在Athelas(Athelas 通过深度学习进行血液诊断),我们使用卷积神经网络(CNN)不仅仅是分类!在这篇文章中,我们将看到如何在图像实例分割中使用CNN,效果很好。
自从Alex Krizhevsky,Geoff Hinton和Ilya Sutskever在2012年赢得ImageNet以来,卷积神经网络(CNNs)已经成为图像分类的黄金标准。事实上,从那时起,CNN已经改进到现在他们在ImageNet挑战中胜过人类的程度!

虽然这些结果令人印象深刻,但图像分类远比真人类视觉理解的复杂性和多样性简单得多。

在分类中,通常有一个图像,其中一个对象作为焦点,任务是说该图像是什么(见上文)。但是,当我们观察周围的世界时,我们会执行更复杂的任务。
我们看到复杂的景点有多个重叠的物体和不同的背景,我们不仅要对这些不同的物体进行分类,还要确定它们之间的界限,差异和关系!

CNN可以帮助我们完成这些复杂的任务吗?也就是说,给定一个更复杂的图像,我们可以使用CNN来识别图像中的不同对象及其边界吗?正如Ross Girshick和他的同龄人在过去几年所表明的那样,答案是肯定的。
这篇文章的目标
通过这篇文章,我们将介绍在对象检测和分割中使用的一些主要技术背后的直觉,并了解它们是如何从一个实现发展到下一个实现的。特别是,我们将介绍R-CNN(地区CNN),这是CNN对此问题的原始应用,以及其后代Fast R-CNN和Faster R-CNN。最后,我们将介绍最近由Facebook Research发布的一篇文章Mask R-CNN,它扩展了这种对象检测技术以提供像素级分割。以下是本文中引用的论文:
R-CNN:https://arxiv.org/abs/1311.2524
Fast R-CNN:https://arxiv.org/abs/1504.08083
Faster R-CNN:https://arxiv.org/abs/1506.01497
Mask R-CNN:https://arxiv.org/abs/1703.06870
2014年:R-CNN - CNN在物体检测中的早期应用

受多伦多大学Hinton实验室研究的启发,由Jitendra Malik教授领导的加州大学伯克利分校的一个小团队问自己,今天看来是一个不可避免的问题:
在多大程度上[Krizhevsky等。al的结果]推广到物体检测?
对象检测的任务是在图像中查找不同的对象并对其进行分类(如上图所示)。由Ross Girshick(我们将再次看到的名字),Jeff Donahue和Trevor Darrel组成的团队发现,通过测试PASCAL VOC Challenge,这是一种类似于ImageNet的流行物体检测挑战,Krizhevsky的结果可以解决这个问题。他们写,
本文首次表明,与基于简单HOG类功能的系统相比,CNN可以在PASCAL VOC上实现更高的物体检测性能。
现在让我们花一点时间来了解他们的架构,CNNs区域(R-CNN)是如何工作的。
了解R-CNN
R-CNN的目标是接收图像,并正确识别图像中主要对象(通过边界框)的位置。
输入:图像
输出:图像中每个对象的边界框+标签。
但是我们如何找出这些边界框的位置?R-CNN做了我们可能直观地做的事情 - 在图像中提出 一堆框,看看它们中的任何一个是否实际上对应于一个对象。

R-CNN使用称为选择性搜索的过程创建这些边界框或区域提议,您可以在此处阅读。在较高的层次上,选择性搜索(如上图所示)通过不同大小的窗口查看图像,并且对于每个尺寸,尝试通过纹理,颜色或强度将相邻像素组合在一起以识别对象。
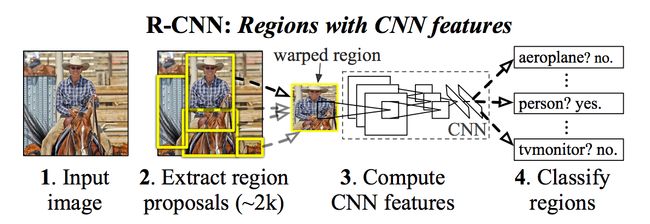
一旦提出建议,R-CNN将该区域变为标准的方形大小,并将其传递给AlexNet的修改版本(ImageNet 2012的获奖提交,启发了R-CNN),如上所示。
在CNN的最后一层,R-CNN增加了一个支持向量机(SVM),它简单地分类这是否是一个对象,如果是的话,是什么对象。这是上图中的第4步。
改进边界框
现在,在盒子里找到了这个物体,我们可以收紧盒子以适应物体的真实尺寸吗?我们可以,这是R-CNN的最后一步。R-CNN对区域提议运行简单的线性回归,以生成更紧密的边界框坐标以获得最终结果。以下是此回归模型的输入和输出:
输入:与对象对应的图像的子区域。
输出:子区域中对象的新边界框坐标。
总而言之,R-CNN只是以下步骤:
1.为边界框生成一组提议。
2.通过预先训练的AlexNet运行边界框中的图像,最后运行SVM,以查看框中图像的对象。
3.通过线性回归模型运行该框,一旦对象被分类,就为框输出更紧密的坐标。
2015年:快速R-CNN - 加速并简化R-CNN

R-CNN效果很好,但由于一些简单的原因,它确实很慢:
它需要CNN(AlexNet)的正向传递,用于每个单个图像的每个区域建议(每个图像大约2000个前向传递!)。
它必须分别训练三个不同的模型 - 用于生成图像特征的CNN,用于预测类的分类器,以及用于收紧边界框的回归模型。这使得管道极难训练。
2015年,R-CNN的第一作者Ross Girshick解决了这两个问题,导致了我们短暂历史中的第二个算法 - 快速R-CNN。现在让我们回顾一下它的主要见解。
Fast R-CNN洞察力1:RoI(感兴趣区域)池
对于CNN的前向传递,Girshick意识到对于每个图像,图像的许多建议区域总是重叠,导致我们一次又一次地运行相同的CNN计算(~2000次!)。他的洞察力很简单 - 为什么不在每张图像上运行CNN一次,然后找到一种方法来分享〜2000个提案中的计算?
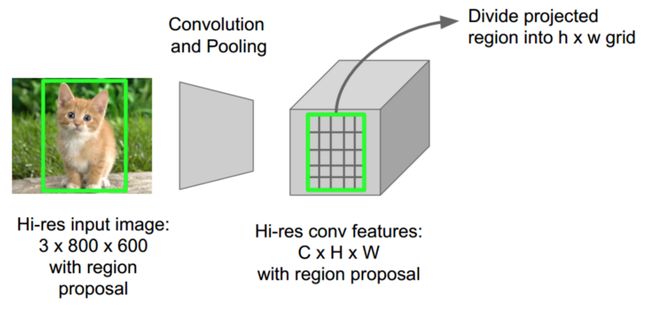
这正是Fast R-CNN使用称为RoIPool(感兴趣区域池)的技术所做的事情。在其核心,RoIPool分享CNN的前向传递,以在其子区域中形成图像。在上图中,请注意如何通过从CNN的要素图中选择相应的区域来获取每个区域的CNN要素。然后,汇集每个区域中的要素(通常使用最大池)。所以我们所需要的只是原始图像的一次传递而不是~2000!
快速R-CNN洞察力2:将所有模型组合到一个网络中
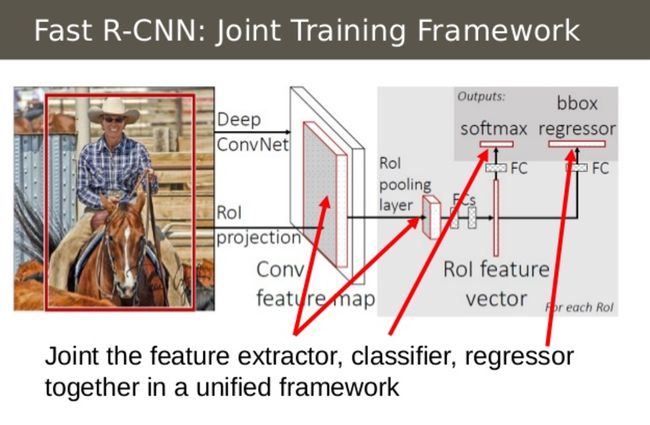
Fast R-CNN的第二个见解是在单个模型中联合训练CNN,分类器和边界框回归器。之前我们有不同的模型来提取图像特征(CNN),分类(SVM)和收紧边界框(回归量),而快速R-CNN则使用单个网络来计算所有三个。
您可以在上图中看到这是如何完成的。快速R-CNN用在CNN顶部的softmax层替换SVM分类器以输出分类。它还添加了一个与softmax图层平行的线性回归图层,以输出边界框坐标。这样,所需的所有输出都来自一个网络!以下是此整体模型的输入和输出:
输入:带有区域提案的图像。
输出:每个区域的对象分类以及更严格的边界框。
2016年:更快的R-CNN - 加速地区提案
即使有了所有这些进步,快速R-CNN过程仍然存在一个瓶颈 - 区域提议者。正如我们所看到的,检测对象位置的第一步是生成一堆潜在的边界框或感兴趣的区域进行测试。在Fast R-CNN中,这些提议是使用选择性搜索创建的,这是一个相当缓慢的过程,被发现是整个过程的瓶颈。
在2015年中期,由Shaoqing Ren,Kaiming He,Ross Girshick和Jian Sun组成的微软研究团队找到了一种方法,通过他们(创造性地)命名为快速R-CNN的架构,使该区域提案步骤几乎免费。
更快的R-CNN的见解是区域建议取决于已经通过CNN的前向传递(分类的第一步)计算的图像的特征。那么为什么不为区域提案重用那些相同的CNN结果而不是运行单独的选择性搜索算法呢?
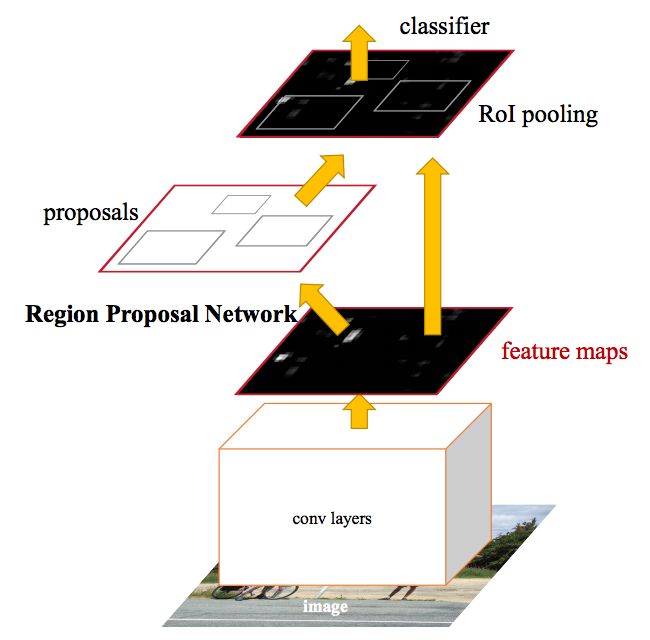
实际上,这正是R-CNN团队更快取得的成就。在上图中,您可以看到单个CNN如何用于执行区域提议和分类。这样,只有一个CNN需要接受培训,我们几乎可以免费获得地区建议!作者写道:
我们的观察结果是,基于区域的探测器(如Fast R-CNN)使用的卷积特征图也可用于生成区域提议[从而实现几乎无成本的区域提议]。
以下是其模型的输入和输出:
输入:图像(注意不需要区域提议)。
输出:图像中对象的分类和边界框坐标。
如何生成区域
让我们花点时间看看R-CNN如何通过CNN功能更快地生成这些区域提案。Faster R-CNN在CNN的功能之上增加了一个完全卷积网络,创建了所谓的区域提案网络。
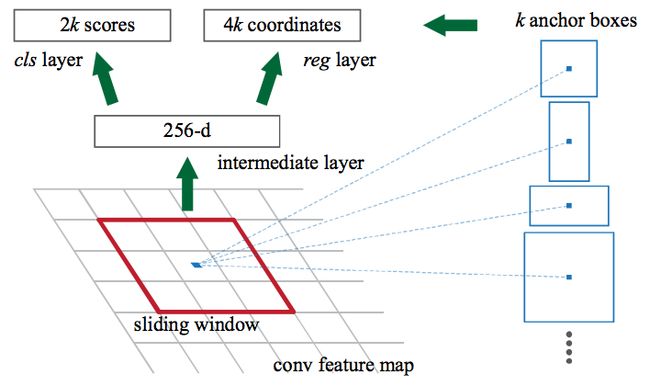
区域提议网络通过在CNN特征映射和每个窗口上传递滑动窗口来工作,输出k个潜在的边界框以及每个框预期有多好的分数。这些k盒代表什么?

直觉上,我们知道图像中的对象应该适合某些常见的宽高比和大小。例如,我们知道我们想要一些类似于人类形状的矩形盒子。同样,我们知道我们不会看到很多非常薄的盒子。以这种方式,我们创建k这样的常见宽高比,我们称之为锚盒。对于每个这样的锚箱,我们输出一个边界框并在图像中的每个位置得分。
考虑到这些锚框,我们来看看这个区域提案网络的输入和输出:
输入:CNN功能图。
输出:每个锚点的边界框。表示该边界框中图像成为对象的可能性的分数。
然后,我们将可能是对象的每个这样的边界框传递到Fast R-CNN,以生成分类和收紧的边界框。
2017:Mask R-CNN - 扩展更快的R-CNN以实现像素级分割

到目前为止,我们已经看到我们如何能够以许多有趣的方式使用CNN功能来有效地定位带有边界框的图像中的不同对象。
我们是否可以扩展这些技术以进一步找到每个对象的精确像素而不仅仅是边界框?这个问题被称为图像分割,是Kaiming He和包括Girshick在内的一组研究人员在Facebook AI上使用一种名为Mask R-CNN的架构进行探索的。

就像Fast R-CNN和Faster R-CNN一样,Mask R-CNN的潜在直觉也是直截了当的。鉴于Faster R-CNN在物体检测方面的效果非常好,我们是否可以扩展它以进行像素级分割?
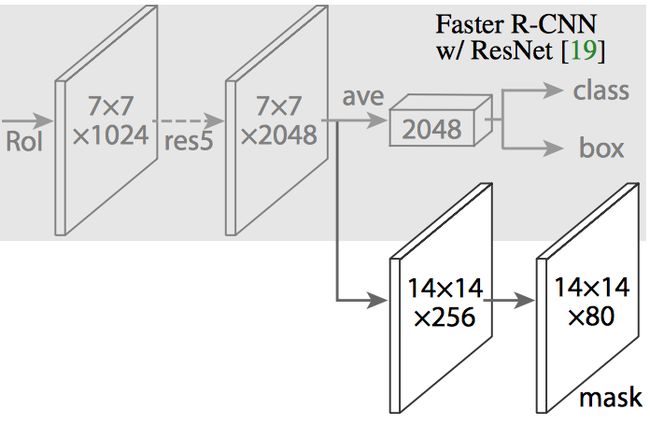
Mask R-CNN通过向更快的R-CNN添加分支来完成此操作,该分支输出二进制掩码,该Mask 表示给定像素是否是对象的一部分。与以前一样,分支(上图中的白色)只是基于CNN的特征映射之上的完全卷积网络。以下是其输入和输出:
输入:CNN功能图。
输出:矩阵在像素属于对象的所有位置上为1,在其他位置为0(这称为二进制掩码)。
但Mask R-CNN的作者不得不进行一次小调整,以使这条管道按预期工作。
RoiAlign - 重新调整RoIPool更准确
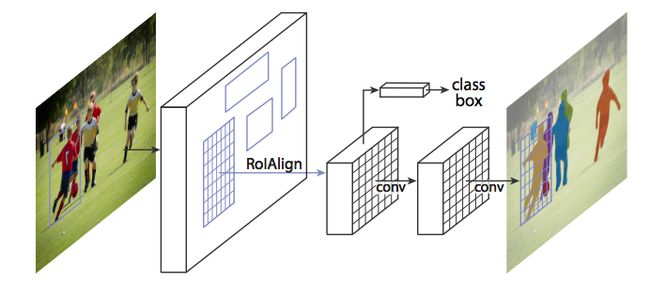
当在原始的快速R-CNN架构上运行而没有修改时,Mask R-CNN作者意识到由RoIPool选择的特征图的区域与原始图像的区域略微不对准。由于图像分割需要像素级特异性,与边界框不同,这自然会导致不准确。
作者能够通过巧妙地调整RoIPool来解决这个问题,使用一种称为RoIAlign的方法进行更精确的对齐。
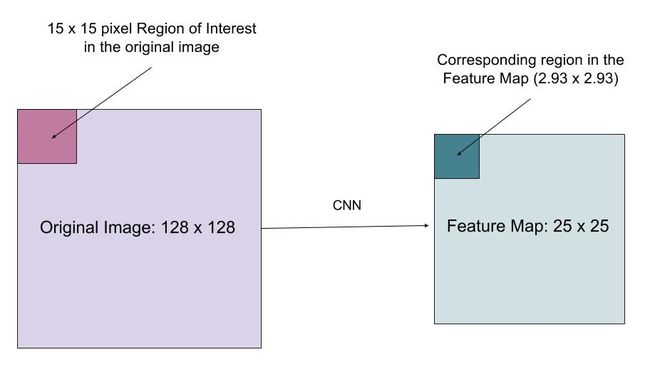
想象一下,我们有一个大小为128x128的图像和一个大小为25x25的特征图。让我们想象一下,我们想要的特征区域对应于原始图像中左上角的15x15像素(见上文)。我们如何从要素图中选择这些像素?
我们知道原始图像中的每个像素对应于特征图中的~25 / 128像素。要从原始图像中选择15个像素,我们只选择15 * 25 / 128~ = 2.93像素。
在RoIPool中,我们将它向下舍入并选择2个像素,导致轻微的错位。但是,在RoIAlign中,我们避免了这种舍入。相反,我们使用双线性插值来准确了解像素2.93处的内容。这在很大程度上是允许我们避免RoIPool引起的错位的原因。
生成这些掩模后,Mask R-CNN将它们与Faster R-CNN中的分类和边界框组合在一起,生成如此精确的分割:
期待
在短短3年时间里,我们已经看到研究界如何从Krizhevsky等进步。al的原始结果是R-CNN,最后一直到Mask R-CNN这样强大的结果。孤立地看,像面具R-CNN这样的结果看起来像天才的难以置信的飞跃,是无法接近的。然而,通过这篇文章,我希望你已经看到这些进步如何通过多年的努力和合作实现直观,渐进的改进。R-CNN,Fast R-CNN,Faster R-CNN以及最后的Mask R-CNN提出的每个想法都不一定是量子跳跃,但它们的总和产品已经产生了非常显着的结果,使我们更接近人类水平了解视力。
让我特别兴奋的是,R-CNN和Mask R-CNN之间的时间只有三年!通过持续的资金,关注和支持,未来计算机视觉能够进一步提升?