1、个体与集成
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统。
过于集成可能产生的效果,西瓜书上是这么说的:

准确性和多样性是集成学习的关键,准确性是基础,不难想象,几个比随机分类器效果还差的分类器组合在一起效果只会更差;而多样性实际上是为了“互补”,每个分类器可能都学到了数据中的一部分信息,大家互通有无,才能建立起更强的模型,如果大家手里的信息都差不多,那结合在一起并不会右多大的提升。
2、Boosting

可以看到,Boosting完美地展现了另各个基学习器“互补”的思想,因为我们在前一个学习器上错分的样本,在训练下一个学习器的时候得到重点关注,于是下一个学习器将学到关于这部分错分样本的更多信息以弥补前一个学习器的不足。
关于多样性还有另一种解释:

我们现在希望通过调整样本的权重使得下一个学习器和上一个学习器的差异越大越好,我们该怎么做呢。上图告诉我们,我们只需要调整权重,使得在调整后的权重上表现得和随机分类器一样好即可。容易想到,这样做就是放大了的错分样本对应的权重,缩小了正确分类样本对应的权重。
如何调整权重来满足上述条件呢?

其实很简单,就是把错分的样本对应的权重乘一个正比于加权正确率的系数,把正确分类的样本乘一个正比于加权错误率的系数,这样就可以满足在调整后的权重上表现得和随机分类器一样好。

我们通过构造一个“标准化因子”,把上述过程改写成:将错分样本的权重乘以标准化因子,将正确分类样本的权重除以标准化因子,容易看出,只要之前的基学习器正确率大于50%,即错误率小于50%,那么我们所做的事就是在放大错误样本的权重,缩小正确样本的权重。
这就得到了本节开头西瓜书上的论述。根据这个权重调整的方式我们可以得到如下算法;

算法的框架有了,还有两个待解决的问题,一个是权重的初始化问题,另一个是最终的集成学习器要通过何种方式将得到的多样化的基学习器集成在一起。第一个问题是容易解决的,因为一开始我们对数据全无了解,因此只需对样本一视同仁,即赋予它们同样的权重。第二个问题则需要一些思考,简单的让各个基学习器进行投票可以吗?这样恐怕效果不好,对于图中举出的例子来说,在初始权重下表现最好,而我们最终希望的其实就是在初始权重下表现最好,而我们知道和差异很大,所以在初始权重下表现必然不好,因此用投票法组合基学习器并不会带来提升。
那么我们如何组合基学习器呢?

上图展示了一种合理的线性组合各基学习器的系数,这样选取系数可以赋予分类效果好(即加权错误率低)的基学习器更大的权重,从而得到较好的集成学习器。
从而我们得到了AdaBoost算法:

西瓜书上则是从纯数学的角度推导出了AdaBoost算法:






那么AdaBoost发挥了怎样的作用呢?从方差偏差分解的角度来看,Boosting主要关注降低偏差,所以AdaBoost可以取得的效果类似下面左图,也就是将简单的边界组合得到复杂边界,其作用类似于特征转换:
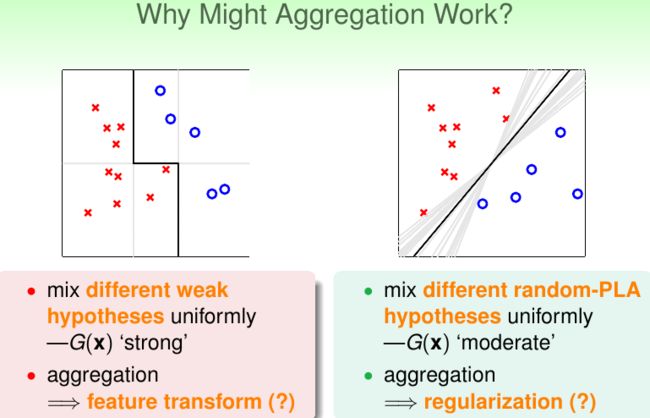
下面我们关注另一类主要关注降低方差的集成方法——Bagging,以及其拓展变体随机森林(Random Forest)。
3、Bagging and Random Forest

以上就是Bagging的动机。那么既然我们想要让各个学习器尽可能“相互独立”,但又要使用有重叠的采样子集,这要怎么做呢?

我们采用的是自助采样法,也就是有放回的采样。相比无放回的采样,我们从直觉上思考一下为什么有放回的采样更好。
无放回采样最大的缺点就是每个学习器能使用的样本太少了,假设有个样本,个基学习器,那么每个学习器只能使用个样本进行学习,这样的效果显然是不好的,首先一个样本只被一个学习器使用到了,这对于小样本集的情况是很浪费的;其次由于喂给每个基学习器的样本数较少,可能导致学习效果不佳,最终得到多个效果很差的基学习器(甚至可能比随机分类器效果还差),这样集成就无法带来性能提升。
那么有放回采样又如何呢?首先我们可以充分利用手头的数据,让一个样本可能在多个学习器的训练数据集种出现,从而得到较为充分的学习。其次,假设观测样本包含了潜在样本的全部信息,那么我们不妨就把这个样本看做“总体”,采用有放回采样,进行k轮抽取,得到的k个训练集之间是相互独立的,这就使得个体学习器尽可能相互独立。
另外,我们还要注意,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集采集中。这是因为:对一个样本,它在某一次含个样本的训练集的采样中,每次被采到的概率是。不被采到的概率为。次采样都没有被采到的概率是。当,。
对于这部分大约36.8%的没有被采样到的数据,我们常常称之为袋外数据(Out Of Bag, OOB)。这些数据可以用来检测模型的泛化能力。

接下来我们看一下随机森林,其实随机森林和Bagging很类似,只是在Bagging的样本扰动的基础上增加了属性扰动:


Bagging和Boosting比较如下:(https://www.cnblogs.com/liuwu265/p/4690486.html)
1)样本选择:
Bagging:训练集是有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
4、结合策略
上面我们重点讨论了如何生成用于集成的各个基学习器或个体学习器。下面我们讨论如何把各个学习器结合在一起。
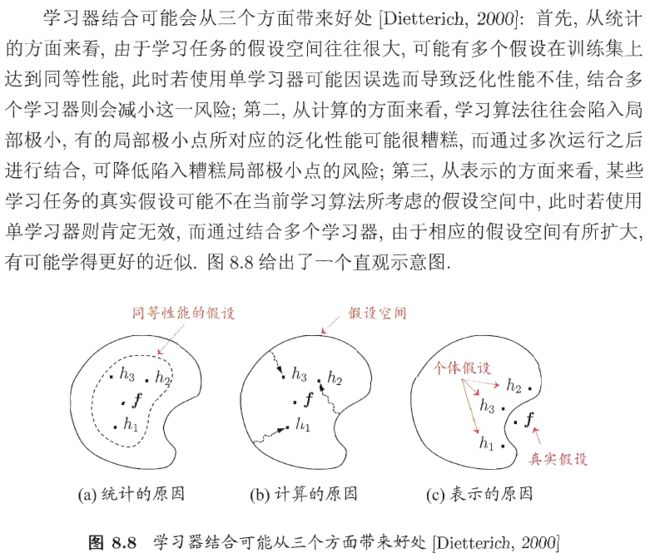
以下是西瓜书上给出的学习器结合可能带来的三方面好处:
接下来西瓜书上介绍了三种常用的结合策略:平均法、投票法和学习法。
平均法最为简单,常用于数值型()输出的任务(比如回归)。常用的方法有简单平均和加权平均。一般而言,在个体学习器性能相差较大时宜使用加权平均,在个体学习器性能相近时宜使用简单平均。
投票法是针对分类任务的结合策略。主要有绝对多数投票法(若某标记票数过半则预测为该标记,否则拒绝预测,适用于可靠性较高的场合)、相对多数投票法(得票最多的标记即为预测结果,若有多个标记获得最高票则随机选取一个)、加权投票法(与加权平均类似)。这里需要注意的点是,虽然分类器估计出的类概率一般都不太准确,但基于类概率进行结合却往往比基于类标记进行结合性能更好。
学习法是使用学习器来结合学习器。Stacking是学习法的典型代表。我们称个体学习器为初级学习器,用于结合的学习器为次级学习器或元学习器。则Stacking先从初始数据集种训练出初级学习器,然后“生成”一个新数据集用于训练次学习器。这个新数据集种,初级学习器的输出被当作样例输入特征,初始样本的标记仍被当作样例标记。Stacking算法流程如下:

5、多样性
(略)