Horovod 容器生存指南
作者: 胡瑛皓 ([email protected]) 如转载请联系作者
Horovod 是Uber的一个开源深度学习工具,采用allreduce方法,为用户提供分布式深度神经网络训练的解决方案。目前支持的深度学习框架包括: keras, pytorch和tensorflow。通过这套框架,用户可以快速的将自己原有的代码切换成分布训练模式,实现水平扩展(scale-out)大幅提升训练速度。撰写本文目的是提供部署的经验,帮助用户更快的从理论进入实战部分。
编排结构
这里采用的技术架构是以docker作为深度训练的容器 ( 其中搭载 tensorflow, horovod 等软件包 ) ,以rancher (v1.*) 作为可视化编排管理工具对容器进行水平扩展(注: 这里不会对rancher, docker private repository, docker等容器技术作过多阐述和说明。用户可以采用其他容器技术或编排软件自行配置),其编排结构如下图所示:

编排的所有操作均在rancher中部署,其中私有repo中保存配置好的horovod镜像, 通过horovod-node服务进行水平扩展(service)。
容器安装
horovod-node容器需容纳tensorflow, horovod等运行环境,本文介绍基于ubuntu+python3的容器安装步骤,需要依次进行:系统包安装, python3包安装, openmpi及horovod安装
1. 操作系统包,wget, curl, vim, telnet, git,python3-pip, python3-dev, openssh-server 等基础包请根据需要自行安装。需要注意的是: horovod中使用 openmpi 作跨节点调用,其实质是采用ssh执行各种应用程序并汇总结果。因此需要安装openssh-server服务,为其设定登录密码,同时暴露22端口,可参考 链接1 链接2。
RUN apt-get update && \
apt-get install -y openssh-server openssh-client
RUN mkdir /var/run/sshd
RUN echo 'root:password' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
# SSH login fix. Otherwise user is kicked off after login
RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
ENV NOTVISIBLE "in users profile"
RUN echo "export VISIBLE=now" >> /etc/profile
EXPOSE 22
另外,由于horovod的python包采用make install的方式安装,需安装以编译开发环境 build-essential, gcc, g++, automake, make等;
2. 安装python3包,安装numpy, tensorflow, keras, pytorch, torchvision及相关依赖包;
3. openmpi/horovod 安装,根据horovod官网上的说明进行下载安装 。注意,openmpi安装后需执行ldconfig命令对LD_LIBRARY_PATH变量进行配置。openmpi安装后,便可直接安装horovod的python包;
RUN wget https://download.open-mpi.org/release/open-mpi/v3.1/openmpi-3.1.2.tar.gz
ENV LD_LIBRARY_PATH "/usr/local/lib"
RUN tar -xzvf openmpi-3.1.2.tar.gz
WORKDIR /root/openmpi-3.1.2/
RUN ./configure --prefix=/usr/local && \
make all install
RUN ldconfig
WORKDIR /root/
4. 容器入口点改造。一般容器启动点为一个单独python/java程序,由于希望horovod-node以长服务形式出现,将其改造为启动ssh服务,并不断sleep等待。设定完毕,就可以为后续提供持续的算力服务。
sleep 5 && service ssh start
while true; do
sleep 5
done
代码调整
我们以horovod官方自带的(tensorflow_mnist.py)为例作为分布式训练的代码。github上的代码可以拿来直接使用,如稍作调整效果更好。
1. 数据集改造,代码中对于每个节点均采用不同的数据集文件(根据hvd.rank()确定id),保证每个数据集可并发执行,不会互相干扰。不过这种设计方式造成,这些文件会反复下载导致系统卡死,而且在国内无法下载到谷歌提供的数据文件。在容器环境下为提高速度,建议将这些数据文件提前下载(数据集地址),解压保存到rancher实例不同服务器下的同一个目录下MNIST-data里,并修改70行:
# mnist = learn.datasets.mnist.read_data_sets('MNIST-data-%d' % hvd.rank())
mnist=learn.datasets.mnist.read_data_sets('MNIST-data')
2. epoch调整,如需要调整训练的epoch数,可调整StopAtStepHook的last_step参数。
tf.train.StopAtStepHook(last_step=1000 // hvd.size()),
服务部署
把构建好的容器,简单封装后部署到rancher,成为长服务方便后续使用。参考步骤如下:
1. 发布容器镜像,tag容器镜像并push到私有repo,发布至 rc01:5000/horovod:latest ;
2. 配置rancher服务,编辑docker-compose.yml文件将容器部署为horovod-grid/horovod-node服务。映射数据集、代码到容器/shared目录,配置privileged: true模式:
version: '2'
services:
horovod-node:
image: rc01:5000/horovod:latest
restart: always
privileged: true
volumes:
- /data/shared:/shared
environment:
- LD_LIBRARY_PATH=/usr/local/lib
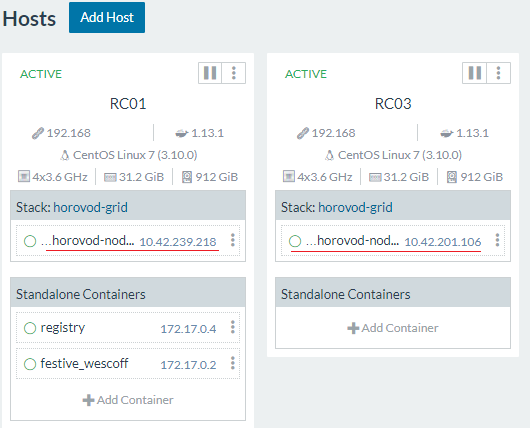
3. 在rancher服务中scale需要执行的容器数量,本例图中部署后得到2个节点的算力(10.42.239.218 和 10.42.201.106),分别位于2台主机上,实际可根据具体需求部署算力:
4. 免密码登录
选择任意一实例作为后续openmpi执行的主节点(例如10.42.239.218), 在该实例上执行,保证对于实例本身以及其他实例可以免密码操作(做法与hadoop安装过程中,免密码登录方式类似)。
# 为本机建立rsa秘钥
ssh-keygen -t rsa
# 设置节点1
ssh [email protected] mkdir -p /root/.ssh
cat /root/.ssh/id_rsa.pub | ssh [email protected] 'cat >> /root/.ssh/authorized_keys'
# 设置节点2
ssh [email protected] mkdir -p /root/.ssh
cat /root/.ssh/id_rsa.pub | ssh [email protected] 'cat >> /root/.ssh/authorized_keys'
命令行启动
远程登录部署好的主实例节点10.42.239.218, 执行以下命令开始训练 (mpirun 参数说明 -np 进程数量, -H 主机列表, --allow-run-as-root 以root方式运行, -x 环境变量, -wd 工作目录)
mpirun -np 2 \
--allow-run-as-root \
-H 10.42.239.218:1,10.42.201.106:1 \
-x LD_LIBRARY_PATH=/usr/local/lib \
-x PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games \
-wd /shared \
/usr/bin/python3.6 -u /shared/tensorflow_mnist.py
好了,到这里分布式训练系统就建设完成了,基于Horovod的应用可生存在rancher中了 。每个容器实例消耗1个CPU的算力,因此可根据实际情况分布到不同主机host中进行计算。
如需要GPU配置,需在容器配置过程中安装CUDA及相应GPU版本,可参考官方版本docker文件。