MySQL MHA架构介绍
MHA ( Master High Availability )目前在MySQL高可用方面是一个相对成熟的解决方案 ,它由日本DeNA公司youshimaton (现就职于Facebook公司)开发,是- 套优秀的作为MySQL高可用性环境 下故障切换和主从提升的高可用软件。在MySQL故障切换过程中, MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
github地址: https://github.com/yoshinorim
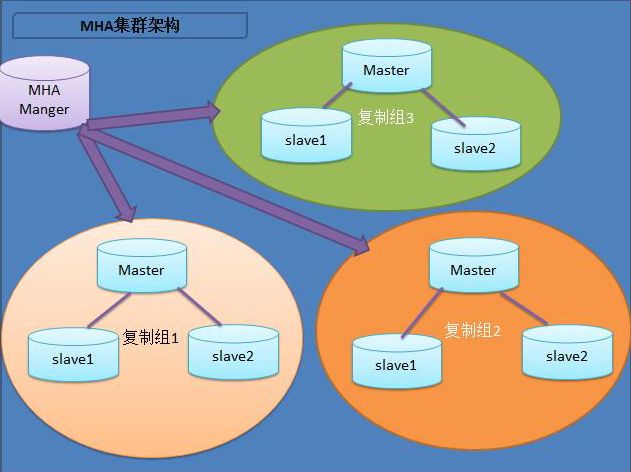
该软件由两部分组成: MHA Manager (管理节点)和MHA Node (数据节点)。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点 上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master ,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中, MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问, MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一-个slave已经收到了最新的二进制日志, MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求-个复制集群中必须最少有三台数据库服务器, -主二从,即一台充当master , -台充当备用master ,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。(出自 :《深入浅出MySQL(第二版)》 )
官方介绍: https://code.google.com/p/mysql-master-ha/
可以将MHA工作原理总结为如下:
(1)从宕机崩溃的master保存二 进制日志事件( binlog events);
(2)识别含有最新更新的slave ;
(3 )应用差异的中继日志( relay log )到其他的slave ;
(4)应用从master保存的进制日志事件( binlog events) ;
(5 )提升一个slave为新的master ;
( 6 )使其他的slave连接新的master进行复制;
MHA软件由两部分组成,ManagerI胞和Node工跑,具体的说明如下。
1 Manager工具包主要包括以下几个工具: 2 masterha .check_ ssh 检查HA的SSH配置状况 3 masterha_ check_ rep 1 检查MySQL复制状况 4 masterha manger 启动MHA 5 masterha check_ status 检测当前MHA运行状态 6 masterha master_ monitor 检测master是否宕机 7 masterha _master_ switch 控制故障转移(自动或者手动) 8 masterha conf_ host 添加或删除配置的server信息
1 Node.工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具: 2 save_ binary _logs 保存和复制master的二进制日志 3 apply_ _diff_ relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的s1ave 4 filter_ mysqlbinlog 去除不必要的ROLLBACK事件( MHA已不再使用这个工具) 5 purge_ relay_logs 清除中继日志(不会阻塞SQL线程)