
2018年QCon全球软件开发大会在上海举行。QCon是由InfoQ主办的全球顶级技术盛会,其内容源于实践并面向社区,举办至今已有逾万名高级技术人员参加。
本次QCon大会,负责小红书社区大前端、后端、数据、算法及基础架构的小红书 社区技术负责人姚旭发表演讲,面向5年以上工作经验的技术团队负责人、架构师、工程总监、高级开发人员分享技术创新和最佳实践。
近期,小红书等正在全国范围内广泛招募开发及算法技术工程师。我们欢迎全球互联网技术精英加入到小红书的团队中,用技术力量改变世界(详细招聘信息及联系方式见文末)。
以下是演讲精彩内容回顾。
从硅谷到中关村到底有什么差别:以Data Driven+Ownership组建高效团队
1. 效率差距
在加入小红书之前,我在国内外的互联网公司都有所经历。在国内,第一份工作在百度做搜索和推荐。4年之后加入了知乎的初创团队。在知乎上正轨之后我去了美国生活了几年,一段是在Facebook,一段是在Airbnb。这四家公司分别对应着中国互联网巨头的成长期和初创型公司的初生期,以及美国的互联网巨头成长期,和美国的初创公司的初生期。
今天就想分享我在这过去的十几年间看到过、经历过的不同公司在“效率”上不同做法,以及一些自己的总结。
回过头来,我们想讨论的是“从硅谷到中关村到底有多远?”。大家在十年前觉得硅谷,或者说是湾区,是技术型公司的圣殿。那里有着领先商业机会,令我们羡慕的核心技术,以及前瞻性的视野,可以从0创造出拥有非凡价值的功能。
但是,今时今日中美互联网公司,这些差别都变得非常的小。我们仍处在一个巨大的社会转型期,中国在尝试新技术,以及敢于投资尝试新技术的愿望、动力是非常强的,甚至产生了非常大的产业泡沫。前瞻视野上来说,因为我们有大的社会转型和商业机会的存在,在互联网领域从过去的Copy to China,已经演变到互相研究和借鉴。
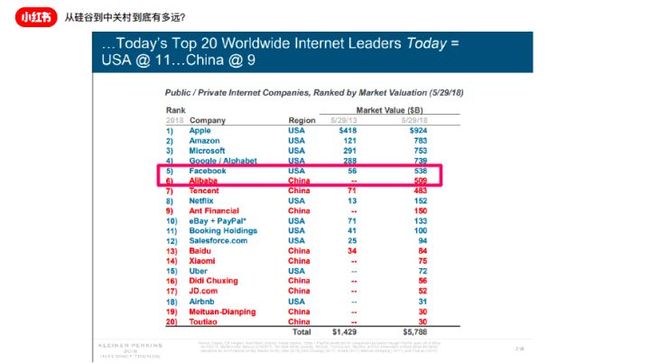
2018年初Mary Meeker的年度互联网报告里面,Top 20市值/估值的互联网公司中国占了一半,虽然位置都在后一半,但处在成长期的公司中国公司明显占比更高。我们说了这么多,中美互联网看起来好像的确差距没有多大差别,但从实际角度中美公司还是在一些领域内差距明显的。框框里面有两家公司,Facebook和阿里巴巴。我们以这两个公司为例,他们两个的市值曾经非常接近,都在5000亿美元左右。但是另外一个更有趣的数据:叫做平均每个员工创造的收入Revenue Per Employee。这个数字上Facebook大概是阿里巴巴的3倍。如果对比更多的中国互联网公司来看,这有可能是10倍、几十倍的差距。这个数据代表了什么呢?一个公司的效率。

站在今天,假如要说中美互联网企业还有什么差距巨大之处,我觉得最明显的就是团队效率。美国或者说硅谷的互联网公司在团队效率上是遥遥领先的,这里面有几个是现实的驱动力:第一点,美国每年的行业新增的人员供给非常有限,提高人效是必经之路。第二点,互联网是一个充分竞争的行业,任何一家公司都不敢完全依赖于有海量的员工加入作为一段时间内最主要的驱动力,所以效率就成了各家公司在非常早期就开始投资的事情。
从现实的情况看,就是Facebook在上市的时候,大概有不到1000个工程师,市值在1000亿美元左右。Instagram被Facebook 10亿美元收购的时候,全公司大概只有十几个人。What’sAPP也是类似的情况。
接下来我们也来对比一下为什么有这样的差别,以及我们从硅谷互联网公司能学到哪些真正可以落地的,实践的一些东西。包括在小红书的一些实践当中看到的效果和遇到的问题。
2. 互联网时代的软件工程
我们今天对于效率的讨论,都是在互联网时代这个大背景下如何能够最大化团队的效率,最大化团队的产出。但我们先把时间轴往前拉一拉。中文互联网元年大概是在2000年左右,我们现阶段的所有互联网企业都是脱胎于那个软件时代,这部分倒是不分中美,所有人都是这样。
我们来看看软件时代和互联网时代有什么区别呢?我们看到软件时代 release 周期大概是半年到一年,也就是说我每年发一张光盘。以微软为例,如果我要发一个新版的WINDOWS的话,起码要以年级别来做。最后的三个月是不能加入新功能的。原因是什么?软件公司无法承受新功能带来的不可控因素。因为如果要修复软件BUG的话,这个修复的成本特别高。在互联网普及之前,是需要再寄一张打补丁的光盘给用户,一个Patch可能要几十万,几百万美金的开销。而这BUG的修复控制权在却在用户手里。用户要安装你的Patch才能把你的BUG修复掉,如果用户被气的抓狂了,在修复Bug之前做的就是用脚投票完全离开。用户就这样流失了,没有任何机会修复。一个公司可能因为一个不成功的发布就要关门。它就像今天的硬件公司一样,它因为周期长,接触用户的成本无比高,所以不可能快速迭代。
软件工程背后的逻辑就八个字:质量第一,按期交付。
我们来讲讲其中的巨无霸:微软。从2000年开始,其实影响中国互联网公司最大的其实就是微软。我们早期的互联网公司,比如BAT,里面有大量的人才都来自黄埔军校微软。
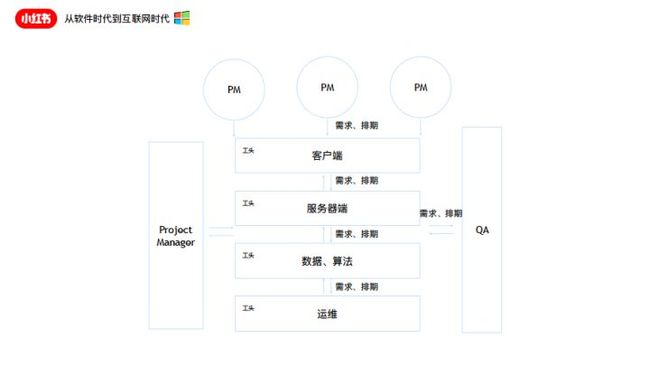
在中国互联网企业里边,大家沿用了微软的开发流程。PM中心制,以交付文档作为各个阶段的结果产出。在整个流程里面出现最多的词叫做“文档”:需求文档,测试文档,部署文档。第二个是“交付”。在一个流水线上,你把一个事情完成了,交给下一个人接着做。这是在软件时代,这个对于整个软件的开发流程,无论从问题的分解,到流程的各个环节的检查,以及对于质量的保证,这是验证出来的软件时代的好的流程。
但到了互联网时代这样软件工程有什么问题?第一点,你会发现,所有原始设计的功能点的周期不再是月级别,是周级,甚至可能都是天级别的。那么,以传统软件工程的流程来看,从产品设计开始到最后落地实现生效起码是周级的,甚至月级的。在互联网时代,这样的release周期和迭代速度是没有竞争力的。
第二点,我们照着这个流程来说,还会出现一种情况,就是叫做职能化区隔。基本上我们的团队构成都是以职能来切分,我是PM,我是工程师,我是测试工程师,等等不同的职能。
如果换到一个复杂的互联网场景里面,我们就会出现,有PM的需求和排期,会分别细化到客户端团队,到服务器后端,到数据算法,到基础架构。所有层层TEAM之间都是以这样一个隔离的需求文档作为最主要的信息传递和问题分解。这就是传统软件时代我们常见的情况:team越来越大,时间却越来越少。流程能带来安全,流程能带来质量保证,但流程不能带来效率。
通过这种职能的划分,带来的更大问题是,没有人能够看得清全局和最终结果。各个TEAM之间大家都说我已经在这个文档上面签过字了,我在这个上面没有事故责任,踢皮球和甩锅。如果所有人都签了字了,那责任在谁呢?
我们再来看看互联网时代下带来的变化:
第一点,迭代速度比不出问题重要多了。在互联网时代出个问题,只要不涉及到不可逆的严重情况,问题是可以分级的。需要真正关心的是线上出了问题,能让多少用户感知到这个问题,这个问题的严重程度有多高?如果你的迭代速度足够快,你一个特别严重的BUG放到线上1分钟就能定位,5分钟就能Release修复,可能只影响到了非常少的人,可以用你的迭代速度去弥补你出现的问题。
第二点,因为互联网是一个不确定的场景,我们无法提前预知说我们的设计一定就是非常完美的,需要不断的试错。所以一个基本功能的MVP,也就是一个功能的最小化产品单元,比一个完备的产品设计要重要多了。花两个月做一个假想的”99分“的产品,对比花一天做一个60分MVP的先试水用户,哪个效率高呢?肯定是后者,但前提是你要达到60分。40分的时候你做试水的时候是伤用户的,60分是来实验方向的,可以指导后续的不断深耕。
第三点,有了第一第二点,用户反馈就显得比按期交付更重要了。只有拿到用户反馈了你才知道你这个交付有没有价值。所以,应该用最小化的产品单元,用最快的迭代速度,将用户的反馈收集到,确定这个产品的功能要不要,或者做不做深耕,要不要再花两个月。
在互联网时代下,对比传统软件时代,我们的最终生产效率能差多少?10倍肯定是有的。如果一个公司能比另外一个公司的效率差10倍,我觉得效率就是第一竞争力。

我们再举个互联网时代公司的例子:Facebook。Facebook是一个蛮有趣的公司,它的做事风格,即使在硅谷,在湾区,也是自成一派的。我们会看到里面有非常多的好玩的地方,都是基于软件时代的痛点做的一些修正。并且通过正反馈的机制,让在Facebook工作的每一个人都亲身体会到了效率带来的巨大差别。
我们来看看Facebook具体是怎么做的。Facebook的一个最小TEAM单元叫做三人组,是设计师、产品经理和工程师,三个人就可以完成一个基本的功能。着三个人之间不是一个流水线上的各自独立的环节,而是混在一块商讨说我要不要试这个功能,如果要试的话如何最快拿到结果。如何能先上线,拿到反馈,确定要不要做下一步,大家互相交织。
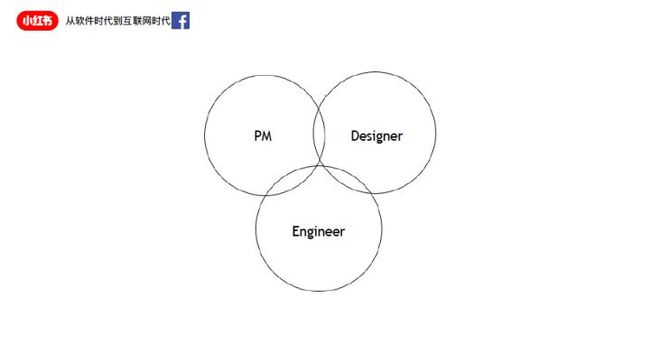
在这个情况下,我们说的产品经理,他不再只是Product Manager。他在这个场景下是Problem Manager,他需要做的是把问题抛出来,给设计师,给工程师,让大家能看到问题的全貌,一起来探索解决的方案。
工程师也不该只把自己定义为一个功能实现者,叫做我把你的文档翻译成代码,交给测试和运维,结束了。他是解决问题的人。工程师面对的其实不是产品经理,工程师面对的是终端用户,以及这些用户需要被协助解决的问题。小三人组里面的工程师基本上什么都会,他不是一个XXX工程师,比如说前端工程师、后端工程师、数据工程师,首先是一个工程师,之后才是附加在工程师之上的前后端、运维,等等这样的技能。他是一个问题集合Problems Solver。在这里,他要负责解决用户侧问题的整个周期,要解决跟产品经理讨论出来的用户侧产品侧的问题,最终将它能交付给真正的用户,并且能够验证成功。
三人组这样的团队,与那个按职能来划分的团队相比,有什么区别?
第一点,对问题是负责的,大家所有人不再是只负责流水线上的一环,而是负责最终的结果。
第二点,因为存在大量的面对面交流,而不是文档交流,它的结果是对于主观能动性的激发是大的。
这两点是为什么能激发10倍的效能的基础。我觉得人这个因素非常重要,对一件事情有Ownership可以激发个人巨大的效能。10倍的差距,我觉得在一个以不确定性的创造为主要的行业里面真的可以产生。
以效率为中心,带来了哪些变化呢?
A) 变化1:团队
我们先来看看团队的变化,刚才软件时代的例子是按照职能进行划分的,我们来举一个互联网时代的实际例子。
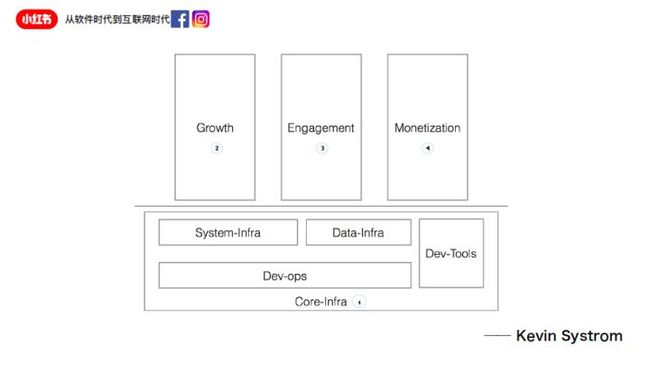
这个是Instagram前CEO Kevin对于每一个新加入Instagram 的人都会讲的ig的团队是怎么建设壮大的以及为什么。对于一个创业公司而言,所有人都在一块儿,我这儿喊一声说我们要做什么,大家就一起做了,没有那么细的划分。团队变大了,一定要有术业有专攻。所以,对于Instagram而言,第一个切分出来的团队是什么?是基础架构,core-infra,它面向的是所有的其它工程师和其它内部的团队,他们支撑的是一个底层的业务。
那上面第二个拆分出来的团队是Growth。增长黑客其实是每个公司都应该有的一个增长团队,这个增长团队是闭环的,里面有各种职能,有前端、后端、运营、设计、数据、算法,为了目标就是一个,如何协同一起把这件事情做成,把问题解决。
之后,还会切分出来,比如用户交互和留存为目标的Engagment团队,以及怎么赚钱的monetization团队。
团队的切分方式都是以能让大家分享同样一个用户侧的目标,或者是公司级的目标,而不是单纯按照横向技能和职能来划分。
在实际场景当中,大家常见到的问题就是,最怕的就是跟自己职能不一样的人放在一起。我从实际面试经历也好,或者跟大家聊天也好,我们遇到最多的问题就是,你们小红书这个公司是技术驱动、产品驱动、设计驱动,还是运营驱动啊?我认为,单一驱动在今时今日这个场景下面是不存在,任意一个职能都不能成为其中驱动的唯一的因素。
那驱动大家的东西是什么?我们认为是用户侧的反馈,或者叫数据,就是只有真实的使用反馈才是重要的。所有每个人都应该放下只有我说了算的EGO,平等的对话,在各个地方收集问题,一起找到解决路径。
B) 变化2:数据
在这样的团队里面,带来了第二种变化,数据无比重要。职能不一样,团队的共同语言是什么?目标,团队需要对齐目标。所以,数据驱动决策是什么意思?就是团队里面每个人都需要去阅读数据,每个人都需要懂数据。
我们看看数据到底驱动了啥。数据驱动分几个级:
第一个就是公司级,就是主要给老板看。出个Dashboard,加个BI团队,负责给老板跑数。我觉得这是数据驱动的基本层级。这是低level。
中等level是团队级,每个团队都有自己的可以量化的目标和结果。每个团队自己要去想的,我做事情不是交付一个东西就好了,我要知道它对最终结果产生什么样的变化。
那么高等level的是什么样的 呢?就应该是团队当中的每一个人每天都在跟数据打交道,每个人都能用数据,每个人都会用数据。我做了一件事情,假如说我可以现在做完,5分钟之后上线,那么第6分钟的时候我就能收集到用户反馈了。如果我胆子大一点,我可以上线到1%的用户,那我就知道用户会不会对这个功能买账了,几个小时,几天以后我就可以迅速下决策了,迭代速度无比快。但这样的迭代速度和人人会用数据,是需要有配套的机制和工具做辅助的。

我举个Facebook的一个例子。在Facebook内部,这是大概五年前的样子,三大工具:Scuba,Hive,Ods。ODS传统KV储存,主要是一些计数器,就比方说有多少人点击,有多少个点赞,这块在后期ODS已经逐步退役了。HIVE就是数据仓库。Facebook做了很多贡献在HIVE上面,可以跑很大的数据量,缺点就是反应慢,通常是天级的数据计算和存储的任务在上面。离日常工作最近的,分钟级别的数据工具很重要的是SCUBA。SCUBA是一个外界提的比较少的,因为没有开源;但在Facebook内部是人见人爱,大家日常使用最多和最有帮助的工具。当年还没有兴起OLAP这个概念,SCUBA基本上就是一个实时OLAP的例子,可以实时地做多维聚合。
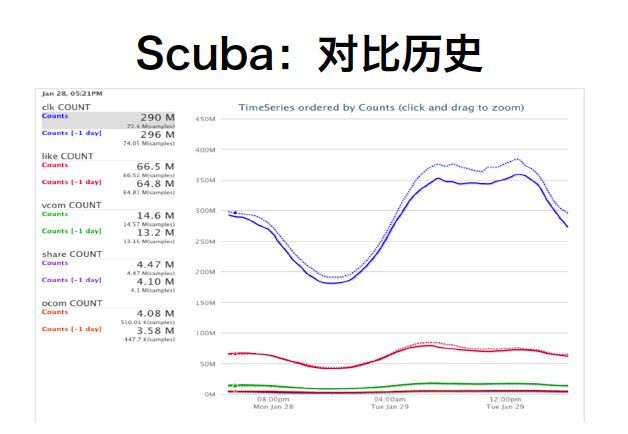

这个大概就是SCUBA当年设计的一个原型,基本上是在各个端上做数据收集,然后开始在一个data Engine上跑。最后也是最重要的是有一个配套的WEB UI,这个Web UI能干吗?这个UI是可以通过交互实时地生成Query和生成可视化结果,大大的降低了数据使用的门槛。在整个Facebook里面绝大多数的团队里面,无论是设计师、产品经理、数据分析师、工程师,几乎是所有的人都会用SCUBA。这个学习成本没那么高,在左侧那个地方点一点,就可以拿出你想要的数据。你可以看到这些数据的变化、历史对比。然后一些常用的query,你是可以留下来,变成一个Dashboard。
我举个实际例子,这些东西是怎么生成的呢?我今天上线了一个新功能,我想知道有多少人用,我会在我的对应的模块上加上日志,就是打点log。这个打点数据会通过各种方式,当年用的scribe自动地存到SCUBA系统里面去,这些事情都已经工具化。我需要做的事情就是我在SCUBA上定义我要看到的那个值,然后等我上线第一分钟就开始刷新,点了之后发现比我想的好就接着跑或者放大流量;比我想的差,赶紧关掉。因为可以实时交互和反馈,每个人都可以参与的一个数据分析工具。
这块Scuba没有开源,有兴趣的可以看一下Scuba的论文。开源的类scuba解决方案目前主要有用Superset做前端,Druid做Data Engine。基本上是我们现在OLAP的一些成熟做法。
实际应用工具当中的一个转变,对人的影响是非常大的,工程师关心的不单是CPU、MEMORY,Latency和QPS,关心的是全链路业务上面的用户反馈,因为你对最终结果负责,所以你要有工具能看到结果长什么样子。
产品经理要有能力自己取数,要有data sense。数据核心的问题不是为了汇报,是为了找到需要改进的方向,产品有什么地方做得不好,有什么地方可以做得更好,每个人都应该有能力去读数,去取数,人人参与。
这样,数据科学家和数据分析师不再是取数工具了,而是可以去做一些更深层的数据分析,找到真正驱动数据变化的深层次原因。
最后数据应该是公开的,数据应该是能够覆盖到尽量多的维度,数据的生产者和数据的消费者应该是一体的,它们不应该是叫做有个需求告诉我要生产这个数据,我也不知道为什么。而是说,我就想知道我做了这个功能有没有人用,我这个功能有多少人用,用得好不好,这才是最大的驱动力。
C) 变化3:职责
那么有了各种各样的工具,我们回过头来说第三种变化,就是对于过程负责还是对于结果负责。刚才谈论了很多次了,最核心的一点就是只对中间过程负责的效率是低的,因为看不多全局,整体出了很多问题,独善其事是无法驱动最终结果变好的。
对结果负责很重要的一点,或者说做出成功产品的团队核心是什么?叫做DOGFOODING。

DOGFOODING是什么意思呢?就是自己用自己的功能,自己吃自己的狗粮,或者狗屎。自己做出来的功能,首先自己要先用起来。你看到说,我对这个功能特别不喜欢,你要把意见反馈出去,如果你看到这个功能,我觉得我特别喜欢,想尝试一下,那你要有这个勇气,或者有这个权力,能够去实验一下。
在Facebook有几种简单的工具去支持大家快速做用户侧尝试,哪怕是只给自己使用尝鲜:
一种是gatekeeper。gatekeeper就是一个功能的门卫,可以通过在gatekeeper上设置一个过滤条件,比如说这个功能只能有1%的用户可以看到,或者只能有新西兰的用户能看到,我要对一小批用户做测试。甚至可以Targeting各种不同的年龄、性别、产品入口等等这样的东西。
另外一种就是AB测试了,切10%的用户尝试新功能,另外10%的用户最对照。
那工具为什么可以让大家变成对结果负责呢?原因叫做赋能。因为有能力,所以有担当。

各位工程师肯定知道,好多公司内部千百次的说我们要做code review,但没有一次做得好的,这个review最后就是大家走走过场。为什么做不好?没有赋能。
Facebook的code review做得非常好,里面还加了很多辅助工具,比如Lint,CI等等,保证能够在review的时候尽量可以拿到和线上实际运行近似的效果。为什么做这么多工具辅助review?答案是:胆子小。Facebook任意两个工程师,一个人提交代码改动,另一个人review通过了,这个改动就可以上线了。你敢不提交code review吗?你对自己的提交的改动和review别人的代码能不负责吗?好了算你的,坏了也算你的,需要担当结果,对质量的要求就会成倍的提升。

除了靠各种CI,Canary工具以外, gatekeeper和AB testing也可以让你小流量去实验,实验个5000用户,觉得没问题,再放大,用这样的工具去辅助这样的权力。
这样做有什么好处?ship early, ship often。做好非常简单的MVP,就可以上线测试了。拿到真实的用户反馈数据后,一种是看到这个功能和预期不相符,不work,我们不用继续做了。另一种可能是,发现功能上还是有很多粗糙的地方,我们前期没有想清楚,赶紧迭代。这样一个反馈周期,原来是月级别,现在可以做小时级。
大家看到有非常多的需求文档在排期,感觉其中80%不靠谱,又说服不了对方,双方开始扯皮,开始需求评审,这时候不如轻量级试一下用户的反馈,也能让大家对各自判断有个更好的认知。
一个有ownership的团队会怎么做,从数据出发,找到改进的方向。上线做验证,小流量验证之后,你就可以尝试去full launch到100%。
我们总结一下在互联网时代,为什么Data driven和ownership可以提供10倍的效能差别?就是在大目标对齐的情况下,各个小团队之间可以组成一个分布式的决策机制,大家可以跨职能的团队协作,去中心化进行决策,做到面对不确定性时的敏捷。
3. 小红书的实践
最后我们来看一下过去这两年,对于效率,我和我的团队一起在小红书的一些真实的实践。
小红书是一个生活方式平台,里面涉及到衣食住行,吃喝玩乐,并且可以完成从发现到决策到记录的全链路流程。
我们是一个面向用户、有丰富数据的平台,这是我们产品上的天生优势。我们一天的用户阅读量有数十亿次,这种流量规模情况下,我们可以做非常多的AB Testing,用1%的流量就可以做非常多的事情。
我们刚才讲的对于各种效率理念,在过去两年一步一步在小红书做落地实践。但是,道理都懂,也不一定能过好这一生。所有的实践都不是那么一帆风顺的。因为在拐点出现之前大家还是盲目地崇拜强者,或者把盲目删掉,大家还是崇拜强者。强者是什么意思?大家会看到说,我看到A公司,我看到了B公司,我看到了T公司,都是这么搞的,为什么我们不学它?但我觉得,如果以团队效率来看,对于一个现阶段的万人级巨无霸公司,确实在效能上算不上是good case。同时,现实的讲,一个增长型的公司如果照搬成熟公司的做法,充其量也只能做到和别人一样,既然在人数上是远远落后的,就需要在效率上胜出才有希望。
虽然有种种挑战,过去的两年里面我们还是摸索着落地了很多效率层面上的改进:
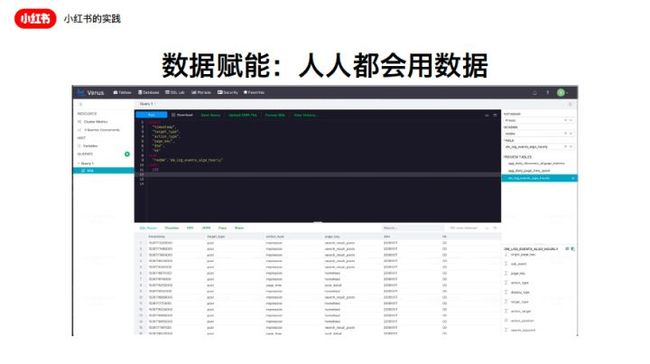
首先第一点:数据赋能。每个人都会玩的数据平台。在这里我们自己做了一个前端,后面主要是Hive,Presto,Spark等等这样的数据计算平台。在这里用户可以套用模板写query。在小红书团队中最引以为傲的一点是,几乎每个人都会写,PM会,数据分析师会,工程师更要会,去写,去取数据。然后通过一些工具可以把这些数据变成一个图,或者是变成一个每天监控的dashboard,还可以变成high level的报警。
我们现在做不到秒级,我们现在只能做到比如说半小时级的数据更新,还在路上。我们未来是希望这些工具都可以做到实时。
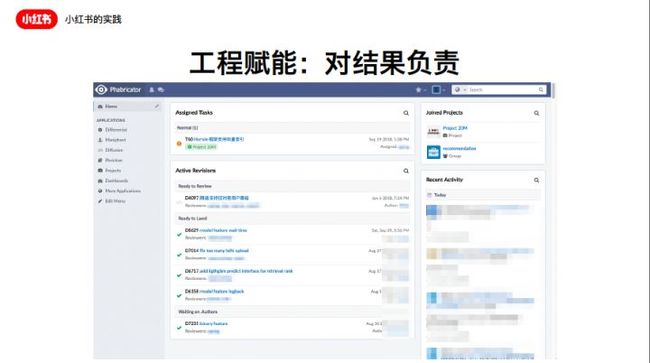
第二点,工程赋能。工程师有能力决定自己功能什么时候上,要什么时候上,或者要不要上。我们用了Phabricator做Code Review,集成了后面Jenkins做CI。所以工程师在这里边每天会看到说我现在有多少个Diff等着我去Review,以及我的diff在被review的状态是什么样子。当有一个reviewer点击了accept,就代表可以上线了,就触发了我们最终的deploy流程,就上到线上,这是对于工程权力的下放。
第三点,实验赋能。我们现在线上AB testing平台一天有300+个实验,也就是说我们每天在尝试的新功能有300多个。虽然实验的速度非常快,但结果是这样的,大部分的实验最终都无法上线。300多个实验,200多个都是要关掉的。但我们非常鼓励的一件事情是AB testing的成功率不应该太高。如果大家在自己的公司里面,AB testing的成功率是90%,这是不对的,肯定是大量的功能没有敢去尝试,肯定AB testing都是有筛选门槛的,选的才能上AB testing的。AB testing就是应该犯错的,AB testing就应该是10%的成功率才对,或者更低,代表实验的效率更高和跑得更快。
我们刚才讨论这些关于效率的话题,在小红书团队里面都有所实践并且一直在进步。我能看到工程师、产品经理、数据分析师在团队里面效能的变化,效率成倍的激变。
我们大概在今年年初的时候,我们整个的用户突破了1亿,现在已经超过1.5亿。小红书所有核心指标都是一年4倍到5倍地指数级增长。
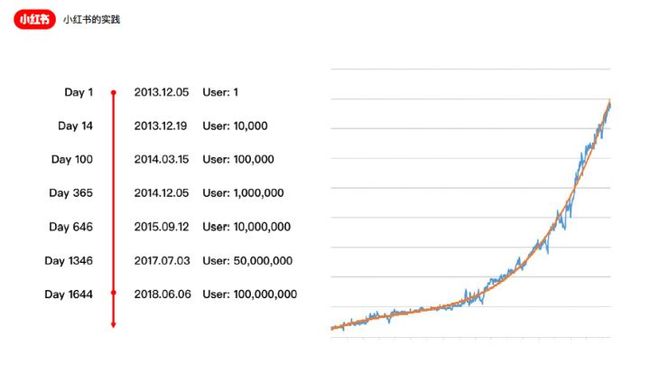
我们就是一个从十来个人的团队到100多人的团队,QPS从百到万到十万,去撑起了这么一个每年5倍左右的核心metric的变化。
那么从硅谷到中关村到底有多远呢?在小红书,我们其实就是为一线团队做两件事情,一个叫做放权,一个叫做赋能。放权的意思是通过Data Driven的方式给予决策权的分布式下放;赋能的意思是通过工具,无论是测试工具也好,CI也好,实验平台也好等等这样的工具能让团队每个人有ownership。最后,欢迎大家加入小红书团队,来一家高增长的公司高效率地做事情。
小红书以下职位正在热招中!
开发岗
视频架构工程师——北京
数据平台架构师——北京
推荐系统架构工程师——上海
资深JAVA架构工程师——上海
后端开发工程师——上海
数据开发工程师——上海
前端开发工程师——上海
Android开发工程师——上海
iOS开发工程师——上海
算法岗
计算机视觉算法工程师——北京
社区搜索技术负责人——北京
搜索算法工程师——北京
广告算法工程师——北京
反作弊负责人——上海
推荐算法工程师——上海
NLP算法工程师——上海
投递简历请以“岗位-姓名-联系方式-工作地”的形式,将简历发送至[email protected];更多岗位信息点击http://xiaohongshu.zhiye.com了解