一.pandas包里内置的绘图函数
matplotlib.style.use('ggplot')#调用风格ggplot
1. plot() :最基本的绘图函数
例子1,Series数据:
ts = pd.Series(np.random.randn(1000),index = pd.date_range('2000-1-1',periods=1000))
ts.plot()
ts=ts.cumsum()
ts.plot()
例子2,DataFrame数据:
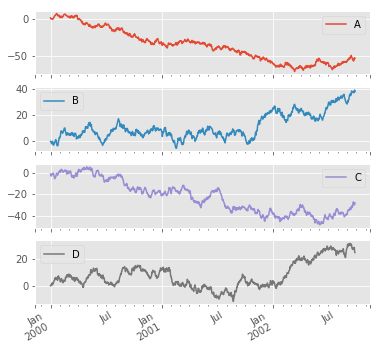
ds = pd.DataFrame(np.random.randn(1000,4),index = ts.index , columns = list('ABCD'))
df = ds.cumsum()
plt.figure();df.plot();
2. plot.bar() # 条形图
有两种写法:
df.plot(kind = 'bar')
或者
df.plot.bar()

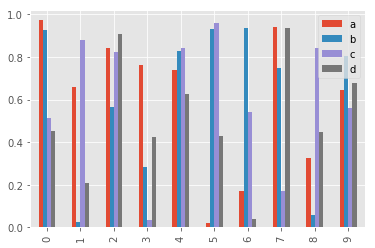
df2 = pd.DataFrame(np.random.rand(10,4),columns=list('abcd'))
df2.plot.bar();
堆积条形图:
df2 = pd.DataFrame(np.random.rand(10,4),columns=list('abcd'))
df2.plot.bar(stacked = True );

水平放置的条形图(horizontal bar plot):
df2.plot.barh()#非堆积
df2.plot.barh(stacked = True );#堆积

3. plot.hist() #(分布)直方图
PS: 注意条形图(bar)与直方图(hist)的区别
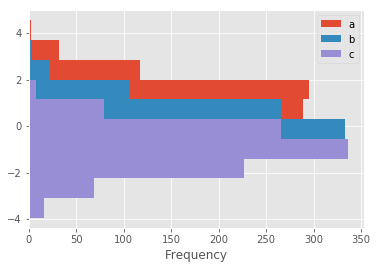
df4 = pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),
'c':np.random.randn(1000)-1},
columns = list('abc'))
plt.figure();
df4.plot.hist(alpha=0.5 )

堆积直方图:
df4.plot.hist(stacked=True ,bins = 20 )

水平放置的堆积直方图:
df4.plot.hist(orientation = 'horizontal')
水平放置,累计直方图:
df4.plot.hist(orientation = 'horizontal',cumulative = True)
DataFrame.hist 可以绘制多个直方图的组合图( 区别于plot.hist):
df.diff().hist(color='k',alpha = 0.5,bins = 50)
#df.diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据。


4. plot.box() 箱线图
箱线图可以使用Series.plot.box() 和DataFrame.plot.box(),或DataFrame.boxplot()来绘制。
df = pd.DataFrame(np.random.rand(10,5),columns=list('abcde'))
df.plot.box()

利用dict输入颜色,指定图表元素的颜色:
colordict = dict(boxes = 'DarkGreen',whiskers = 'DarkOrange',medians = 'DarkBlue',caps ='Gray')
df.plot.box(color = colordict,sym = 'r+')#异常点使用红色的+

水平放置的箱线图,以及调整箱线图的位置:
df.plot.box(vert = False , positions = [1,4,5,6,8])

使用DataFrame.boxplot绘制分组箱线图:
df = pd.DataFrame(np.random.rand(10,2) ,columns = ['col1','col2'])
df['X'] =pd.Series(['A','A','A','A','A','B','B','B','B','B'])
plt.figure();
bp = df.boxplot(by='X')

也可以根据多列进行分组。
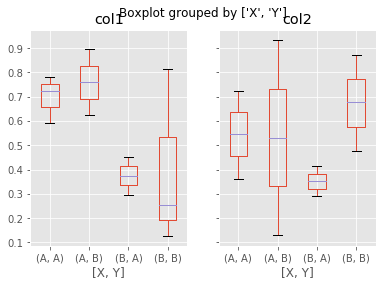
如以下的数据,根据 ['X','Y'] 分组:
col1 col2 col3 X Y
0 0.779948 0.547248 0.010448 A A
1 0.894880 0.934884 0.952019 A B
2 0.590233 0.723640 0.849273 A A
3 0.624342 0.128476 0.663999 A B
4 0.721439 0.362377 0.625264 A A
df = pd.DataFrame(np.random.rand(10,3) ,columns = ['col1','col2','col3'])
df['X'] =pd.Series(['A','A','A','A','A','B','B','B','B','B'])
df['Y'] =pd.Series(['A','B','A','B','A','B','A','B','A','B'])
plt.figure();
bp = df.boxplot(column = ['col1','col2'],by=['X','Y'])
以下两种写法相等:
df_box = pd.DataFrame(np.random.randn(50,2))
df_box['g'] = np.random.choice(['A','B'],size = 50)
df_box.loc[df_box['g'] == 'B',1] +=3
bp = df_box.boxplot(by='g') #DataFrame.boxplot(by=)
df_box.groupby('g').boxplot() #Groupby.boxplot()
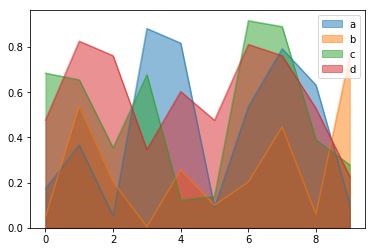
5. plot.area(): 面积图
df = pd.DataFrame(np.random.rand(10,4),columns = list('abcd'))
df.plot.area()#堆积面积图
df.plot.area(stacked = False) #不堆积

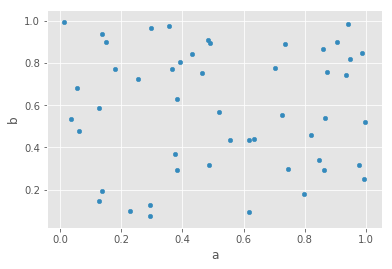
6. plot.scatter(): 散点图
df = pd.DataFrame(np.random.rand(50,4),columns = list('abcd'))
df.plot.scatter(x='a',y='b')
由于这个df数据没有分类列,如果要绘制分类散点图,代码逻辑比较特殊,
- 要先绘制一个普通散点图(举例s1);
- 然后再绘制第二次,在绘制第二次的时候把散点图s1赋值参数ax 。
(另外以下两句代码要一次运行,如分开运行只会返回
s1 = df.plot.scatter(x='a',y='b',color='DarkBlue',label='Group 1')
df.plot.scatter(x='c',y='d',color='Red',label='Group 2',ax=s1)

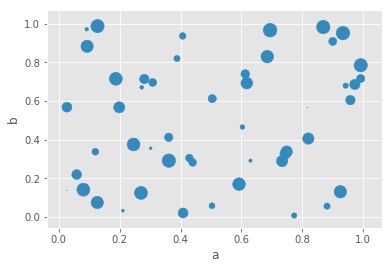
df.plot.scatter(x='a',y='b',c='c',s=50)#参数s指定散点大小为50
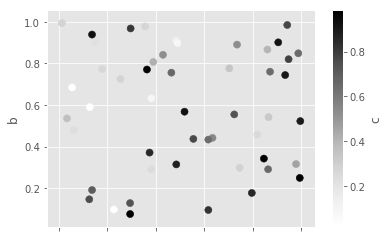
给参数s赋值可以绘制气泡图:
df.plot.scatter(x='a',y='b',s=df['c']*200)
7. plot.hexbin(): 六边形图(本质上类似热点图)
df = pd.DataFrame(np.random.randn(1000,2),columns = list('ab'))
df['b'] = df['b'] + np.arange(1000)
df.plot.hexbin(x='a',y='b',gridsize=25)
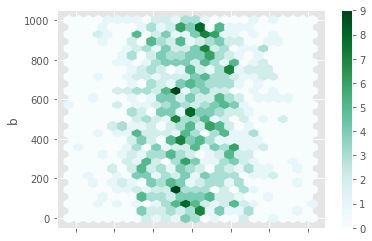
gridsize参数值越大,六边形块越小。

默认条件下,每一个六边形会统计(x,y)周围的count值。可以通过赋值给C和reduce_C_function,指定替代的聚合函数、值。
举例,下图展示的是每一个(a,b)坐标,对应Z值的最大值。
df['b'] = df['b'] = df['b']+np.arange(1000)
df['z'] = np.random.uniform(0,3,1000)
df.plot.hexbin(x='a',y='b',C='z',reduce_C_function=np.max,gridsize =25)

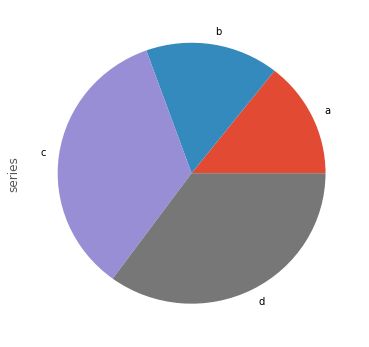
8. plot.pie(): 饼图
series = pd.Series(3* np.random.rand(4),index = list('abcd'),name='series')
series.plot.pie(figsize=(6,6))
de = pd.DataFrame(3*np.random.rand(4,2),index = list('abcd'),columns=['x','y'])
#de有x,y两列数据(4×2)
de.plot.pie(subplots = True, figsize =(8,4))
de = pd.DataFrame(3*np.random.rand(4,3),index = list('abcd'),columns=['x','y','z'])
#de有x,y,z三列数据(4×3),会绘制出三个饼
de.plot.pie(subplots = True, figsize =(12,4))


series.plot.pie(labels=['AA','BB','CC','DD'],colors=['r','g','b','c'],autopct='%.2f',fontsize=20,figsize=(6,6))

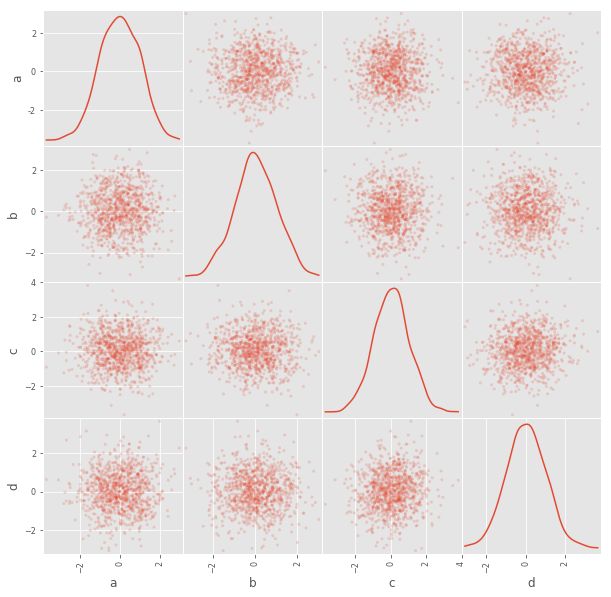
9. scatter_matrix(): 散点矩阵图
from pandas.tools.plotting import scatter_matrix
df = pd.DataFrame(np.random.randn(1000,4),columns=list('abcd'))
scatter_matrix(df,alpha=0.2,figsize=(10,10),diagonal='kde')
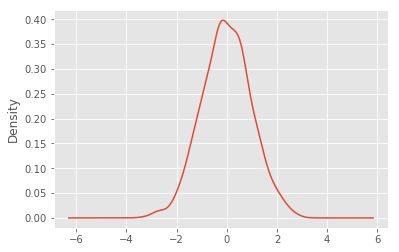
10. kde(): 密度图(Kernel Density Estimate plot)
又名:核密度估计图
ser = pd.Series(np.random.randn(1000))
ser.plot.kde()
二.修改绘图格式(Plot Formatting)
1.图例
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list('ABCD'))
df=df.cumsum()
df.plot(legend=False) --关闭图例:legend=False
df.plot() -- 默认显示图例
2.坐标轴
ts = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods = 1000))
ts = np.exp(ts.cumsum())
ts.plot(logy=True)#Y轴进行log转化
另外还有,logx和loglog参数;
3.绘制次要Y轴:secondary_y=True
df = pd.DataFrame(np.random.randn(1000,4),columns=list('ABCD'))
df['A'] = df['A'].cumsum()
df['B'] = df['B'].cumsum()
df.A.plot()
df.B.plot(secondary_y=True,style='g')

df['C'] = df['C'].cumsum()
df['D'] = df['D'].cumsum()
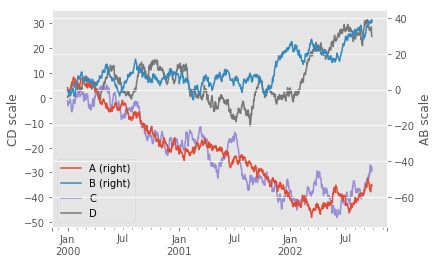
plt.figure()
ax = df.plot(secondary_y = ['A','B'])
ax.set_ylabel('CD scale')#设置左边y轴名称
ax.right_ax.set_ylabel('AB scale')#设置右边次要y轴名称
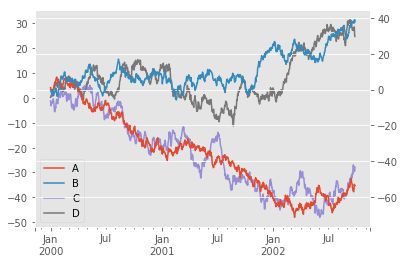
plt.figure()
df.plot(secondary_y=['A', 'B'], mark_right=False)#mark_right=False
4. Suppressing Tick Resolution Adjustment
对于X轴的时间标签,pandas多数情况下不能判断X轴的出现频率,所以可以使用x-axis tick labelling(X轴加标签的方法)来全部显示X轴内容
Using the x_compat parameter, you can suppress this behavior:
设定参数就是x_compat=True


如果需要处理多个图像:
If you have more than one plot that needs to be suppressed, the use method in pandas.plot_params can be used
in a with statement:
with pd.plot_params.use('x_compat', True):
df.A.plot(color='r')
df.B.plot(color='g')
df.C.plot(color='b')

5.多图绘制(相当于在ggplot2中的分面画图)
df.plot(subplots=True, figsize=(10, 10));