hdfs是什么?
hdfs是一个分布式文件系统。它以文件分块的形式实现对大文件超大文件(G到T字节)安全的、可
靠的以及可快速(高吞吐量)访问的分布式存储。
问题:
1. hdfs是基于什么样的原理将文件分块存储到分布式环境中的各个设备上的?
2. hdfs是怎么来管理存储在各个设备上的分块文件的?
3. hdfs的错误检测和恢复机制是怎么实现的?
预想和目标(Assumptions and Goals)
硬件容错性
硬件错误发生比软件异常更寻常.HDFS集群由成千上万个服务器节点组成,发生硬件错误的几率更大.所以,错误检测和自动恢复机制就成为了HDFS的核心架构目标
流式数据访问
基于HDFS的应用是海量数据集的,所以HDFS被设计为跟适合批处理,高吞吐量的数据访问方式;而不是低延迟的数据访问方式.
大数据集
运行在HDFS之上的应用都是大数据集的.在HDFS上的文件范围都是在G和T之间的大小.在一个集群中应该要提供高聚合的数据宽带和可扩展的上百个节点.在一个集群应至少要支持上千万个文件.
简单的数据一致性模型
HDFS上的文件支持"一次写入多次读取"模式.一个文件一旦经过创建,写入,关闭这三个流程,便不再允许被改变(除非是在文件后面添加或者删除内容).
移动计算比移动数据更容易(Moving Computation is Cheaper than Moving Data)
一个应用的计算发生在存储数据的电脑上(也就是接近数据中心)是会更加高效的.尤其是当数据集很大的时候这种差别更加显著(这可以减少网络拥堵,提高系统吞度量).所以HDFS在做这种计算的时候,他会提供接口让运行程序走到数据的身边去而不是传输数据到运行程序.
Namenode和Datanode
hdfs采用master/slave架构。在hdfs系统中包含一个Namenode节点(管理文件系统的命名空间和监测客户端的文件访问请求)和多个Datanode节点(管理其运行机器上的数据存储)。Namenode节点负责管理存储hdfs中文件的元信息和文件块与Datanode之间的映射关系,并不负责存储文件的内容;Datanode负责管理和存储在他自己节点上的文件块内容。从hdfs系统的内部架构来看,一个文件被分成多个文件块存储在Datanode节点集上;而Namenode负责执行文件系统的操作(如文件打开,关闭,重命名等),同时确定和维护文件命名空间到各个数据块之间的映射关系。而DataNodes负责来自客户端的文件读写(即IO操作);同时DataNodes也负责文件块的创建,删除和执行来自NameNode的文件块复制命令.
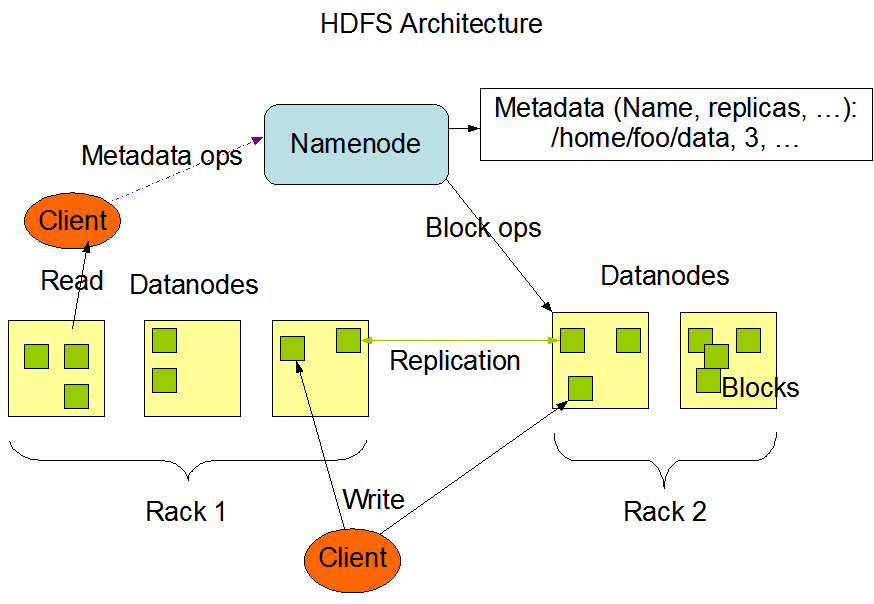
文件系统命名空间
HDFS支持传统的层级文件组织结构.用户或者应用可以创建目录,存储文件.这个文件系统命名空间层级结构类似于很多其他文件系统结构;可以创建、删除、移动和重命名文件和目录。
NameNode维护文件系统命名空间.任何有关文件系统的改变都会被NameNode记录下来.在应用中,我们可以给每个文件设置一个副本因子,通过这个副本因子的值可以来维护每个文件在整个系统中的副本数量.这些信息也同样会被记录在NameNode节点中.
数据复制
正如我们前面所说:hdfs是一个可靠的分布式文件系统。那么她是怎样来维护她的数据以让用户随时随地可以获取的呢?存储文件副本。hdfs把一个文件分成大小完全相同的若干份(最后一份除外,可能不够大)存储于各个Datanode节点之上,同时在其他的若干个Datanode节点上保存有各个文件块的副本。至于每个文件块的大小以及存放副本的个数可由系统配置。文件块怎么分配,分配在哪些节点上等这些操作的控制由Namenode节点来执行.Namenode会定期接受到来自各个DataNodes的心跳(Heartbeat)和块报告(Blockrepot).心跳可以检测一个DataNode是否可用,块报告包含一个DataNode上所有的数据块信息的列表.
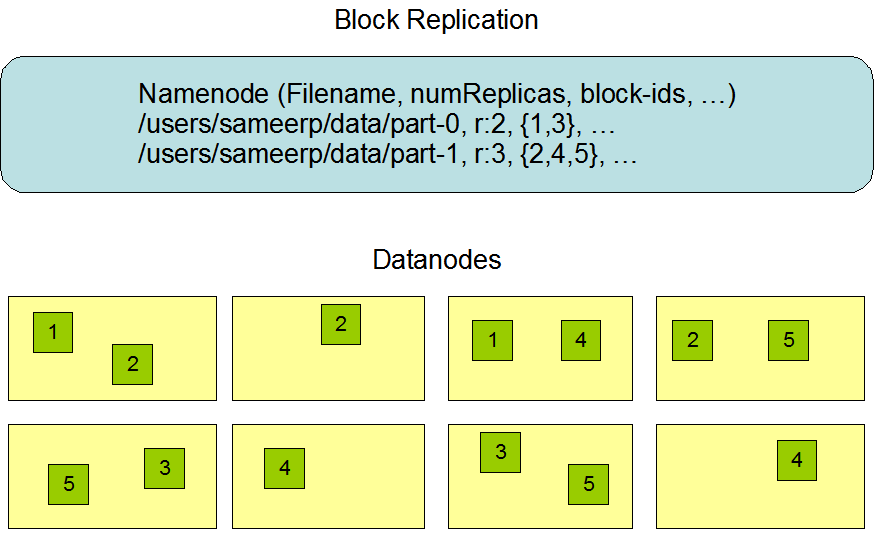
副本放置策略
HDFS集群会有成百上千个节点,而这些节点又被平均分配在若干个机架上面.节点所属机架,机架与机架之间不管是网络状况还是吞度量大小都是有很大影响的.所以副本怎样放置在不同的节点上,对整个系统文件的写入和读取效率以及系统容错能力都有很大关系.HDFS采用这样的策略: 假如现在有一个文件块要存储为3个副本,那应该怎么存,首先会在当前机架的某个DataNode上写入一个副本,在同机架的另一个DataNode上写入第二个副本,将第三个副本写到不同机架的DataNode上.
安全模式
在HDFS启动时,NameNode在一个时间段内会处于安全模式.在安全状态下,数据块的赋值不会发生.NameNode从DataNode节点接收Heartbeat和Blockreport信息.Blockreport包含DataNode上自己管理的数据块的列表信息.每一个数据块都有一个最小的副本数(这个值可以通过百分比的方式去配置),当一个数据块的副本数达到了这个最小值时被认为是可被安全复制的.当NameNode接收到所有这些数据块的可安全复制信息后就会自动关闭安全模式.然后由HDFS去执行剩余的复制工作,使每个数据块的副本数达到设置好的副本数量.
文件系统元数据的持久存储
HDFS文件系统的元数据信息被存储在NameNode节点上.NameNode节点使用事物日志(叫做EditLog)来持久记录发生在文件系统上面每个变化.例如:创建文件会在EditLog中插入一条记录,改变副本因子也会新增一条新的记录.NameNode会使用本地文件系统来保存这个EditLog内容.整个HDFS文件系统的命名空间,数据块与文件的映射关系,文件系统的各个属性都被存放在一个叫做FsImage的文件中,这个FsImage文件也放在NameNode节点的本地文件系统中.
NameNode会维护整个文件系统的命名空间和文件块的映射关系在内存中.这些文件系统的元数据被设计为非常紧凑的,一个4G内存的NameNode可以支持大量的文件和目录.当NameNode启动的时候,他会从磁盘读取FsImage和EditLog文件写入内存,然后将EditLog合并到FsImage中,同时把这个新的FsImage写到磁盘上;再删除那个老的EditLog文件(会再创建一个新的EditLog文件来记录文件系统的变化);从读取到内存到删除这个过程叫做checkpoint.checkpoint这个过程只会在NameNode启动时发生(SecondaryNameNode和CheckpointNode,BackupNode会定期执行checkpoint).
DataNode启动的时候,会扫描自己的文件系统生成一个HDFS数据块的列表,并把这个列表发送到NameNode.这个过程就是Blockreport.
数据组织
数据块
每个文件被分割为相同大小的数据块,一个典型的数据块大小为64M,每个数据块会被分配到不同的DataNode上.
分步(Staging)
客户端创建文件的请求不会立即到达NameNode节点.实际上,HDFS客户端会先缓存文件数据在本地临时文件中.当本地临时文件收集的数据块大小达到了数据块的大小,客户端才会联系NameNode.NameNode将文件名插入到HDFS文件系统结构中,并为此数据块分配block。然后NameNode将数据块所属的DataNode的id和datablock的id返回给客户端,客户端将本地临时文件中存储的数据写入到对应DataNode的datablock上。当文件关闭时,客户端将剩下没有flush的数据写到datablock上之后,再通知NameNode文件已经关闭了,在这个时候,NameNode才会提交文件创建的操作到EditLog文件中。所以如果NameNode在文件关闭前宕机了,那么这个文件信息就丢失了(虽然数据已经写到了DataNode上)。
复制流水线
当一个客户端写入数据到HDFS文件中,数据首先会写到本地临时文件中。假设HDFS文件的副本因子是3.当本地文件接收的数据量达到了一个数据块的大小,客户端就联系NameNode,获得一个存储这个数据块的DataNode节点集合。集合中指定的DataNode节点存储数据块的副本。客户端把数据块flush到第一个DataNode。第一个DataNode开始接收一小部分数据,并把这小部分数据写入到他本地的文件系统中,然后把这小部分数据传输给集合中的第二个DataNode,第二个DataNode做相同的工作直到最后一个节点。
hdfs被设计成支持大文件存储,适合那些需要处理大规模数据集的应用(写入一次,多次读取)。客户端上传文件到hdfs文件系统时,并不会马上上传到Datanode节点上,而是先存储在客户端本地临时文件夹下面,当本地存储数据量的大小达到系统数据块大小时,客户端联系Namenode节点从Namenode节点(Namenode节点将文件名存入他的文件系统中)获取数据块存储位置信息(包括副本数,存放的节点位置等信息),根据获取到的位置信息将本地临时数据块上传至对应的Datanode节点;当文件关闭时,客户端将剩余的数据量上传至Datanode节点,并告诉Namenode节点文件已关闭。Namenode节点收到文件关闭的消息时将日志写入到日志记录中。
存副本时的流式复制
客户端从Namenode节点获取到存储副本的节点信息之后(存储数据Datanode列表),开始写入第一个Datanode节点,Datanode节点一部分一部分的接收(一般是4kb)存入节点本地仓库,当这一部分写入完毕之后第一个Datanode节点负责将这部分数据转发到第二个Datanode节点,依次类推,直到第n-1个节点将这部分数据块写入第n个节点,如此循环写入。
磁盘数据错误、心跳检测和重新复制
hdfs的主要目标是可靠性,也就是即使在出错的情况下也要保证数据的可靠。主要的出错情况有三种:Namenode出错、Datanode出错和网络断裂。
Datanode周期性向Namenode报告自己节点的状态。网络断裂会导致部分Datanode与Namenode失去联系,此种情况下Namenode会根据节点的状态以及系统的副本数量来决定是否需要重新复制副本来控制执行。
参考文档:
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html