于是便最终选择了作为最终的自己发布内容的平台啦。
后来重新参考之前提到的编译tensorflow的那篇文章,还是只能master分支,还是要配置hosts文件中github对应域名和ip,不过编译的还挺顺利的,不过还是要好久,最终吃了个晚饭,回来发现又报错了,我真的快要崩溃了,报ImportError: No module named keras.preprocessing的错误,后来我就想是不是版本问题,于是切换r1.12和r1.10,发现还是报bazel.rc文件的错,于是又切换回master分支,继续网上找相关问题和答案,并在github上成功找到了答案:1.10 build fails with "No module named 'keras_applications'" ,即通过pip安装keras_applications和keras_preprocessing这两个库。
后来重新执行编译命令,又等待了好一会儿(比之前快多了,因为有缓存之前的编译结果),终于成功了哈哈哈!后来经过测试,发现编译成功,tensorflow已经被正常安装在自己的pip列表中了。
以下是耗时截图:



安装tensorflow的whl包后,发现安装的就是现行版r1.12。。。
这里是分区使用率截图:
相比而言,pytorch安装就要简单许多了,并且提供了许多预编译好的可选。
在这里自己简单记录一下心酸的历程,也提醒各位看客同样需要编译tensorflow时留意自己的分区使用率~