MongoDB是一个比较年轻的数据库系统,但在近些年发展的很迅速。MongoDB是NoSQL类型的数据库。
NoSQL
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。 --百度百科
数据会以key-value变量的形式储存,以文件型数据库的模式达到更好的性能。在之前的SQL数据库中,数据储存到表里,以主键或者外键的形式进行检索。在文件型数据库中,数据不再储存在表里,而是以标准文件形式比如JSON或XML。下面以一个简单的博客数据库为例,SQL形式的数据库可能需要两张表来储存博文和回复如下图:
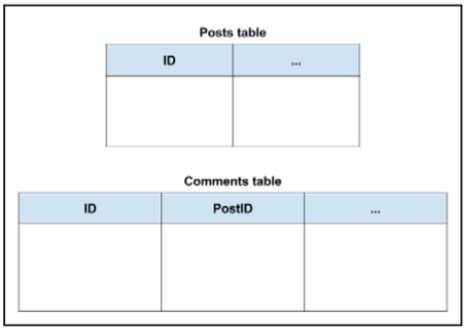
文件型数据库则是以JSON形式,如下图:
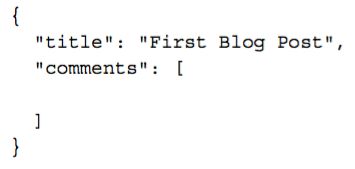
以上就是关系型数据库和文件型 数据库的最基本区别,一个用表,一个用文件。另外文件型数据库在修改表(数据)结构的时候要比关系型数据库要简单。
MongoDB
MongoDB有以下特点:
BSON格式
类似于JSON形式的数据存储格式Binary-JSON,又很快的读取速率。
- 类似JSON,BSON文件是一个简单地key-value object形式的数据。一个文件包含多个element(元素),每一个element有一个name和对应的value。这些文件支持所有JSON支持的数据类型。
- 使用_id字段作为主键,由应用驱动或者MongoDB server自动生成 ObjectId,类型优先级为:
- 4byte的Unix epoch时间
- 3byte的设备ID
- 2byte的进程ID
- 3byte的计数器,以一个随机数为起点
所以一个Object会长成这个样子:
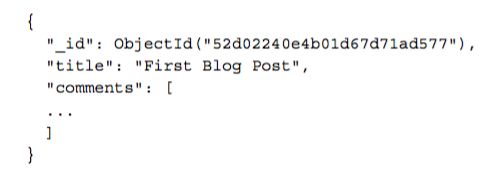
MongoDB ad hoc检索
对key-value储存形式的扩展,MongoDB有其类似于SQL的动态检索语言,下面对比SQL语言检索所有title包含mongo的post:
SQL:
SELECT * FROM Posts WHRER Title LIKE ‘%mongo%’;
MongoDB:
db.posts.find({ title:/mongo/});
- MongoDB indexing,唯一的数据结构,给某字段设置index来提高检索效率,例子:
检索所有评论次数超过10次的博文:
"_id": ObjectId("52d02240e4b01d67d71ad577"),
"title": "First Blog Post",
"comments": [
],
"commentsCount": 12
}
MongoDB检索:
db.posts.find({ commentCount:{$ gt:10} });
为了检索以上数据,MongoDB需要查询所有的posts数据,然后检查commentCount是否大于10。但如果commonCount字段的index定义了,效率就会大大提高。下图所示index是怎样工作的:
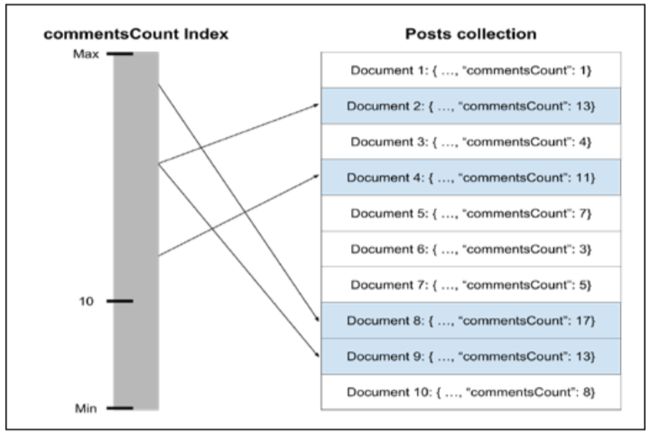
MongoDB replica set
数据的备份,用到再说,先略了
MongoDB sharding
解决业务增长后的性能问题,略
多数据库
一个MongoDB服务可以存储多个DB,除非特意设定,MongoDB默认打开test数据库,想要切换到其他数据库使用:
>use mean
切换到名字为mean的数据库,需要注意的是,在你不需要先创建数据库再去使用,因为MongoDB的数据库是在插入文件前懒创建的。这是MongoDB的动态数据策略。另一个打开数据库的方法是:
$mongo mean
如果想要列出所有的数据库:
>show dbs
MongoDB collections
一个MongoDB collection是一些列的db文件,相当于SQL数据库的一些列表。一个collection是在第一个文件插入时被创建的。想要操作collection,要使用collection方法。现在创建一个posts collection:
`>db.posts.insert({"title:"First Post","user":"bob"})
上述,会自动建一个posts collection。下面检索一下posts:
db.posts.find()
上述,会看到结果。
想要看到所有可见的collection:
>show collections
删除collection:
db.posts.drop()
MongoDB CRUD 操作
Create,Read,Update,Delete。
新建文件:insert()
新建object:update() 和 save()
新建文件
使用insert()创建文件:
> db.posts.insert({"title":"Second Post", "user": "alice"})
使用update()创建文件
> db.posts.update({
"user": "alice"
}, {
"title": "Second Post",
"user": "alice"
}, {
upsert: true
})
上述,DB首先会去查找作者是alice的post,然后更新;如果没有找到并且upsert是true的话,新建一个文件。
使用save()创建文件
``` > db.posts.save({"title":"Second Post", "user": "alice"}) ``
上述,传入文件可以有_id也可以没有_id。
insert和save的区别当主键"_id"不存在时,都是添加一个新的文档,但主健"_id"存在时,就有些不同了:
insert:当主键"_id"在集合中存在时,不做任何处理。
save:当主键"_id"在集合中存在时,进行更新。
save需要遍历整个集合,效率没有insert快。
读取文件
读取文件使用find()方法。
查找条件:
> db.posts.find({ "user": "alice" })
> db.posts.find({ "user": { $in: ["alice", "bob"] } })
AND/OR:
and不用关键字,罗列上就行
> db.posts.find({ "user": "alice", "commentsCount": { $gt: 10 } })
> db.posts.find( { $or: [{ "user": "alice" }, { "user": "bob" }] })
更新文件
update():
> db.posts.update({
"user": "alice"
}, { $set: {
"title": "Second Post"
}
}, {
multi: true
})
上述,update()有三个参数,第一个参数是指更新哪些数据(筛选),第二个参数时更新内容,第三个是强制更新所有符合条件的文件。
save()
> db.posts.save({
"_id": ObjectId("50691737d386d8fadbd6b01d"),
"title": "Second Post",
"user": "alice"
});
上述,需要传一个_id,来告诉DB你要跟新的文件。** 如果save()没有找到object,会新建一个 **
删除
使用remove()来删除文件
删除所有:
> db.posts.remove()
删除多个:
> db.posts.remove({ "user": "alice" })
删除单个:
> db.posts.remove({ "user": "alice" }, true)
上述,将会删除第一个符合条件的文件,留下其他的。