我PC上是win10和Ubuntu18.0.4双系统
hadoop 2.8.5
jdk 1.8
1.安装配置jdk
从orcle官网上下载jdk,解压复制到/usr/local/下
/usr/local/jdk1.8中的文件

修改配置文件 ~/.bashrc或 /etc/profile,添加环境变量
添加以下内容:
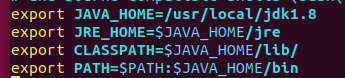
报找不到路径的错误,就看看JAVE_HOME,这个一定是jdk的绝对路径。
配置完成过后,source /etc/profile,可以使修改立即生效,不用重启。
命令java -version查看是否修改成功

2.安装配置hadoop
(1)
去Apache官网下载hadoop 2.8.5

下载tar文件,解压后复制到/usr/local/下,改名为hadoop,目录中文件

添加环境变量,
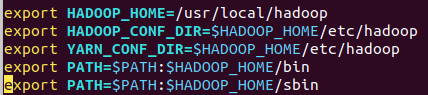
注意:sbin目录下有运行hadoop守护进程的脚本,因此如果计划在本地机器上运行守护进程的话,需要将该目录包含进命令行路径中。
HADOOP_HOME一定是hadoop的绝对路径,
HADOOP_CONF_DIR指向/usr/local/hadoop/etc/hadoop
其他暂时不明,好像不写也没关系。
进入/usr/local/hadoop/etc/hadoop
sudo vim hadoop-env.sh 添加jdk路径和HADOOP_CON_DIR
输入 hadoop version来判断Hadoop是否工作

如果报错Could not find or load main class org.apache.hadoop.util.VersionInfo
试试在配置文件中添加
export HADOOP_CLASSPATH=
各种奇奇怪怪的报错大多和路径有关。
(2)
修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh
EXPORT JAVA_HOME=jdk的路径
Hadoop有以下三种运行模式:
1.独立(本地)模式:无需运行任何守护进程,所有程序都在同一个JVM上执行。在独立模式下测试和调试MapReduce程序很方便,因此该模式在开发阶段较合适。
2.伪分布模式: Hadoop守护进程运行在本地机器上,模拟一个小规模的集群。
3.全分布模式 :Hadoop守护进程运行在一个集群上。
不同模式的关键配置属性,等日后完善。
独立模式下,全为默认属性,不运行守护进程,不需要更多的操作配置
伪分布模式
在/usr/local/hadoop/etc/hadoop下有几个*-site.xml的配置文件,可以把etc/hadoop目录复制到另一个位置,这样安装文件和配置文件隔离开,需要将HADOOP_CONF_DIR指向该目录

core-site.xml中添加
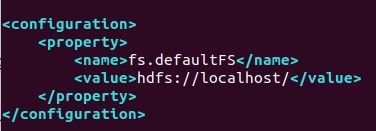
hdfs-site.xml中添加
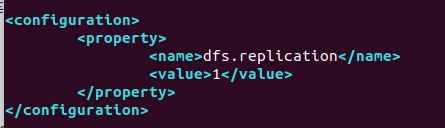
yarn-site.xml

(3)
配置ssh无密码登陆
安装 ssh,之前请确保apt已更新
$ sudo apt-get install ssh
基于空口令生成一个新SSH密钥,以实现无密码登陆
$ ssh-keygen -t rsa -P ' ' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否连接
$ ssh localhost
如果成功则不需要输入密码
(4)
在首次使用hadoop前,必须格式化文件系统。
先修改用户的权限 chown -R 用户名 /usr/local/hadoop
hdfs namenode -format
启动HDFS、YARN和MapReduce守护进程
start-dfs.sh

start-yarn.sh

mr-jobhistory-daemon.sh start historyserver
本地计算机将启动以下守护进程:一个namenode、一个辅助namenode、一个datanode(HDFS)、一个资源管理器、一个节点管理器(YARN)和一个历史服务器(MapReduce)
Hadoop安装目录下logs目录中日志文件可以检查守护进程是否成功启动
Web界面:http://localhost:50070/ 查看namenode
http://localhost:8088/ 查看资源管理器

http://localhost:19888/ 查看历史服务器
还可以通过Java的jps命令,

创建一个主目录
$ hadoop fs -mkdir -p /user/tce
3.Hadoop自带wordcount测试
进入/usr/local/hadoop/bin,创建目录input
寻找一组英文网页,这里我选择github的主页https://github.com/
查看源代码,拷贝到input目录下的github.html
在编写text1.txt:hello excuse me fine thank you,text2.txt:hello how do you do thank you
把input目录下文件添加到hadoop输入
cd /usr/local/hadoop/bin
hadoop dfs -put input in
确认一下
hadoop dfs -ls ./in/*

运行wordcount
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount in output

hadoop-mapreduce-examples-2.8.5.jar这个jar包在/usr/local/hadoop/share/hadoop/mapreduce/

登陆 http://localhost:50070/ 查看namenode

键入 hadoop dfs -cat ./output/* 查看输出结果

参考资料:
《Hadoop权威指南》大数据的存储与分析 第四版
http://www.cnblogs.com/aijianiula/p/3850002.html
https://blog.csdn.net/t555222/article/details/77882747