这篇文章梳理一下zookeeper服务端的处理逻辑。简单起见,本文先看单机模式的逻辑,下一篇再说集群模式的逻辑。
一、执行过程概述
单机模式的ZK服务端逻辑写在ZooKeeperServerMain类中,由里面的main函数启动,整个过程可以分为如下几步:
第一步,配置解析:
解析配置(可以是指定配置文件路径也可以由启动参数设置),比如快照文件,日志文件保存路径,监听端口等等。
第二步,启动IO监听线程:
以NIO为例,ZK构建了一套IO模型,一个acceptThread,通过CPU个数计算出来的selectorThread以及一个worker线程池。其中acceptThread收到连接以后按照轮训策略交给selectorThread处理,selectorThread读取完数据以后交给worker线程池进行处理。
注:在ZK状态没有修改为RUNNING之前,IO线程虽然启动监听但不会真正接收请求。
第三步,加载数据:
我们知道ZK会定期把数据dump到磁盘,因此每次启动时都会根据第一步中配置的文件路径去读取数据文件,如果存在的话就加载配置,这样就可以用于数据恢复。
第四步,构造处理链
单机模式下,ZK的请求处理链路为PrepRequestProcessor -> SyncRequestProcessor -> FinalRequestProcessor
它们的职责如下:
PrepRequestProcessor处理器用于构造请求对象,校验session合法性等。
SyncRequestProcessor处理器用于向磁盘中写入事务日志跟快照信息。
FinalRequestProcessor处理器用于修改ZK内存中的数据结构并触发watcher。
这里要补充下,ZK中所有的数据都放在内存中,封装在类ZKDatabase里面,包括所有的节点信息,会话信息以及集群模式下要使用的committed log。也就是说处理链路上只有最后一步FinalRequestProcessor才会让数据真正生效。
第五步,启动服务
修改服务端运行状态,表示服务正式启动,IO线程开始接受请求。
二、源码分析
单机模式的启动类为:ZooKeeperServerMain,由于源码较长我们分为服务端启动过程跟请求处理过程两部分来看。
服务端启动过程
看下ZooKeeperServerMain里面的main函数代码:
public static void main(String[] args) {
ZooKeeperServerMain main = new ZooKeeperServerMain();
main.initializeAndRun(args);
}
protected void initializeAndRun(String[] args)
throws ConfigException, IOException, AdminServerException
{
ServerConfig config = new ServerConfig();
//如果入参只有一个,则认为是配置文件的路径
if (args.length == 1) {
config.parse(args[0]);
} else {
//否则是各个参数
config.parse(args);
}
runFromConfig(config);
}
//省略部分代码,只保留了核心逻辑
public void runFromConfig(ServerConfig config) throws IOException,AdminServerException {
FileTxnSnapLog txnLog = null;
try {
//初始化日志文件
txnLog = new FileTxnSnapLog(config.dataLogDir, config.dataDir);
//初始化ZkServer对象
final ZooKeeperServer zkServer = new ZooKeeperServer(txnLog, config.tickTime, config.minSessionTimeout, config.maxSessionTimeout, null);
txnLog.setServerStats(zkServer.serverStats());
if (config.getClientPortAddress() != null) {
//初始化server端IO对象,默认是NIOServerCnxnFactory
cnxnFactory = ServerCnxnFactory.createFactory();
//初始化配置信息
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false);
//启动服务
cnxnFactory.startup(zkServer);
}
//container ZNodes是3.6版本之后新增的节点类型,Container类型的节点会在它没有子节点时
// 被删除(新创建的Container节点除外),该类就是用来周期性的进行检查清理工作
containerManager = new ContainerManager(zkServer.getZKDatabase(), zkServer.firstProcessor,
Integer.getInteger("znode.container.checkIntervalMs", (int) TimeUnit.MINUTES.toMillis(1)),
Integer.getInteger("znode.container.maxPerMinute", 10000)
);
containerManager.start();
//省略关闭逻辑
} catch (InterruptedException e) {
LOG.warn("Server interrupted", e);
} finally {
if (txnLog != null) {
txnLog.close();
}
}
}
可以看到关键点在于解析配置跟启动两个方法,先来看下解析配置逻辑,对应上面的configure方法:
//依旧省略掉了部分逻辑
public void configure(InetSocketAddress addr, int maxcc, boolean secure) throws IOException {
maxClientCnxns = maxcc;
//会话超时时间
sessionlessCnxnTimeout = Integer.getInteger(ZOOKEEPER_NIO_SESSIONLESS_CNXN_TIMEOUT, 10000);
//过期队列
cnxnExpiryQueue = new ExpiryQueue(sessionlessCnxnTimeout);
//过期线程,从cnxnExpiryQueue中读取数据,如果已经过期则关闭
expirerThread = new ConnectionExpirerThread();
//根据CPU个数计算selector线程的数量
int numCores = Runtime.getRuntime().availableProcessors();
numSelectorThreads = Integer.getInteger(ZOOKEEPER_NIO_NUM_SELECTOR_THREADS, Math.max((int) Math.sqrt((float) numCores/2), 1));
if (numSelectorThreads < 1) {
throw new IOException("numSelectorThreads must be at least 1");
}
//计算woker线程的数量
numWorkerThreads = Integer.getInteger(ZOOKEEPER_NIO_NUM_WORKER_THREADS, 2 * numCores);
//worker线程关闭时间
workerShutdownTimeoutMS = Long.getLong(ZOOKEEPER_NIO_SHUTDOWN_TIMEOUT, 5000);
//初始化selector线程
for(int i=0; i 再来看下启动逻辑:
public void startup(ZooKeeperServer zkServer) throws IOException, InterruptedException {
startup(zkServer, true);
}
//启动分了好几块,一个一个看
public void startup(ZooKeeperServer zks, boolean startServer)
throws IOException, InterruptedException {
start();
setZooKeeperServer(zks);
if (startServer) {
zks.startdata();
zks.startup();
}
}
//首先是start方法
public void start() {
stopped = false;
//初始化worker线程池
if (workerPool == null) {
workerPool = new WorkerService("NIOWorker", numWorkerThreads, false);
}
//挨个启动select线程
for(SelectorThread thread : selectorThreads) {
if (thread.getState() == Thread.State.NEW) {
thread.start();
}
}
//启动acceptThread线程
if (acceptThread.getState() == Thread.State.NEW) {
acceptThread.start();
}
//启动expirerThread线程
if (expirerThread.getState() == Thread.State.NEW) {
expirerThread.start();
}
}
//初始化数据结构
public void startdata() throws IOException, InterruptedException {
//初始化ZKDatabase,该数据结构用来保存ZK上面存储的所有数据
if (zkDb == null) {
//初始化数据数据,这里会加入一些原始节点,例如/zookeeper
zkDb = new ZKDatabase(this.txnLogFactory);
}
//加载磁盘上已经存储的数据,如果有的话
if (!zkDb.isInitialized()) {
loadData();
}
}
//启动剩余项目
public synchronized void startup() {
//初始化session追踪器
if (sessionTracker == null) {
createSessionTracker();
}
//启动session追踪器
startSessionTracker();
//建立请求处理链路
setupRequestProcessors();
registerJMX();
setState(State.RUNNING);
notifyAll();
}
//这里可以看出,单机模式下请求的处理链路为:
//PrepRequestProcessor -> SyncRequestProcessor -> FinalRequestProcessor
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor)syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor)firstProcessor).start();
}
通过阅读上面的源码,我们可以看出ZK启动的时候开启了一系列的线程,要想了解线程的逻辑很显然是要从里面的run方法看起。
这里我们首先看一下过期连接关闭线程expirerThread的逻辑,原因是该线程逻辑比较简单,先热热身。
该类名为ConnectionExpirerThread,看下run方法:
private class ConnectionExpirerThread extends ZooKeeperThread {
ConnectionExpirerThread() {
super("ConnnectionExpirer");
}
public void run() {
try {
while (!stopped) {
//如果过期时间还没到则进行休眠
//注:这里是从一个队列中获取过期时间,要知道一个队列中保存了很多连接对象
//这里其实是该队列内部的逻辑会计算对用中所有连接里最快过期的时间,这个思路跟
//ScheduledExecutorService队列类似,感兴趣的同学可以参考下我之前写的
//关于调用线程池的源码解析文章
long waitTime = cnxnExpiryQueue.getWaitTime();
if (waitTime > 0) {
Thread.sleep(waitTime);
continue;
}
//如果已到达过期时间,则一一关闭连接
//注:这里虽然是调用了poll()方法,但返回是的一个集合,即该时间点全部过期的连接
for (NIOServerCnxn conn : cnxnExpiryQueue.poll()) {
conn.close();
}
}
} catch (InterruptedException e) {
LOG.info("ConnnectionExpirerThread interrupted");
}
}
}
这里补充一下过期会话管理的逻辑:
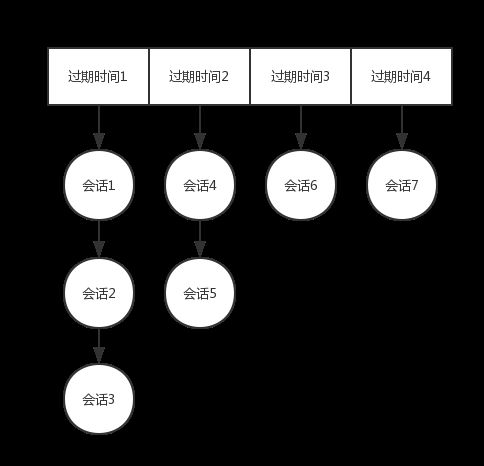
如上图,ZK维护了一个以过期时间作为key,以在该时间点过期的会话列表作为value的过期Map。由于Map是无序的,因此ZK增加了一个nextExpirationTime变量用来保存最近即将过期的时间,也是这个Map的key。
从该数据结构来看,我们可以得出两个结论:
- 过期会话的删除就是以过期时间为Key取出会话列表进行删除。
- 会话更新时需要对该会话进行迁移,即把会话从上一次过期时间对应的会话列表中删除并重新计算好下一次的过期时间加入该时间对应的会话列表中。
处理请求逻辑
我们以第一次建立连接并创建会话为例来说明一次请求的处理流程,从上面的分析可以知道需要先从AcceptThread线程源码开始看起:
public void run() {
try {
while (!stopped && !acceptSocket.socket().isClosed()) {
select();
}
} finally {
//省略
}
}
private void select() {
try {
selector.select();
Iterator selectedKeys = selector.selectedKeys().iterator();
while (!stopped && selectedKeys.hasNext()) {
SelectionKey key = selectedKeys.next();
selectedKeys.remove();
if (!key.isValid()) {
continue;
}
if (key.isAcceptable()) {
if (!doAccept()) {
//如果无法获取连接,则休眠一下,避免一直自旋
pauseAccept(10);
}
} else {
LOG.warn("Unexpected ops in accept select "
+ key.readyOps());
}
}
} catch (IOException e) {
LOG.warn("Ignoring IOException while selecting", e);
}
}
private boolean doAccept() {
boolean accepted = false;
SocketChannel sc = null;
try {
sc = acceptSocket.accept();
accepted = true;
InetAddress ia = sc.socket().getInetAddress();
//检查同一IP是否超过了最大连接数
int cnxncount = getClientCnxnCount(ia);
if (maxClientCnxns > 0 && cnxncount >= maxClientCnxns){
throw new IOException("Too many connections from " + ia + " - max is " + maxClientCnxns );
}
sc.configureBlocking(false);
//采用轮询的方式为新收到的连接分配一个selectorThread处理
if (!selectorIterator.hasNext()) {
selectorIterator = selectorThreads.iterator();
}
SelectorThread selectorThread = selectorIterator.next();
//把该连接加入到selector线程的acceptedQueue队列中
if (!selectorThread.addAcceptedConnection(sc)) {
throw new IOException(
"Unable to add connection to selector queue"
+ (stopped ? " (shutdown in progress)" : ""));
}
acceptErrorLogger.flush();
} catch (IOException e) {
acceptErrorLogger.rateLimitLog(
"Error accepting new connection: " + e.getMessage());
fastCloseSock(sc);
}
return accepted;
}
上面接收连接的结果就是把该连接加入到某个selector线程的队列中,那么接下来就看下selector线程的处理逻辑,同样是从run方法开始看:
public void run() {
try {
while (!stopped) {
try {
//上来就是一个select方法
select();
//看这个方法名字应该是处理上面提交的accept任务
processAcceptedConnections();
//方法名看为处理更新监听IO时间的请求,这个后面说
processInterestOpsUpdateRequests();
} catch (RuntimeException e) {
LOG.warn("Ignoring unexpected runtime exception", e);
} catch (Exception e) {
LOG.warn("Ignoring unexpected exception", e);
}
}
//如果推出循环了,则说明是关闭了,下面为一系列的关闭操作
for (SelectionKey key : selector.keys()) {
NIOServerCnxn cnxn = (NIOServerCnxn) key.attachment();
if (cnxn.isSelectable()) {
cnxn.close();
}
cleanupSelectionKey(key);
}
SocketChannel accepted;
while ((accepted = acceptedQueue.poll()) != null) {
fastCloseSock(accepted);
}
updateQueue.clear();
} finally {
closeSelector();
NIOServerCnxnFactory.this.stop();
LOG.info("selector thread exitted run method");
}
}
//这里我们暂时先跳过select方法,来看下处理连接的逻辑
private void processAcceptedConnections() {
SocketChannel accepted;
//从acceptedQueue队列中取出任务
while (!stopped && (accepted = acceptedQueue.poll()) != null) {
SelectionKey key = null;
try {
//对于新建立的连接首先是注册READ事件
//注:这里的selector对象是该SelectorThread对象自己初始化的,与其他的无关
key = accepted.register(selector, SelectionKey.OP_READ);
//封装一个新连接
NIOServerCnxn cnxn = createConnection(accepted, key, this);
//把该连接对象附加在SelectionKey对象上用于后面使用
key.attach(cnxn);
//保存该连接,里面包含两个逻辑,一个是用于开始判断同一IP下连接数时使
// 用的数据结构,一个是更新cnxnExpiryQueue队列中的过期时间
addCnxn(cnxn);
} catch (IOException e) {
// register, createConnection
cleanupSelectionKey(key);
fastCloseSock(accepted);
}
}
}
//明白了处理连接请求的逻辑,在来看下select方法
private void select() {
try {
//这里要注意这个selector对象是该类自己初始化的,与之前的逻辑无关
//这里就不上初始化代码了,只是一个Selector.open()返回的对象
//别的什么都没有
selector.select();
//进行IO事件处理
//注:这里初次进入的时候其实是空的,也就是说只有在
//processAcceptedConnections方法中添加了READ事件以后,这里
//才会真正返回事件
Set selected = selector.selectedKeys();
ArrayList selectedList = new ArrayList(selected);
Collections.shuffle(selectedList);
Iterator selectedKeys = selectedList.iterator();
while(!stopped && selectedKeys.hasNext()) {
SelectionKey key = selectedKeys.next();
selected.remove(key);
if (!key.isValid()) {
cleanupSelectionKey(key);
continue;
}
//如果可读或可写则进行IO处理
if (key.isReadable() || key.isWritable()) {
handleIO(key);
} else {
LOG.warn("Unexpected ops in select " + key.readyOps());
}
}
} catch (IOException e) {
LOG.warn("Ignoring IOException while selecting", e);
}
}
整理一遍上面的逻辑就是selectorThread运行的时候会落在selector.select()这里,直到accept线程添加了accept任务并唤醒它,被唤醒之后它首先会检查是否有读写事件,这在第一次运行是没有的,然后会检查是否有待处理的accept任务,此时会注册读事件,最后的更新监听事件逻辑processInterestOpsUpdateRequests后面再说,也就是直到处理完accept任务再回来从select中读取IO事件时才会有值。
顺着这个思路,假设第一个连接请求已经进来且经过了processAcceptedConnections的处理注册了读事件,接下来我们就该看看select()方法中的handleIO方法了:
private void handleIO(SelectionKey key) {
//封装request对象
IOWorkRequest workRequest = new IOWorkRequest(this, key);
NIOServerCnxn cnxn = (NIOServerCnxn) key.attachment();
//暂停该连接被select到
cnxn.disableSelectable();
//取消监听其他事件
key.interestOps(0);
//更新过期队列
touchCnxn(cnxn);
//调度worker
workerPool.schedule(workRequest);
}
重点逻辑现在落在了worker中,上代码:
public void schedule(WorkRequest workRequest) {
schedule(workRequest, 0);
}
public void schedule(WorkRequest workRequest, long id) {
if (stopped) {
workRequest.cleanup();
return;
}
//封装成调度请求
ScheduledWorkRequest scheduledWorkRequest = new ScheduledWorkRequest(workRequest);
//如果设置了worker线程池则交给线程池异步处理
int size = workers.size();
if (size > 0) {
try {
//分配worker
int workerNum = ((int) (id % size) + size) % size;
ExecutorService worker = workers.get(workerNum);
//调度任务
worker.execute(scheduledWorkRequest);
} catch (RejectedExecutionException e) {
LOG.warn("ExecutorService rejected execution", e);
workRequest.cleanup();
}
} else {
//如果没有worker,则在当前线程中阻塞执行
scheduledWorkRequest.start();
try {
scheduledWorkRequest.join();
} catch (InterruptedException e) {
LOG.warn("Unexpected exception", e);
Thread.currentThread().interrupt();
}
}
}
上面的worker是一个线程池,这也就告诉我们接下来要关注的是ScheduledWorkRequest类中的run方法了:
public void run() {
try {
if (stopped) {
workRequest.cleanup();
return;
}
workRequest.doWork();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
workRequest.cleanup();
}
}
public void doWork() throws InterruptedException {
if (!key.isValid()) {
selectorThread.cleanupSelectionKey(key);
return;
}
if (key.isReadable() || key.isWritable()) {
//核心IO逻辑
cnxn.doIO(key);
if (stopped) {
cnxn.close();
return;
}
if (!key.isValid()) {
selectorThread.cleanupSelectionKey(key);
return;
}
//还是更新过期队列
touchCnxn(cnxn);
}
//已经处理完ID,激活重新select
cnxn.enableSelectable();
//向selector线程提交修改监听事件的任务
//这里呼应上面提到的processInterestOpsUpdateRequests方法
if (!selectorThread.addInterestOpsUpdateRequest(key)) {
cnxn.close();
}
}
void doIO(SelectionKey k) throws InterruptedException {
try {
if (isSocketOpen() == false) {
LOG.warn("trying to do i/o on a null socket for session:0x"
+ Long.toHexString(sessionId));
return;
}
//如果可读
if (k.isReadable()) {
//这里跟客户端逻辑一样,初始incomingBuffer为4字节,读取数据的总长度
int rc = sock.read(incomingBuffer);
if (rc < 0) {
throw new EndOfStreamException(
"Unable to read additional data from client sessionid 0x"
+ Long.toHexString(sessionId)
+ ", likely client has closed socket");
}
if (incomingBuffer.remaining() == 0) {
boolean isPayload;
if (incomingBuffer == lenBuffer) {
incomingBuffer.flip();
//按照实际数据的长度重新初始化incomingBuffer
isPayload = readLength(k);
incomingBuffer.clear();
} else {
isPayload = true;
}
if (isPayload) {
readPayload();
}
else {
return;
}
}
}
//如果可写
if (k.isWritable()) {
handleWrite(k);
if (!initialized && !getReadInterest() && !getWriteInterest()) {
throw new CloseRequestException("responded to info probe");
}
}
//省略各种catch
} catch (CancelledKeyException e) {
} catch (CloseRequestException e) {
} catch (EndOfStreamException e) {
} catch (IOException e) {
}
}
接下来还是按照原来的思路,假设服务启动后第一个请求连接进行,我们关心的是读请求的处理,看下readPayload方法:
private void readPayload() throws IOException, InterruptedException {
//读取数据
if (incomingBuffer.remaining() != 0) {
int rc = sock.read(incomingBuffer);
if (rc < 0) {
throw new EndOfStreamException(
"Unable to read additional data from client sessionid 0x"
+ Long.toHexString(sessionId)
+ ", likely client has closed socket");
}
}
if (incomingBuffer.remaining() == 0) {
//修改服务器状态,对收到数据包的个数+1
packetReceived();
incomingBuffer.flip();
if (!initialized) {
//如果还未初始化,则进行连接请求的处理
readConnectRequest();
} else {
//处理普通的读请求,后面再说
readRequest();
}
lenBuffer.clear();
incomingBuffer = lenBuffer;
}
}
private void readConnectRequest() throws IOException, InterruptedException {
if (!isZKServerRunning()) {
throw new IOException("ZooKeeperServer not running");
}
//处理连接请求
zkServer.processConnectRequest(this, incomingBuffer);
initialized = true;
}
在看处理逻辑之前,我们先来理一下一个连接进来以后要做的事情,处理连接肯定是首先要创建session会话,可以想到如果客户端是第一次连接,那么新建会话,如果是重新连接即传过来了sessionId,那么服务端需要对sessionId进行校验,如果超时则关闭会话,否则需要更新会话时间,下面上代码:
public void processConnectRequest(ServerCnxn cnxn, ByteBuffer incomingBuffer) throws IOException {
//反序列化
BinaryInputArchive bia = BinaryInputArchive.getArchive(new ByteBufferInputStream(incomingBuffer));
ConnectRequest connReq = new ConnectRequest();
connReq.deserialize(bia, "connect");
if (LOG.isDebugEnabled()) {
LOG.debug("Session establishment request from client "
+ cnxn.getRemoteSocketAddress()
+ " client's lastZxid is 0x"
+ Long.toHexString(connReq.getLastZxidSeen()));
}
boolean readOnly = false;
try {
//只读模式
readOnly = bia.readBool("readOnly");
cnxn.isOldClient = false;
} catch (IOException e) {
}
if (!readOnly && this instanceof ReadOnlyZooKeeperServer) {
throw new CloseRequestException("");
}
//如果当前服务器的zxid小于客户端传过来的zxid,也就是说客户端的数据
//比当前服务端更超前,因此需要客户端重新连接其他服务节点,当前服务节点
//的数据是落后于整个ZK集群的
if (connReq.getLastZxidSeen() > zkDb.dataTree.lastProcessedZxid) {
throw new CloseRequestException("");
}
int sessionTimeout = connReq.getTimeOut();
byte passwd[] = connReq.getPasswd();
int minSessionTimeout = getMinSessionTimeout();
//以服务端会话超时时间为准,协商超时时间
if (sessionTimeout < minSessionTimeout) {
sessionTimeout = minSessionTimeout;
}
int maxSessionTimeout = getMaxSessionTimeout();
if (sessionTimeout > maxSessionTimeout) {
sessionTimeout = maxSessionTimeout;
}
//设置超时时间
cnxn.setSessionTimeout(sessionTimeout);
//在session建立好之前拒绝任何数据包
cnxn.disableRecv();
long sessionId = connReq.getSessionId();
//如果没有sessionId,表示第一次建立连接
if (sessionId == 0) {
//新建会话
createSession(cnxn, passwd, sessionTimeout);
} else {
//这里居然重新读了一次sessionId
long clientSessionId = connReq.getSessionId();
//这里可以看出对于更新会话的逻辑是先不关闭当前会话再进行更新
if (serverCnxnFactory != null) {
//如果是重新建立连接,则首先关闭之前的会话
serverCnxnFactory.closeSession(sessionId);
}
if (secureServerCnxnFactory != null) {
secureServerCnxnFactory.closeSession(sessionId);
}
cnxn.setSessionId(sessionId);
//更新会话
reopenSession(cnxn, sessionId, passwd, sessionTimeout);
}
}
这里先看一下更新会话的逻辑:
public void reopenSession(ServerCnxn cnxn, long sessionId, byte[] passwd,int sessionTimeout) throws IOException {
//校验会话密码
if (checkPasswd(sessionId, passwd)) {
revalidateSession(cnxn, sessionId, sessionTimeout);
} else {
//校验失败这里会直接返回给客户端提示信息
finishSessionInit(cnxn, false);
}
}
protected void revalidateSession(ServerCnxn cnxn, long sessionId, int sessionTimeout) throws IOException {
//这里会校验会话是否过期
boolean rc = sessionTracker.touchSession(sessionId, sessionTimeout);
//同样根据会话是否过期返回给客户端提示信息
finishSessionInit(cnxn, rc);
}
再来看下创建会话的逻辑:
long createSession(ServerCnxn cnxn, byte passwd[], int timeout) {
if (passwd == null) {
passwd = new byte[0];
}
//生成会话ID
long sessionId = sessionTracker.createSession(timeout);
//生成会话密码
Random r = new Random(sessionId ^ superSecret);
r.nextBytes(passwd);
ByteBuffer to = ByteBuffer.allocate(4);
to.putInt(timeout);
cnxn.setSessionId(sessionId);
Request si = new Request(cnxn, sessionId, 0, OpCode.createSession, to, null);
//单机模式下这是个空方法,暂时忽略
setLocalSessionFlag(si);
//提交给请求处理链路
submitRequest(si);
return sessionId;
}
public void submitRequest(Request si) {
//省略部分逻辑...
try {
//跟新该连接的会话过期时间
touch(si.cnxn);
//校验请求类型是否合法
boolean validpacket = Request.isValid(si.type);
if (validpacket) {
//这里开始处理,firstProcessor对应的是PrepRequestProcessor
firstProcessor.processRequest(si);
if (si.cnxn != null) {
//记录正在处理的请求个数
incInProcess();
}
} else {
new UnimplementedRequestProcessor().processRequest(si);
}
} catch (MissingSessionException e) {
} catch (RequestProcessorException e) {
}
}
//PrepRequestProcessor的处理逻辑
public void processRequest(Request request) {
submittedRequests.add(request);
}
从最开始的setupRequestProcessors方法可以看出,firstProcessor也是通过start()方法启动的,那么可以想到它的run方法就是处理submittedRequests队列中的请求了,看下代码:
public void run() {
try {
while (true) {
//从请求队列中取出数据
Request request = submittedRequests.take();
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (Request.requestOfDeath == request) {
break;
}
//真正处理请求
pRequest(request);
}
} catch (RequestProcessorException e) {
} catch (Exception e) {
}
}
在pRequest中涉及到zk支持的所有API,这里只看createSession的处理逻辑
protected void pRequest(Request request) throws RequestProcessorException {
request.setHdr(null);
request.setTxn(null);
try {
switch (request.type) {
case OpCode.createSession:
case OpCode.closeSession:
if (!request.isLocalSession()) {
pRequest2Txn(request.type, zks.getNextZxid(), request,
null, true);
}
break;
} catch (KeeperException e) {
} catch (Exception e) {
}
request.zxid = zks.getZxid();
//下一个处理器就是SyncRequestProcessor
nextProcessor.processRequest(request);
}
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException {
//只有写请求才会设置事务头
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid, Time.currentWallTime(), type));
switch (type) {
case OpCode.createSession:
//这里request.request是byte数组,表示会话超时时间
request.request.rewind();
int to = request.request.getInt();
//设置事务体
request.setTxn(new CreateSessionTxn(to));
request.request.rewind();
if (request.isLocalSession()) {
//集群模式才会用,暂时忽略
zks.sessionTracker.addSession(request.sessionId, to);
} else {
//保存会话信息,交给SessionTrackerImpl去管理
zks.sessionTracker.addGlobalSession(request.sessionId, to);
}
zks.setOwner(request.sessionId, request.getOwner());
break;
}
}
再次强调一下只有写请求才会设置事务头,后面的处理器会根据是否有事务头来做一些特殊逻辑。
PrepRequestProcessor组装好事务信息以后会把请求交给下一个处理器,即SyncRequestProcessor进行处理,该处理器是用来记录事务日志到磁盘以及保存快照文件的,由最开始的代码可以看出该类也是调用start()方法启动的,因此跟PrepRequestProcessor一样,processRequest方法只是提交一个任务到队列中,核心逻辑还是在run方法里,看下代码:
public void run() {
try {
int logCount = 0;
//加个随机数是为了避免所有服务节点同时进行数据的dump
int randRoll = r.nextInt(snapCount/2);
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
//如果当前没有等待刷到磁盘的数据则阻塞等待请求
si = queuedRequests.take();
} else {
//否则直接获取一次等待处理的数据
si = queuedRequests.poll();
//如果等待队列中没有数据则直接刷入磁盘,避免太长时间没有落盘
//这里的隐藏意思是如果队列有数据,那么就一次性都取出来批量操作
//如果队列中没有数据,则把缓存中的数据刷入磁盘
if (si == null) {
flush(toFlush);
continue;
}
}
//如果是关闭请求则退出循环
if (si == requestOfDeath) {
break;
}
if (si != null) {
//记录这条事务日志,注意只有写日志才会记录
if (zks.getZKDatabase().append(si)) {
//已记录的事务数量
logCount++;
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2);
//新开始一个事务日志文件,这里会把logStream设置为null,下次就会新创建事务日志文件
zks.getZKDatabase().rollLog();
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
//当事务日志量达到一定的数量,则进行一次快照dump
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch(Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
snapInProcess.start();
}
logCount = 0;
}
} else if (toFlush.isEmpty()) {
//这里是针对大量读请求的优化,不用等待,直接交给下一个处理器
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
continue;
}
//加入到flush缓存
toFlush.add(si);
//结合上面的逻辑看,如果队列中有大量数据,大于1000个 那么就按照1000个刷一次盘
//批量写入磁盘,提高效率
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
} catch (Throwable t) {
handleException(this.getName(), t);
} finally{
running = false;
}
}
//刷磁盘的逻辑可以看出如果是写事务日志只有落盘了才会继续调用后面的处理器
private void flush(LinkedList toFlush) throws IOException, RequestProcessorException {
if (toFlush.isEmpty())
return;
//把事务日志落盘
zks.getZKDatabase().commit();
//调用后面的处理器
while (!toFlush.isEmpty()) {
Request i = toFlush.remove();
if (nextProcessor != null) {
nextProcessor.processRequest(i);
}
}
if (nextProcessor != null && nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
从上面可以看出只有事务日志落盘以后才会交给FinalRequestProcessor进行处理,该处理器作为最后一个处理器,它的职责是修改内存数据结构,即DataTree,同时该处理器并没有调用start()方法启动,就是一个普通方法,看下处理逻辑:
public void processRequest(Request request) {
ProcessTxnResult rc = null;
synchronized (zks.outstandingChanges) {
//操作内存数据结构,如果需要会触发watcher
rc = zks.processTxn(request);
//只有写请求才会设置request.hdr,也只有写请求才会加入outstandingChanges
if (request.getHdr() != null) {
TxnHeader hdr = request.getHdr();
Record txn = request.getTxn();
long zxid = hdr.getZxid();
while (!zks.outstandingChanges.isEmpty()
&& zks.outstandingChanges.peek().zxid <= zxid) {
ChangeRecord cr = zks.outstandingChanges.remove();
if (cr.zxid < zxid) {
LOG.warn("Zxid outstanding " + cr.zxid
+ " is less than current " + zxid);
}
if (zks.outstandingChangesForPath.get(cr.path) == cr) {
zks.outstandingChangesForPath.remove(cr.path);
}
}
}
//如果是集群模式的话需要添加提交协议,本文暂时不需要理会
if (request.isQuorum()) {
zks.getZKDatabase().addCommittedProposal(request);
}
}
if (request.type == OpCode.closeSession && connClosedByClient(request)) {
if (closeSession(zks.serverCnxnFactory, request.sessionId) ||
closeSession(zks.secureServerCnxnFactory, request.sessionId)) {
return;
}
}
if (request.cnxn == null) {
return;
}
ServerCnxn cnxn = request.cnxn;
String lastOp = "NA";
zks.decInProcess();
Code err = Code.OK;
Record rsp = null;
try {
if (request.getHdr() != null && request.getHdr().getType() == OpCode.error) {
if (request.getException() != null) {
throw request.getException();
} else {
throw KeeperException.create(KeeperException.Code
.get(((ErrorTxn) request.getTxn()).getErr()));
}
}
KeeperException ke = request.getException();
if (ke != null && request.type != OpCode.multi) {
throw ke;
}
switch (request.type) {
case OpCode.createSession: {
zks.serverStats().updateLatency(request.createTime);
lastOp = "SESS";
cnxn.updateStatsForResponse(request.cxid, request.zxid, lastOp, request.createTime, Time.currentElapsedTime());
//给客户端响应
zks.finishSessionInit(request.cnxn, true);
//直接返回
return;
}
}
} catch (SessionMovedException e) {
} catch (KeeperException e) {
} catch (Exception e) {
}
//由于创建会话是在上面case条件里面就直接返回给客户端响应了
//因此这里删除了处理其他请求时给客户端返回response的逻辑
}
可以看出FinalRequestProcessor包含修改内存数据结构跟返回响应给客户端两个逻辑。
四、疑问
这里有一个最大疑问是上面源码中出现的outstandingChanges跟outstandingChangesForPath两个数据结构,这两个变量是用来保存即将修改的日志的,也就是在PrepRequestProcessor处理器中如果是写请求则会生成一条changeRecord记录保存在这两个数据结构中(我们上面是以创建会话为例,因此没有出现这两个数据结构),然后在FinalRequestProcessor处理器中成功处理完请求之后从这两个数据机构从中changeRecord删除,逻辑上看并不存在任何问题,但奇怪的是这两个数据结构只在PrepRequestProcessor中插入数据,在FinalRequestProcessor中删除数据,别的地方再也没有出现,表面上看即使没有这两个数据结构也能够正常运行,一直没有想清楚它们存在的意义是什么?
五、总结
首先可以看到第一个处理器PrepRequestProcessor是从请求队列中取出数据进行消费,这里就可以看出服务端是按照请求数据提交的顺序串行处理。zk文档中说可以保证一个客户端先收到watcher事件再读取到新数据,这点就是通过这种串行处理请求实现的。客户端跟服务端建立一个TCP的连接,服务端先处理写请求然后通知客户端触发watcher,接着处理读请求返回新的数据,此时TCP会保证watcher事件先于请求数返回数据到达客户端。