原文:https://ci.apache.org/projects/flink/flink-docs-release-1.3/concepts/programming-model.html
抽象层次
Flink为开发流式应用和批处理应用提供了不同层次的抽象
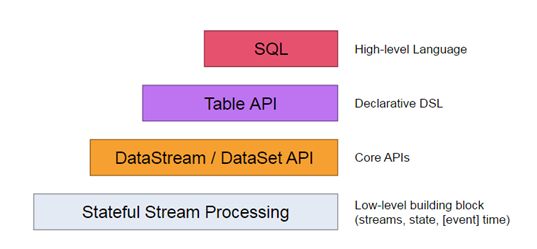
最底层的抽象仅仅提供有状态的流,它通过过程函数(Process Function)被嵌入到DataStream API中。它允许用户自由地处理来自一个或者多个流中的事务,并且使用一致性容错状态。此外,用户还可以注册事务时间和处理时间的回调来程序识别复杂的计算。
实际上,大部分的应用程序不会用到上述描述中的底层抽象,反而会用到Core API如DataStream API(有界、无界流数据)和DataSet(有界数据集)。这些流利的API提供了数据处理的通用模块,如各种形式的转换、连接、聚合、窗口、状态等。这些API处理的数据类型表现为相应的编程语言中的类。
底层的过程函数(Process Function)与DataStream API结合,可以去底层抽象中执行某些特定的操作。DataSet API也为有界的数据集提供了额外的原语,如:loops/ietrations
Table API是一个围绕表并且可能会动态改变表(表示流的时候)的声明式DSL。Table API遵循如下关系模型:表有一个附加的模式(类似关系型数据库中的表)并且这些API提供有可比性的操作,例如select、project、join、group-by、aggregate等。Table API程序指定了哪些逻辑操作必须做,而不是指定操作代码的形式。虽然Table API可以通过各种用户自定义函数来扩展,但是相对于CoreAPI来说,还是缺乏表现力,但是对于用户来说,更加简洁了。此外,Table API会在执行之前通过优化器来做一些优化操作。
由Flink提供的最高层的抽象就是SQL。这个抽象在语义和表现上与Table API类似,但是在语法上与SQL的查询语法类似。SQL抽象可以与Table API进行交互,并且SQL查询可以在Table API定义的表上执行。
程序与数据流
Flink程序最基本的编程模块是streams和transformations,(注意:Flink DataSet API中用到的DataSet本质上也是流,后续会讲到)。从概念上来讲stream就是一个(可能是无尽的)数据记录流,而transformation就是将一个或者多个stream作为输入,并产生一个或者多个stream作为结果的操作。
当执行的时候,Flink程序就会映射成streaming dataflows(流式数据流),这些streaming dataflows(流式数据流)由stream和transformation操作组成。每个dataflow(数据流)以一个或者多个Source(源)开始,并以一个或者多个Sink(槽)为结束。Dataflow类似于有向无环图(DAG),

通常程序中的transformation(转换)和dataflow(数据流)中的操作都是一一对应的,当然,有的时候有可能一个转换有多个转换操作。
Sources和Sinks的文档在streaming connectors和batch connectors的文档中,Transformation的文档在DataStream transformation和DataSet
transformation中。
并行数据流
Flink中的程序本质上都是并行的分布式的。在运行期间,每个stream都有一个或者多个stream的分区,每个操作都有一个或者多个子任务。每个子任务跟其他的子任务都是独立的,运行在不同的线程上,并且有可能运行在不同的机器或者容器中。

Streams可以在两个transport之间以一对一或者重分区的模式进行传输:
一对一:(如上述的Source和map之间的操作)streams保持原有的分区和元素的顺序不变。也就是说map操作的子任务看到的元素的顺序与Source操作产生的元素的顺序是一致的。
重分区:重分区stream(比如map和keyBy/window之间以及keyBy/window和sink之间)改变了原来stream的分区信息。每一个子任务根据选择的信息将数据分发到不同的目标子任务中去。
更多关于控制并发的配置请参考:https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/parallel.html
Windows
聚合类事件(如:counts、sums)在流上的处理与批处理有所不同。例如:在流上对所有的元素进行计数是不可能的,因为流上的数据是源源不断的产生着。因此,流上的聚合(例如:counts、sums)以窗口作为范围,例如计算最近5分钟的数据量,计算最近100个元素的总和。
Windows(窗口)可以是时间驱动的(例如:每30分钟)或者是数据驱动的(例如:每100个元素)。不同类别的窗口的典型差异:例如:tumbling
windows(翻滚窗口)(没有重叠)、sliding windows(滑动窗口)(有重叠)以及session windows(会话窗口)(间断的空白)。
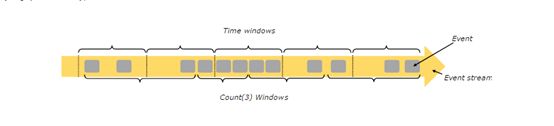
更多Windows的例子可以从这里获取https://flink.apache.org/news/2015/12/04/Introducing-windows.html,更多Windows的细节可以参考这里https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/windows.html
Time
当我们提到流程序中的Time(时间)时,我们先来提一下不同的时间概念:
Event Time(事件时间)是指事件创建时的时间。在事件中往往以时间戳作为描述,例如传感器的连接时间、服务的产生时间。Flink通过timestamp assigners来获取事件时间。
Ingestion Time(摄入时间)是指事件进入Flink数据流源操作时的时间。
Processing Time(处理时间)是指执行每个时间操作时的本地时间。
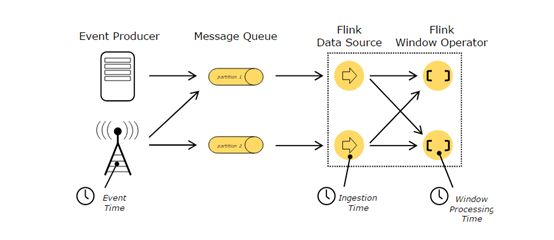
关于如何处理时间的详细信息请参考:https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/event_time.html
Stateful Operations
虽然许多数据流的操作都只是一次查看一个单独的数据流(例如一个事件解析器),一些操作则需要从多个事件中获取信息(例如window操作)。这些操作被叫做stateful(状态性操作)。
状态性操作的状态保存在一个嵌入式的key/value系统中,state(状态)的分区和分布与状态性操作读取的数据流的分区和分布是严格一致的。因此,只能是通过keyBy函数处理之后的有键值的流才能调用到key/value状态,并且仅限于与当前的key有关联的values。对齐流和状态的键,确保所有的状态更新都是本地操作,保证了一致性而没有事务的开销。这个对齐性也使得Flink能够透明地对state进行重分区和调整数据流的分区。
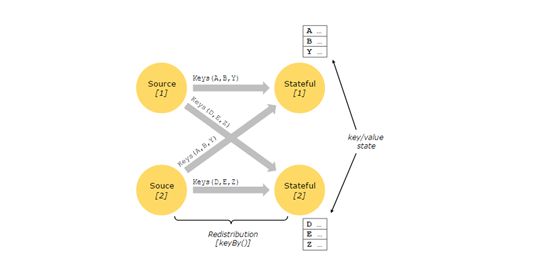
更多信息参考文档:https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/stream/state.html
Checkpoints for Fault Tolerance
Flink通过stream的重试机制和checkpoint机制来实现容错的。Checkpoint与每一个输入流中的特定点及每个运算符中的对应状态相关。一个数据流可以在保持一致性的同时通过恢复检查点操作的状态和重试检查点的事件来从检查点钟恢复。
Batch on Streaming
Flink执行批处理程序是以一种特殊的流程序来实现的,在这种程序中流是有限的(元素个数是有限的)。DateSet在内部被当做流来处理。上述的概念既适用于批处理也适用于流式处理,除了一些细微的差别:
1、批处理的容错机制不使用checkpoint机制,当streams重试时,只能所有的一切重来。这主要是因为数据是有限的。这种机制提高了恢复的成本,但是降低了实现的复杂度,因为避免了checkpoint机制。
2、DataSet中的状态性操作使用的是内存数据结构或者out-of-core数据结构,而不是key/value系统
3、DataSet API引进了一种特殊的synchronized迭代,这种迭代只能在有限的数据流中使用。更多详情,请查看iteration的文档https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/batch/iterations.html