调研问卷的良好数据处理、清洗规范有利于后续分析。以腾讯问卷的调研结果数据为例。
- 表头定义、单选定义、多响应集合并、十分制转百分制、NPS定义
- Q1编码
- 数据清洗
- 表头/新变量定义
- 加权配比
- 数据分析-百分比、绝对量
原始数据长什么样?
第一行为问卷题目。单选题占一列,多选题的每个选项占一列。每一行为一个填写用户。

第一步:定义
1. 定义表头
手工定义:SPSS-变量视图-标签
代码定义:
VARIABLE LABELS Q1 'Q1.说到团购餐饮平台(不包括外卖)时,您第一反应想到的是哪个?'.
VARIABLE LABELS Q2_1 '美团'.
VARIABLE LABELS Q2_2 '口碑'.
VARIABLE LABELS Q2_3 '百度糯米'.
VARIABLE LABELS Q2_4 '拉手网'.
VARIABLE LABELS Q2_5 '大众点评'.
VARIABLE LABELS Q2_98 '以上都没听说过'.
单选题定义为一个变量,多选题的每一个选项定义为一个变量。
在数值上单选题的数值即为选中的值。多选题每一个变量被选中则标记为1。
2. 单选定义
手工定义:spss-变量视图-值
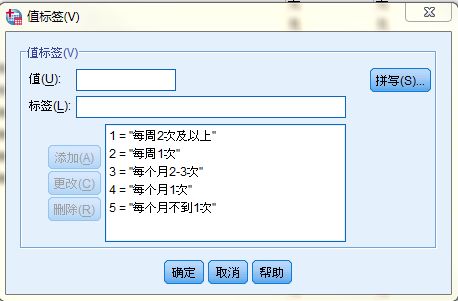
代码定义:
VALUE LABELS Q4 to Q6
1 '每周2次及以上'
2 '每周1次'
3 '每个月2-3次'
4 '每个月1次'
5 '每个月不到1次'
3. 多响应集(多选项)合并
手工定义:spss-数据-定义多重响应集

代码定义:
MRSETS
/MDGROUP NAME=$Q2 LABEL='Q2.您听说过以下哪些团购餐饮平台(不包括外卖)?'
VARIABLES=Q2_1 to Q2_98
VALUE=1
/DISPLAY NAME=[$Q2].
4. 十分制转百分制(并标记新变量)
手工定义:spss-转换-计算变量
代码定义:
COMPUTE SQ11=Q11/10*100.
COMPUTE SQ17=Q17/10*100.
VARIABLE LABELS SQ11 'SQ11.上次的优惠在多大程度上影响了您当时对餐厅的选择?'.
VARIABLE LABELS SQ17 'SQ17.总体满意度-美团'.
EXECUTE.
5. NPS定义
什么是NPS?
净推荐(Net Promoter)是FredReichheld(2003)针对企业良性收益与真实增长所提出的用户忠诚度概念。请用户回答“您在多大程度上愿意向您的朋友(亲人、同事……)推荐XX公司/产品?”(0-10分,10分表示非常愿意,0分表示非常不愿意),根据用户的推荐意愿,将用户分为三类:推荐者(9-10)、被动者(7-8)、贬损者(1-6),推荐者与贬损者是对企业实际的产品口碑有影响的用户,这两部分用户在用户总数中所占百分比之差,即净推荐值(Net Promoter Score,NPS)
计算公式:净推荐值(NPS)=(推荐者数/总样本数)×100%-(贬损者数/总样本数)×100%
手工定义:spss-转换-重新编码为其他变量


代码定义:
RECODE SQ18(90 thru 100=1)(70 thru 80=2)(10 thru 60=3) INTO NPS_Q18.
VARIABLE LABELS NPS_Q18 'NPS_Q18.美团'.
VALUE LABELS NPS_Q18
1 推荐
2 被动
3 贬损
.
EXECUTE .
第二步:开放题编码
以“说到团购餐饮平台(不包括外卖)时,您第一反应想到的是哪个?”为例,需要对开放题的回答归类重新编码。
开放题的重新编码可以编码为单选题。也可以编码为多个变量,然后定义为多重响应集(多选题)。
开放题的编码不适合完全用手工操作,更适合用代码定义。
手工操作:spss-转换-计算变量-如果

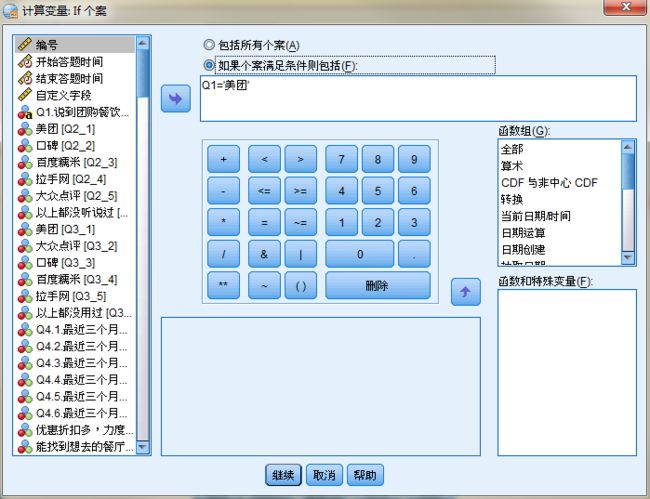
生成新变量后再设置变量标签及变量值。spss-变量视图-值/标签。
代码定义:
if(Q1=',美团')Q1sm=1.
if(Q1=',美团,大众。')Q1sm=1.
RECODE Q1sm(1 thru 98=copy)(ELSE=99) INTO Q1sm.
exe.
VARIABLE LABELS Q1sm 'Q1sm.说到团购餐饮平台(不包括外卖)时,您第一反应想到的是哪个?'.
VALUE LABELS Q1sm
1 美团
2 大众点评
3 口碑
4 百度糯米
5 拉手网
98 其他
99 无提及
.
第三步:数据清洗
数据清洗的目的是清除乱答题的记录。例如:年龄小于14岁,学历为博士、以及通过一些地雷题来剔除。
1. 计算年龄,以及对年龄等变量重新分段
为了分析历史数据方便,问卷在设置时填写的是出生年份,而非当前的绝对年龄。一般情况下出生年份题在前面的步骤中已经被编码。

手工定义:spss-转换-计算变量 + spss-转换-重新编码为其他变量
代码定义(注:代码示例与案例问卷关联,不同问卷使用这段代码需要修改):
*以下是将代码转换成出生年份.
COMPUTE year=2007-Z2.
EXE.
VARIABLE LABELS year '[year]出生年份'.
*计算原理为当今年份减出生年得当今年龄.
COMPUTE age= 2016-year.
EXE.
VARIABLE LABELS age '[age]实际年龄'.
*==============================自定义新变量【不同年代人群】==================================.
RECODE year
(1960 thru 1969=1)
(1970 thru 1979=2)
(1980 thru 1989=3)
(1990 thru 1999=4)
(2000 thru 2009=5)
(else=6)
INTO Generation.
exe.
VARIABLE LABELS Generation '[Generation]不同年代人群'.
value labels Generation
1 60后
2 70后
3 80后
4 90后
5 00后
6 其他
.
*==========================年龄7段========================================.
if (Age<14) Age1=1.
if (Age>=14 & Age <=17) Age1=2.
if (Age>=18 & Age <=24) Age1=3.
if (Age>=25 & Age <=30) Age1=4.
if (Age>=31 & Age <=35) Age1=5.
if (Age>=36 & Age <=40) Age1=6.
if (Age>40) Age1=7.
EXE.
VARIABLE LABELS Age1 '[AGE1]年龄7分段'.
value labels Age1
1 '<14岁'
2 '14-17岁'
3 '18-24岁'
4 '25-30岁'
5 '31-35岁'
6 '36-40岁'
7 '>40岁'
2. 数据清洗
这步的目的是清洗掉每个题目的无效回答
手工定义:spss-转换-重新编码为相同变量
代码定义:
RECODE Z1 (1 thru 98=copy)(ELSE=0) INTO Z1.
RECODE Q2_1(1 thru 98=copy)(ELSE=0) INTO Q2_1.
EXECUTE .
3. 无效回答过滤
手工定义:spss-数据-选择个案-如果条件满足。(注意:条件为过滤的规则,而spss不支持删除选定个案,所以在规则前需要加一个否的逻辑,输出可以选择 过滤掉未选定的个案。或者类似下面示例代码的逻辑,单独计算一个指示是否要过滤的变量)
代码定义(PAB1变量为各种被删除的场景):
*14岁以下:学历为高中以上的删除.
IF (age<14 & Z3>2) PAB1=2.
*14岁以下:职业公务员/企管/普通职员/专业人员/个体/退休.
IF (age<14 & (
Z4=2|
Z4=3|
Z4=4|
Z4=5|
Z4=8|
Z4=11)) PAB1=3.
*18岁以下:学历为本科以上的删除.
IF (age<18 & Z3>4) PAB1=4.
VARIABLE LABELS PAB1 '数据清洗'.
value labels PAB1
2 14岁以下:学历为高中以上的删除
3 '14岁以下:职业公务员/企管/普通职员/专业人员/个体/退休'
4 18岁以下:学历为本科以上的删除
5 18岁以下:学历“硕士及以上”的删除
6 '18岁以下:职业公务员/企管/普通职员/专业人员/退休'
7 '21岁以下:职业是公务员/企管/专业人员/退休'
8 '45岁以下:职业“退休”的删除'
9 系统跳转问题(第1题和性别漏答题的)
99 剩余数据量
.
use all.
* 输出各条件下过滤的数量.
CTABLES
/VLABELS VARIABLES=PAB1 DISPLAY=DEFAULT
/TABLE PAB1 [C][COUNT F40.0]
/CATEGORIES VARIABLES=PAB1 ORDER=A KEY=VALUE EMPTY=INCLUDE TOTAL=YES POSITION=AFTER.
FILTER OFF.
USE ALL.
SELECT IF(PAB1 = 99).
EXECUTE .
第四步:新变量定义
最典型场景是把用户分为白领、学生、蓝领等人群。
手工定义:spss-转换-计算变量 + spss-转换-重新编码为相同变量 + spss-数据-定义多重响应集
代码定义:
*【白领】
收入:>3k
年龄:23-45岁
职业:公务员/企管/普通职员/专业人员
学历:大学专科及以上.
if(age>=23 & age<=45 &
z3>=3 &
Z4>=2 & Z4<=5&
Z5>=6 & Z5<=10
)Groups_1=1.
exe.
*【学生】:职业为“在校学生”.
if(Z4=1)Groups_2=1.
*【打工人群】:职业为普通工人,商业服务业职工.
if(Z4=6 or Z4=7)Groups_3=1.
*【蓝领】:职业为普通工人,商业服务业职工,个体经营者/承包商,农林牧渔劳动者.
if(Z4>=6 & Z4<=8)Groups_4=1.
if(Z4=10) Groups_4=1.
*【高龄】:年龄45岁以上.
if(age>=45)Groups_5=1.
*【其他】白领、学生,打工,蓝领,高龄外剩余的.
RECODE Groups_1(1 thru 98=copy)(ELSE=0) INTO Groups_1.
RECODE Groups_2(1 thru 98=copy)(ELSE=0) INTO Groups_2.
RECODE Groups_3(1 thru 98=copy)(ELSE=0) INTO Groups_3.
RECODE Groups_4(1 thru 98=copy)(ELSE=0) INTO Groups_4.
RECODE Groups_5(1 thru 98=copy)(ELSE=0) INTO Groups_5.
exe.
if(sum(Groups_1,Groups_2,Groups_3,Groups_4,Groups_5)=0)Groups_98=1.
exe.
VARIABLE LABELS Groups_1 '白领'.
VARIABLE LABELS Groups_2 '学生'.
VARIABLE LABELS Groups_3 '打工人群'.
VARIABLE LABELS Groups_4 '蓝领'.
VARIABLE LABELS Groups_5 '高龄'.
VARIABLE LABELS Groups_98 '其他'.
MRSETS
/MDGROUP NAME=$Groups LABEL='[Groups]' VARIABLES=
Groups_1 Groups_2 Groups_3 Groups_4 Groups_5 Groups_98
VALUE=1
/DISPLAY NAME=[$Groups].
第四步:配比
一般从所有互联网用户中调研需要配比cnnic(性别X年龄)。从全量业务用户中调研需要配比用户的业务属性占比。
计算方法:以cnnic年龄性别为例,用cnnic除以调研问卷的在相应区段的比例即为该部分用户应赋予的权重。

手工定义:spss-转换-计算变量 + spss-数据-加权个案
代码定义:
if(age<=13) Age_cnnic=1 .
if(age>=14 & age<=17)Age_cnnic=2 .
if(age>=18 & age<=21)Age_cnnic=3 .
if(age>=22 & age<=24)Age_cnnic=4 .
if(age>=25 & age<=30)Age_cnnic=5 .
if(age>=31 & age<=35)Age_cnnic=6 .
if(age>=36 & age<=40)Age_cnnic=7 .
if(age>=41 & age<=45)Age_cnnic=8 .
if(age>=46 & age<=50)Age_cnnic=9 .
if(age>=51) Age_cnnic=10.
exe.
VARIABLE LABELS Age_cnnic '[Age_cnnic]年龄段'.
Value Labels Age_cnnic
1 '<14'
2 '14-17'
3 '18-21'
4 '22-24'
5 '25-30'
6 '31-35'
7 '36-40'
8 '41-45'
9 '46-50'
10 '>50'
.
* 配比前数据结果.
WEIGHT OFF.
CTABLES
/VLABELS VARIABLES=Z1 Age_cnnic DISPLAY=LABEL
/TABLE Z1[C]>Age_cnnic[C][COUNT F40.0, LAYERPCT.COUNT PCT40.1]
/CATEGORIES VARIABLES=Z1 Age_cnnic ORDER=A KEY=VALUE EMPTY=INCLUDE.
*配比赋值.
if(Z1=1 & Age_cnnic=1)peibi=0.72210024143214.
if(Z1=1 & Age_cnnic=2)peibi=0.319971111015272.
if(Z1=1 & Age_cnnic=3)peibi=0.445860796162467.
if(Z1=1 & Age_cnnic=4)peibi=0.638609308849791.
if(Z1=1 & Age_cnnic=5)peibi=1.11051520669474.
if(Z1=1 & Age_cnnic=6)peibi=1.20352398264839.
if(Z1=1 & Age_cnnic=7)peibi=1.50872153403607.
if(Z1=1 & Age_cnnic=8)peibi=1.08547505687955.
if(Z1=1 & Age_cnnic=9)peibi=1.4809847471284.
if(Z1=1 & Age_cnnic=10)peibi=1.36264514070199.
if(Z1=2 & Age_cnnic=1)peibi=0.685224971352111.
if(Z1=2 & Age_cnnic=2)peibi=0.67403833264497.
if(Z1=2 & Age_cnnic=3)peibi=1.01779552870297.
if(Z1=2 & Age_cnnic=4)peibi=1.14746735217159.
if(Z1=2 & Age_cnnic=5)peibi=2.19873336140591.
if(Z1=2 & Age_cnnic=6)peibi=2.08108509839059.
if(Z1=2 & Age_cnnic=7)peibi=3.04741609742113.
if(Z1=2 & Age_cnnic=8)peibi=2.96663577114532.
if(Z1=2 & Age_cnnic=9)peibi=4.06661113349994.
if(Z1=2 & Age_cnnic=10)peibi=3.63947197758407.
exe.
VARIABLE LABELS peibi '【配比】cnnic'.
*样本配比加权.
WEIGHT BY peibi.
exe.
*配比后结果对比.
CTABLES
/VLABELS VARIABLES=Z1 Age_cnnic DISPLAY=LABEL
/TABLE Z1[C]>Age_cnnic[C][COUNT F40.0, LAYERPCT.COUNT PCT40.1]
/CATEGORIES VARIABLES=Z1 Age_cnnic ORDER=A KEY=VALUE EMPTY=INCLUDE.
第五步:数据分析(交叉表统计)
数据分析的方法多种多样,此处演示最常用的交叉统计。
手工定义:spss-分析-表-设定表
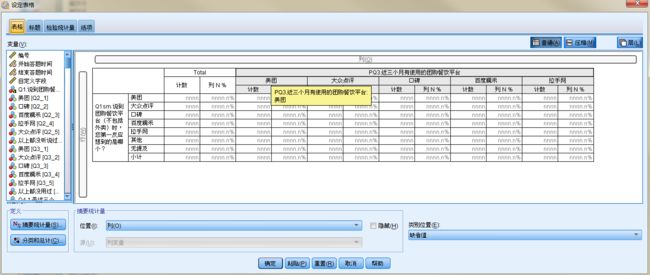
注意:对行的类别变量需要定义好为分类类型(名义/序号,不能为度量)。
代码定义:
* Custom Tables.
CTABLES
/FORMAT EMPTY='-' MISSING='.' /SMISSING VARIABLE
/VLABELS VARIABLES=Q1sm
Total
$PQ3
$C1.1
$C1.2
$C1.3
$C1.4
$C1.5
Z1
AGE1
Z3
Z4
Z5
Z6
Z7
City4
PW3
$Q12
Q13
PQ15
PQ19
PQ23
PQ27
Q16
Q20
Q24
Q28
DISPLAY=DEFAULT
/TABLE Q1sm [C][COLPCT.COUNT PCT40.1]
BY
Total[C]+
$PQ3[C]+
$C1.1[C]+
$C1.2[C]+
$C1.3[C]+
$C1.4[C]+
$C1.5[C]+
Z1[C]+
AGE1[C]+
Z3[C]+
Z4[C]+
Z5[C]+
Z6[C]+
Z7[C]+
City4[C]+
PW3[C]+
$Q12[C]+
Q13[C]+
PQ15[C]+
PQ19[C]+
PQ23[C]+
PQ27[C]+
Q16[C]+
Q20[C]+
Q24[C]+
Q28[C]
/CATEGORIES VARIABLES=Q1sm ORDER=A KEY=VALUE EMPTY=INCLUDE TOTAL=YES POSITION=AFTER.
手机扫码或点击此处访问我的个站
 我的个站.png
我的个站.png
本文章欢迎转载,转载请注明出处和作者。