目录
- 1.展示PTA总分
- 一维数组:
- 二维数组:
- 字符数组:
- 2.本章学习总结
- 2.1. 学习内容总结
- 引例:为什么要学习数组?
- 主干知识梳理
- 数组:
- 一维数组
- 二维数组
- 字符数组
- 重点技巧总结
- 1.查找数组中的数据
- 2.排序法
- 3.哈希表的数组用法
- 4.插入、删除数据
- 2.2 本章学习体会
- 学习感受
- 教学建议
- 代码量统计
- 3.PTA实验作业
- 3.1删除重复字符
- 3.2判断E-mail地址是否合法
- 3.3A-B
- 3.4大数加法
- 4.阅读代码
1.展示PTA总分
一维数组:
![]()
二维数组:
![]()
字符数组:
![]()
2.本章学习总结
2.1. 学习内容总结
引例:为什么要学习数组?
如题,不知道大家有没有思考过,为什么有数组这种东西?我们为什么要学习数组?我们在学习的时候,一定不能是课本在那里“奉天承运,皇帝诏曰”,然后我们就“吾皇万岁万岁万万岁!”开始学习数组。
存在即合理,我们来看这道例题:
计算天数
代码实现:

放到现在,这道题目相信已经不能给大家构成威胁了吧,但是如果是这么写,我们就需要提前加好不同月份对应的总天数,这显然不是效率高的办法,我们有没有其他方法可以集成管理各个月份的天数呢?
数组法:
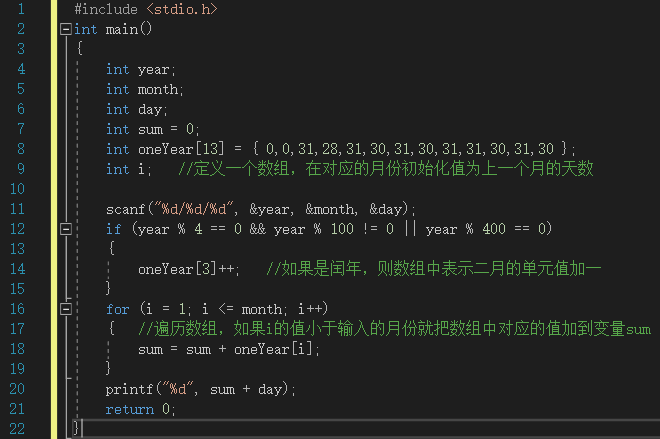
我们定义了一个数组,集成处理了月份的天数,使得我们编写程序时效率更高了,程序的灵活性也提升了。
当面对大量的数据,我们该如何将这些数据有效的记录?难道要定义一堆的变量吗?这显然不是好方法,学习了数组,我们就有了一个很好的工具处理多个数据。你可以把数组想象成一个容器,这个容器有很多的格子,可以存放东西,所有的格子能存放的东西的类型是一样的,同时,这是一个容器,它不会变大,也不会变小,相信通过这样的想象,你就能理解什么是数组了。
主干知识梳理
数组:
数组是一些具有相同类型的数据的集合,数组中的数据按照一定的顺序排列存放。 同一数组中的每个元素都具有相同的数据类型,有统一的标识符即数组名,甩不同的 序号即下标来区分数组中的各元素。
在定义数组之后,系统根据数组中元素的类型及个数在内存中分配了一段连续的存储单元用于存放数组中的各个元素,并对这些单元进行 连续编号,即下标,以区分不同的单元。每个单元所需的字节数由数组定义时给定的类型来确定。
C语言规定,数组名表示该数组所分配连续内存空 间中第一个单元的地址,即首地址。由于数组空间一经 分配之后在运行过程中不会改变,因此数组名是一个地 址常量,不允许修改。
我们需要注意区分数组的定义和数组元素的引用,两者都要用到“数组名[整型表达式」”。定义数组时,方括号内是常量表达式,代表数组长度,它可以包括常量和符号常量,但不能包含变量。也就是说,数组的长度在定义时必须指定,在程序的运行过程中是不能改变的。而引用数组元素时,方括号内是表达式,代表下标,可以是变量,下标的合理取值范围是[0,数组长度-1]。
- 在编程时,注意不要让下标越界。因为,一旦发生下标越界,就会把数据写到其它隨所占的存储单元中,甚至写入程序代码段,宥可能造成不可预料的运行结果。
一维数组
1.定义:
定义一个数组,需要明确数组变量名,数组元素的类型和数组的大小(即数组中元素的数量)。
一维数组定义的一般形式为:
类型名数组名 [数组长度];类型名指定数组中每个元素的类型;数组名是数组变量的名称,是一个合法的标识符;数组长度是一个整型常量表达式,设定数组的大小。
- 数组长度是一个常量。
2.引用
定义数组后,就可以使用它了。C语言规定,只能引用单个的数组元素,而不能一次引用整个数组。
数组元素的引用要指定下标,形式为:
数组名[下标]下标可以是整型表达式。它的合理取值范围是[0,数组长度-1],这些数组元素 在内存中按下标递增的顺序连续存储。数组元素的使用方法与同类型的变量完全相同。
- 数组下标从0开始,下标不能越界。
3.初始化
和简单变量的初始化一样,在定义数组时,也可以对数组元素赋初值。其一般形式为:
类型名 数组名[数组长度」{初值表}初值表中依次放着数组元素的初值,数组的初始化也可以只针对部分元素,如果对所有元素都赋了初值,就可以省略数组长度。 显然,如果只对部分元素初始化,数组长度是不能省略的。为了改善程序的可读性,尽量避免出错,我们在定义数组时,不管是否对全部数组元素赋初億,都不要省略数组长度。
- 虽然C语言规定,只有静态存储的数组才能初始化,但一般的C编译系统都允许对动态存储的数组赋初值。
4.使用
数组的应用离不开循环。将数组的下标作为循环变量,通过循环,就可以对数组的所有元素逐个进行处理。
二维数组
C语言支持多维数组,最常见的多维数组是二维数组,主要用于表示二维表和矩阵。
1.定义
二维数组的定义形式为:
类型名 数组名[行长度][列长度];2.引用
引用二维数组的元素要指定两个下标,即行下标、列下标,形式为:
数组名[行下标][列下标]行下标的合理取值范围为[0,行长度-1],列下标的合理取值范围为[0,列长度-1],注意下标不要越界。
二维数组的元素在内存中按行/列的方式存放,即先存放第0行的元素,再存放第1行的元素……其中每一行的元素再按照列的顺序存放。
由于二维数组的行列下标从0开始,而矩阵或二维表的行(列)从1开始,用二维数组表示二维表和矩阵时,就存在行(列)计数的不一致。为了解决这个问题,可以把矩阵或二维表的行(列)也看成从0开始,即如果二维数组的行(列)下标为k.就表示矩阵或二维表的第k行(列);或者定义二维数组时,将行长度列长度加1,不再使用数组的第0行(列),数组的下标就从1开始。
3.初始化
定义二维数组时,也可以对数组元素赋初值,二维数组初始化方式有两种。
1.分行赋初值
一般形式为:
类型名 数组名[行长度][列长度]={{初值表0},……,{初值表k},……};把初值表中k的数据依次赋给第k行的元素,同时,二维数组初始化也可以只针对部分元素,。
2.顺序赋初值
类型名 数组名[行长度][列长度]={初值表};如果只对部分元素赋初值,要注意初值表中数据的书写顺序。在初始化时,如果对全部元素都赋了初值,或分行赋初值时,在初值表中列出了全部行,就可以省略行长度。
- 与一维数组情况类似,我们建议定义二维数组时不要省略行长度。
4.使用
将二维数组的行下标和列下标分别作为循环变量,通过二重循环,就可以遍历二维数组,即访问二维数组的所有元素。由于二维数组的元素在内存中按行优先方式存放,将行下标作为外循环的循环变量,列下标作为内循环的循环变量,可以提高程序的执行效率。
字符数组
1.字符串
字符串常量就是用一对双引号括起来的字符序列,即一串字符,它的结束标志时'\0'。字符串的有效长度就是有效字符的个数,C语言将字符串作为一个特殊的一维字符数组来处理。
2.存储——数组初始化
字符串可以存放在一维数组中,例如:
static char s[6]={'H','a','p','p','y','\0'};也可以使用字符串常量,例如上述代码等价于:
static char s[6]={"Happy"};或
static char s[6]="Happy";将字符串存入数组时,由于它有一个结束符'\0',数组长度至少是字符串的有效长度+1。如果数组长度大于字符串的有效长度+1,则数组中除了存入的字符串,还有其他内容,即字符串只占用数组的一部分。
- 字符串由有效字符和字符串结束符'\0'组成。
3.操作
将字符串存人一维字符数组后,对字符串的操作就是对该字符数组的操作。但是,它和普通字符数组的操作又有所不同。以遍历数组或字符串为例,由于普通数组小数组元素的个数是确定的,一般用下标控制循环;而字符串并没有显式地给出有效字符的个数,只规定在字符中结束符'\0'之前的字符都是字符串的有效字符,一般通过比较数组元素的值是否等于'\0'。来决定是否结束循环,即用结束符'\0'控制循环。
4.存储一一赋值和输入
将字符串存人数组,除了上面介绍的初始化数组,可以采用赋值和输人的方法。输人的情况有些特殊,由于字符串结束符'\0'代表空操作,无法输入,因此,输入字符串时,需要事先设定一个输人结束符。一旦输入它,就表示字符串输入结束 将输入结束符转换为字符串结束符'\0'。
- 区分"a"和'a',前者是字符串常量,包括'a'和'\0'两个字符,用一维字符数组存放;后者是字符常量,只有一个字符,可以赋给字符变量。字符串输入函数
字符串输入函数
1.格式化输入函数scanf( )输入字符串时,格式控制符用“%s”,注意该函数读取到空格、回车、换行、制表符即停止输入,这是一个世界难题,使用的时候务必注意;
2.gets()函数:gets从标准输入设备读字符串函数,读取单行字符串,不会判断上限,读取到回车或EOF结束读取,使用格式,定义一个名称为str的字符数组,语法“gets(str)”,但是这个函数不安全,我们需要保证字符数组的空间足够大,以便在执行读操作时不发生溢出,函数有返回值,读入成功,返回指针,若读入过程中遇到EOF或发生错误,返回NULL指针;
3.fgets()函数:fgets函数功能为从指定的流中读取数据,每次读取一行。其原型为:char fgets(char str, int n, FILE *stream);从指定的流 stream 读取一行,并把它存储在 str所指向的字符串内。当读取 (n-1) 个字符时,或者读取到换行符时,或者到达文件末尾时,就会停止读入,具体视情况而定。该函数可以认为是gets的安全版,如果读取成功,该函数返回相同的str参数,如果到达文件末尾或者没有读取到任何字符,str的内容保持不变,并返回一个空指针。如果发生错误,返回一个空指针。
字符串输出函数
1.格式化输出函数printf( )格式控制符用“%s”;
2.puts()函数:将字符串输出,puts函数一次只能输出一个字符串,字符串中可以包括转义字符,输出时将'\0'转换为回车换行。其调用方式为“puts(s);”其中s为字符串字符(字符串数组名或字符串指针)。
5.使用
C语言将字符串作为一个特殊的一维字符数组来处理。采用数组初始化、赋值或输入的方法把字符串存入数组后,对字符串的操作就是对字符数组的操作。此时,对字符数组的操作只能针对字符串的有效字符和字符串结束符,这就需要通过检测字符串结束符来判断是否结束字符串的操作。
重点技巧总结
1.查找数组中的数据
请看例题二分查找法
1.直接查找法
不解释直接上代码:

这个方法大家都会,也简单粗暴,不是要查找数据吗,那我就把所有的数据都查一遍,当然可以实现目的了。
但是,请你思考一个问题,这道题是是个数据,不算多,那么如果是100呢?10000呢?1000000000甚至更多数据呢?我们还要从头到尾走一遍吗?那着效率也太低了吧!我们有没有更好的方法?
2.二分查找法:
我想起在我读小学的时候,在杂志上读到了这样一个故事:
有这么一支军队,在行军过程中,军师收到了一个坏消息——在军队中,有个士兵感染了病毒,他知道自己得了病但是谎报了军情,如果不加以治疗,一段时间后病毒就会开始扩散,就让整支军队陷入危险之中。军师急忙找来了军医,军医分析,患者病情不明显,外表看不出异常,但是可以通过验血来确定,但是这支队伍是100000大军,而军医在神秘力量的影响下,每天只能验10份血样,一个人一个人验血需要10000天,根本来不及啊?怎么办?
军师挥挥羽扇,计上心来,军师说:“我有办法,我们把100000大军分为10支小队,然后每支小队每个人第一滴血,混合成10份血样,军医你验这10份血样,有病毒的血样对应的小队第二天再分成10支小队,进行同样的操作,重复5天,即可找到感染源!”军医如法炮制,果真在第五天找到了得病的士兵,拯救了整支军队!

屏幕前的你,是那位聪明的军师吗?如果军医真的一个一个士兵验血验过去,那得验到什么时候啊?军师巧妙地利用了折半的方法,把军队分成好几个组,逐步缩小范围,最终找到了目标。我们能不能将这个思想运用到数组数据的查找中呢?
换汤不换药,这就是二分查找:
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。
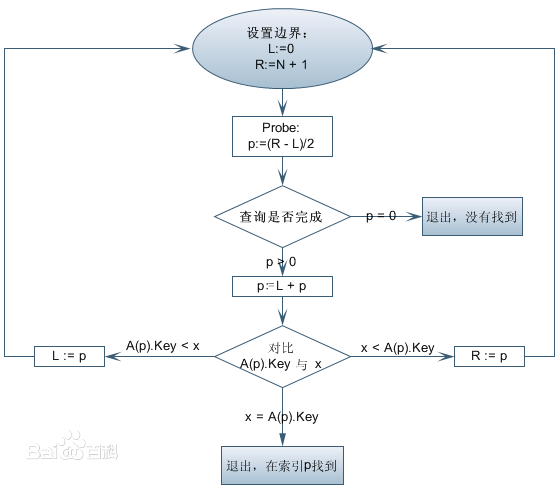
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。——《百度百科》
这显然不是人话,我们直接看伪代码吧:
定义数组num[10] = { 1,2,3,4,5,6,7,8,9,10 }作为被查找数据;
定义变量top = 9存储最大下标;
定义变量mid = 0存储给定区间的中间下标;
定义变量tail = 0存储最小下标;
定义变量key存储需要查找的数据;
输入key;
while tail <= top do
mid = (tail + top) / 2;
if key == num[mid] //如果key被成功定位
输出变量mid;
break; //结束循环
else //如果没有成功定位
if key > num[mid]
tail = mid + 1; //在mid右边,则移动最小下标
else
top = mid - 1; //在mid左边,则移动最大下标
end if
end if
end while
if (top < tail) //如果范围最小下标大于范围最大下标,说明没有查找到
输出"not found";然后我们把它变成代码:

二分查找法充分利用了数据间的次序关系,采用分治策略,在较高效率下完成搜索任务。它的基本思想是:将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的x作比较,如果x=a[n/2]则找到x,程序终止;如 果x
- 这个方法仅限于数组的数据是按照大小顺序排列的情况下。
2.排序法
请看例题选择法排序
在写题目或者处理各种应用问题中,我们经常需要对数据进行排序处理,对于我们而言,需要重点掌握选择法排序和冒泡法排序:
冒泡排序
这是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。

我们还是说人话,冒泡排序可以想象成为一列长队按照身高排列,负责人不怕麻烦,从头到尾两个两个人进行比较,如果前高后矮就交换,一个一个安顿好,一遍不行再来第二遍,直到每一个人的位置都安排妥当了。

伪代码:
定义变量fre存储数组单元个数;
定义变量temp作为交换数据的中间变量;
定义数组num[10]存储输入的变量;
定义变量i1,i2控制循环;
输入变量fre;
输入数组num;
for i1 = 0; i1 < fre; i1++ do //重复操作,直到排序完成
for i2 = 0; i2 < fre - i1 - 1;i2++ do //对每一对相邻元素比较大小
if num[i2] < num[i2 + 1] //比较相邻的元素,如果第一个比第二个大,就交换
交换数据num[i2]和num[i2 + 1];
end if
end for
end for
输出数组num;代码实现:

- 冒泡排序的稳定性较好,但是不适合用于数据较多的数组排序。
选择法排序
这是一种简单直观的排序算法。它的流程是先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。

我们再打个比方,还是一列长队按照身高排列,但是这次的排队负责人不是很有耐心,他从队伍中选择最矮的人站到最前面,接着选择第二矮的人站到第二位,一直选下去,直到把队伍排好了。

伪代码:
定义变量fre存储数组单元个数;
定义变量temp作为交换数据的中间变量;
定义数组num[10]存储输入的变量;
定义变量i1,i2控制循环;
定义变量idx记录需要交换的下标;
输入变量fre;
输入数组num;
for i1 = 0; i1 < fre; i1++ do //重复fre轮操作
idx=i1;
for i2 = i1 + 1; i2 < fre;i2++ do //寻找对应大小的值
if num[idx] < num[i2] //如果下标idx的值比i2的值小,记录i2
idx=i2;
end if
end for
交换num[idx]和num[i1];
end for
输出数组num;代码实现:

选择排序可能是一般人最直观想到的排序方法。选择排序相对于冒泡排序稳定性较差,操作时数据规模越小越好。
超详细十大经典排序算法总结
如果你对其他排序法有兴趣,我推荐这篇文章给你阅读。
3.哈希表的数组用法
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。——《百度百科》

这啥玩意?我们还是用人话来讲,请看例题有重复的数据
伪代码
定义变量fre存储数据个数;
定义数组num[100001]={0}来统计数字0到100000各个数字的出现个数;
定义变量get表示存储需判断是否重复的数据;
定义变量flag作为是否有重复的flag;
定义变量i控制循环;
输入fre;
for i = 0; i < fre; i++ do
输入get;
num[get]++; //get对应的数组单元加1
if num[get] > 1 //如果单元的值大于1,说明出现重复
flag = 0;
输出"YES";
break;
end if
end for
if flag == 1
输出“NO”
end if你看懂这段伪代码了吗?我们再来打个比方,假设有一张清单,

然后我需要根据清单来统计不同东西的个数,如果我发现了某一个东西,则我就在清单上给这个东西加上1,这么讲你就明白了吧。等清单记录完成之后,这份清单就像是备忘录一样,我们回头想要知道某一个东西有多少个,直接查表就行了。
代码实现:

如果我们先抓取一个数,然后根据这个数去寻找数组中是否有重复的数据,那么就需要用到二重循环,万一数据极端,在第100000个数字发生重复,则循环可能要执行100000×100000次,这样的话时间就多了,效率就低了。相反,我们利用哈希表的思想,定义一个数组存储单个数字出现的个数,使得程序效率大大提高。
在作业中,一共有四题能够运用这种思想,其中调查电视节目受欢迎程度这题比较简单,不展开叙述,其他两题我放在下文详细解析。
4.插入、删除数据
我们还是用排队来举例,假设你很喜欢在西苑餐厅吃饭,现在你正在排队准备买饭,这时有个人气喘吁吁地冲进来,神情紧张,显然他可能有很急的事情。你好心地问他:“兄弟,我看你眼神飘忽,双腿发抖,相必有什么要紧之事吧!”那人答道:“兄弟说得是啊!我今天要赶去拯救世界,可惜闹钟没响,睡过了头,一下子就睡到中午了,大哥,你可否让我插个队,我买完饭就赶车去保卫地球!”你一拍大腿:“这可是地球的大事啊!来来来,兄弟还请排在我前面。”就这样,你今天让这位神秘的勇士插了队,同时因为他的插队,包括你在内的后面所有人都得往后退一个身位。
但是,由于西苑餐厅的饭太香了,排队的人实在多,等了一段时间,那位兄弟还是没有买到饭。“大哥,感谢你的好意,但是我如果因为买饭再晚一步,地球就会完蛋,不行了,我必须先走一步了!”话音刚落,这位兄弟就消失在了你的面前。希望他能成功拯救世界吧,不过现在我前面少了一个人,能够更快地吃到西苑的饭了。就这样,包括你在内的所有后面的人都往前前进了一个身位。

相信有了这段神奇的经历,把排队的队伍当做数组,现在的你就可以明白我们如何在数组中插入或删除数据了吧。
插入数据
请看例题简化的插入排序
直接看伪代码:
定义变量fre存储输入的数组单元数;
定义数组num[10]存储输入的数组;
定义变量insert存储需要插入的数据;
定义变量i,j控制循环;
输入变量fre;
输入数组num[10];
输入变量insert;
for i = 0; i < fre; i++ do
if insert < num[i]
for j = fre; j > i; j-- do
num[j] = num[j - 1]; //将num[i]之后的数据向后移动一个单元
end for
break;
end if
end for
fre++;
num[i]=insert; //插入数据
输出数组num[10];代码实现:

删除数据
请看例题数组元素的删除
直接看伪代码:
定义变量fre存储输入的数组单元数;
定义数组num[100]存储输入的数组;
定义变量time存储需要删除的数据个数;
定义变量cut存储需要删除数据的下标;
定义变量i,j控制循环;
输入变量fre;
输入数组num[100];
输入变量time
for i = 0; i < time; i++ do
输入变量cut;
for cut--;cut < fre;cut++ do //将下标cut之后的数据往前移动一个单元
num[cut] = num[cut + 1];
end for
fre--;
end for
输出数组num[100];代码实现:

2.2 本章学习体会
学习感受
这周明显状态就不对了,学习状态异常糟糕!由于10月份忙了一个月,好不容易把工作都搞完了,校运会结束后,能利用的时间明显增多,本来我还挺开心的,因为可以去补回上一个月落下的进度了,也可以做更多的事情了,但事实并非如此。面对突然盈余的时间,我感到不知所措,无从下手,不知道该怎么利用时间,想做的事情太多,却没办法作出决定先做哪一个,没办法像九月份那样有充实的感觉。我能确实感觉到,高数线代在不断退步,英语仍然停滞不前,C语言感觉也到了瓶颈,社团的任务没有跟上,感觉已经面临着全线崩盘的危险了。我在前几篇博客都有提到,我很害怕突然会失去热情,现在果然应验了,我了解自己,只要是现在这种情况,我一定会陷入低迷。现在的当务之急,就是想点办法重新焕发热情,我现在个人斗志很差,没有一个好的气势是没办法学好知识的,第二个是必须赶出一个规划,要先赶上进度,线代的考试,高数的学习,英语的积累必须赶紧安排上了,C语言和社团也必须找到下一个努力方向,不能再这样低迷下去了,不然就完蛋了。
但是大作业方面我觉得还是完成的不错的,我重构了三次代码,每一次重构都有新的思考,都有加进去更多的东西,还是向老师、学长学姐和同学们学到了很多的东西。学习数组时,可以明显地感觉到知识的技巧性,综合性有很大的提高,数组可以做成一维、二维、字符串,不同的数组都有所讲究,技巧方面学习了诸如选择法排序、泡泡排序、二分查找、移动或重构数组、插入或删除数据、空间换时间思想等等,这些都需要去学习,消化吸收,掌握这些技巧对于今后的编程都很重要,难度也比较大,我自认为我没有掌握得很好,因此接下来还是得多打代码来练习。
教学建议
希望接下来能多搞几次大作业!
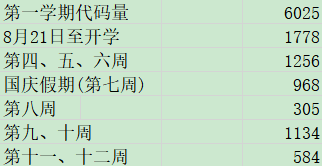
代码量统计
3.PTA实验作业
3.1删除重复字符
3.1.0代码实现

根据常规思路,我们可以很快地打出代码,基本思想是先遍历读入的字符串,然后判断在第二个字符串中是否有与第一个字符串重复的内容,如果没有则写入,如果有则跳过,然后给删除好的字符数组按照ascii码来个排序,即可达成目的。但是,我们知道最后的字符数组是由ascii码由小到大排序的,ascii码是有顺序的,只要是有顺序的,我们就可以用一些技巧去实现它。
3.1.1算法分析
定义字符数组ascii[256]代表每一个ascii码对应的字符在字符串中出现的次数;
定义变量ch存储读取的单个字符;
定义变量i控制循环次数;
while 输入一个字符,ch != '\n' do
ascii[ch]++; //以字符的形式,修改对应ascii码的单元,使其值不为0
end while
for i = 0;i < 256;i++ do
if ascii[i] != 0 //如果对应单元不为0,说明需要输出
以字符形式输出i;
end if
end for3.1.2 代码截图

3.1.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| ad2f3adjfeainzzzv | 23adefijnvz | sample |
| abcd(空格)+-*/(空格)1234 | (空格)*+-/1234abcd | 有其他字符,包括空格 |
| (空格)(空格)(空格)(空格)(空格) | (空格) | 全空格 |
| a | a | 最短字符串 |
| 80个(空格) | (空格) | 最长字符串,全空格 |
3.1.4 PTA提交列表及说明

很明显,第二种方法更为巧妙,它用到的思想是在重复数据中,我们学习到的“空间换时间”,想要灵活运用这个思想,就需要我们给题目相相面,当我们看到题目需要以ascii码的顺序输出时,我们就明白了这里有个看不见的顺序,将它灵活运用,即可用直接打表的方式完成这道题。
3.2判断E-mail地址是否合法
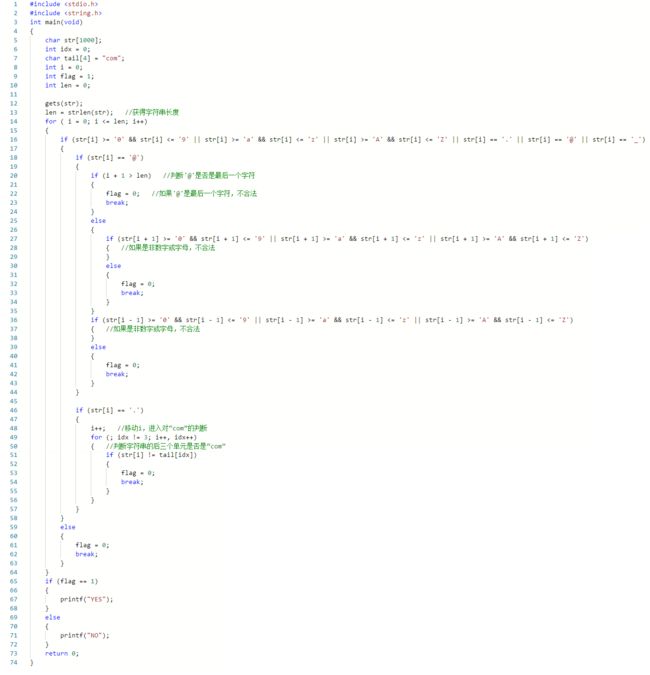
3.2.1算法分析
定义字符数组char str[1000]存储E-mail地址;
定义变量idx = 0作为判断“com”的辅助下标;
定义字符数组tail[4] = "com"用于判断合法性;
定义变量i控制循环;
定义变量flag作为是否是合法地址的flag;
定义变量len存储输入的字符串长度;
读入字符串;
len = strlen(str); //利用字符串函数获得字符串长度
for i = 0; i <= len; i++ do
if str[i]是合法字符
if str[i] == '@'
if i + 1 > len //判断'@'是否是最后一个字符
flag = 0; //如果'@'是最后一个字符,不合法
break;
else if str[i+1]非数字或字母
flag = 0;
break;
end if
end if
if str[i-1]非数字或字母
flag = 0;
break;
end if
end if
if str[i] == '.'
i++; //移动i,进入对“com”的判断
for idx != 3; i++, idx++ do
if str[i] != tail[idx] //判断字符串的后三个单元是否是“com”
flag = 0;
break;
end if
end if
else //数据不合法,结束循环
flag = 0;
break;
end if
end for
if flag = 1
输出“YES”;
else
输出“NO”;
end if3.2.2 代码截图
3.2.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| [email protected] | YES | sample |
| [email protected] | YES | sample等价 |
| [email protected] | YES | 字母数字下划线.@ |
| [email protected] | NO | .com后有多余字符 |
| .@ | NO | 特例1 |
| @. | NO | 特例2 |
| @ | NO | 特例3 |
| . | NO | 特例4 |
| .. | NO | 特例5 |
| @@ | NO | 特例6 |
| a(空格)[email protected] | NO | 字符串中有空格 |
| (空格)(空格)(空格)(空格) | NO | 全空格 |
| [email protected](空格) | NO | 有多余的空格 |
| [email protected]&&& | NO | 合法地址后有非法字符 |
3.2.4 PTA提交列表及说明

Q1:第一次提交,只通过了4个测试点;
A1:紧接着的两次提交分别是直接输出“YES”和直接输出“NO”,知道题目测试点的特点;
Q2:忽略了@之后没有字符的特例;
A2:补上相应的判断机制;
Q3:对于字符串末尾是空格的数据无法准确判断;
A3:将输入方式改为gets,读入整行字符串;
Q4:编译错误;
A4:没有将get_s改为gtes,改回去即可。
3.3A-B
3.3.1算法分析
这道题目又是删除题,正如上文所述,我们先给这道题目相相面,由于这题不是按照字符串删除,也是按照字符来删除,因此我们仍然如法炮制,利用ascii码来实现这段代码。
定义字符数组str存储输入的字符串;
定义字符数组del[256]并初始化为0;
定义字符变量ch读取需要删除的字符;
定义变量i控制循环;
输入原字符串;
while 输入字符ch,ch != '\n' do
del[ch] = 1; //改变对应ascii码对应单元的值,使其不为0;
end while
for i = 0; str[i] != '\0'; i++ do
if del[str[i]] == 0 //基于原字符串判断字符是否需要输出
以字符形式输出str[i];
end if
end for3.3.2 代码截图

3.3.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| I love GPLT! It's a fun game! aeiou |
I lv GPLT! It's fn gm! | sample |
| I'm a vegetable chicken. vegetable |
I'm chicken. | 删除的字符在中间 |
| I'm a vegetable chicken. I'm chicken. |
avgtabl | 删除的字符在两端 |
| vegetable chicken. vegetable chicken. |
全删除 | |
| vegetable chicken. zoo |
vegetable chicken. | 无需删除 |
3.3.4 PTA提交列表及说明
![]()
Q1:编译错误;
A1:没有将get_s改为gtes,改回去即可。
Q2:为什么几乎一遍过了这题,还是写到了博客上?
A2:虽然一次提交就过了,但是整出这段代码没有很快,这道题一开始我想复杂了,但主要是受了重复数字和删除重复字符这两道题目的影响,才进行了尝试。提交之前,也是把测试数据测试到对才提交的。
3.4大数加法
由于第三题和第一题是同一种题型,所以我这里再送一道题出来。
3.4.1伪代码
定义字符数组num1存储第一个大数;
定义字符数组num2存储第二个大数;
定义数组num存储相加后的大数;
定义变量len1,len2存储两个大数的长度;
定义变量bit存储较大的大数位数;
定义变量i控制循环;
输入字符串num1;
输入字符串num2;
bit = len1 = strlen(num1); //获取第一个大数的位数
len2 = strlen(num2); //获取第二个大数的位数
if (bit < len2)
bit = len2; //选择较大的位数作为得数的位数
end if
for i = 0; len1 >= 0; i++, len1-- do
num[i] = num2[len1] - 48; //将第一个大数赋给数组num
end for
for i = 0; len2 >= 0; i++, len2-- do
num[i] = num[i] + num2[len2] - 48; //将第二个大数加给数组num
if (num[i] >= 10) //判断是否有进位
num[i] = num[i] - 10;
num[i + 1] = num[i + 1] + 1;
end if
end for
if (num[bit + 1] > 0) //判断最高位是否发生进位
输出数组单元num[bit + 1];
end if
for ; bit > 0; bit-- do
输出数组单元num[bit];
end for3.4.2代码截图

3.3.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 92345434336786876823540234787293542423 13343434323979878542919487294910345782 |
105688868660766755366459722082203888205 | sample |
| 45643213451316 3498454549 |
45646711905865 | 第一个大数位数大于第二个 |
| 651612123 29516116160505 |
29516767772628 | 第二个大数位数大于第一个 |
| 12345 98765 |
111110 | 最高位相加有进位 |
| 1 1 |
2 | 一位数加一位数 |
3.4.4 PTA提交列表及说明
![]()
4.阅读代码
题目来源zoj 3109 Decode Message
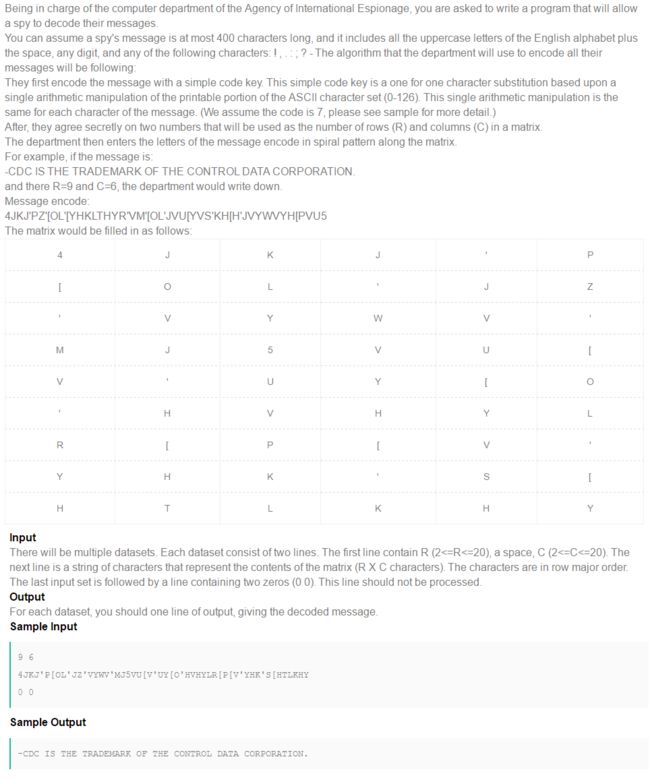
题意概括:首先在第一行输入两个数字,代表矩阵的行数和列数,第二行输入密文,按照第一行构建的矩阵螺旋排列,如果要结束程序,则输入0 0,不读取,然后对密文进行凯撒解密,输出解密完成后的字符串。

亮点分析:
- 这题的测试数据也是ACM型的,循环为“while (scanf("%d %d", &r, &c), r && c)”,利用逻辑表达式来实现判断作用,也是一种新的方法;
- 灵活运用字符输入和输出函数,在合适的地方吸收换行符,直接单个输出解密后的密文;
- 灵活运用了‘!’运算符改变变量的值,起到切换接口处理二维数组的目的;
- 代码处理二维数组的结构很强大,作者定义了7个变量来处理二维数组,利用rb,re,cb,ce四个变量作为边界的控制变量,isRow,isOrder两个变量来确定程序需要进入哪个结构进行操作,index变量来控制下标,把外层循环结构,内层的四个判断结构,四个循环结构紧密联系,使得解密有条不紊地准确进行;
- 总体而言,这段代码的亮点集中在变量的设置和控制上,在结构的合理设计上,我们可以学习作者对二维数组处理方法,对代码的严谨设计上。
- 选择这道题主要是因为题目花里胡哨,感觉很难,不好操作,但是仔细去理解它,发现其实思路并不难,这道题我认为是一道组合题,只要能够很好地操作这个二维数组,就不难做,然而这个处理方法与螺旋方阵有异曲同工之妙,因此不难想,关键是如何保证数组单元被正确地处理。至于凯撒密码解密的问题就简单多了。