Java并发是基于共享内存模型实现的。学习并深入地理解__Java内存模型__,有助于开发人员了解Java的线程间通信机制原理,从而实现安全且高效的多线程功能。
处理器内存模型
计算机在执行程序时,每条指令都是在__CPU__中执行的,而执行指令过程中,势必涉及到对主存中数据的读取和写入。由于__CPU__的处理速度相比对内存数据的访问速度快很多,如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在__CPU__里面就有了高速缓存。
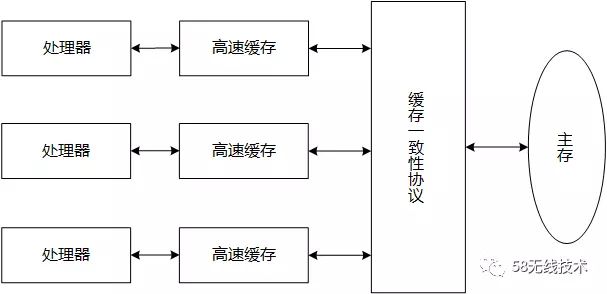
然而引入高速缓存带来方便的同时,也带来了缓存一致性的问题。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自缓存数据不一致的问题。解决方法是缓存一致性协议(如Intel 的MESI协议)。
MESI协议保证了每个缓存中使用的共享变量的副本是一致的。当CPU写数据时,如果发现操作的变量是共享变量,会发出信号通知其他CPU将该变量的缓存行置为无效状态。因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
除了增加高速缓存之外,为了使得处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行(Out-Of-Order Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致,因此,如果存在一个计算任务依赖另外一个计算任务的中间结果,那么其顺序性并不能靠代码的先后顺序来保证。
Java内存模型
Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
为了方便理解Java内存模型,我们可以抽象地认为,所有变量都存储在主内存中(Main Memory),每个线程都拥有一个私有的工作内存(Working Memory),保存了该线程已访问的变量副本。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。
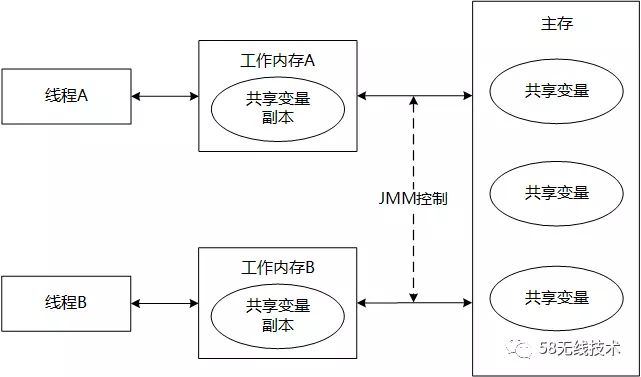
假设__线程A__要向__线程B__发消息,__线程A__需要先在自己的工作内存中更新变量,再将变量同步到主内存中,随后__线程B__再去主内存中读取A更新过的变量。因而可以看出,JMM通过控制主内存与每个线程的本地内存之间的交互,提供内存可见性保证。
内存交互操作
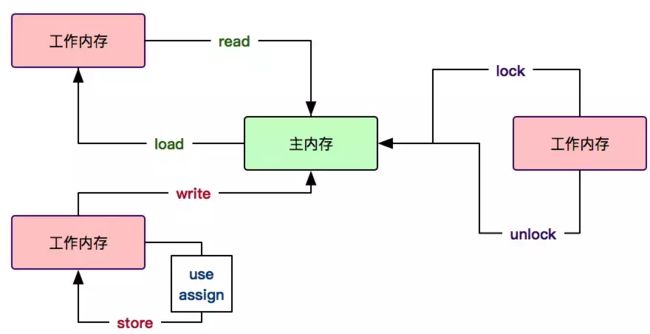
Java内存模型定义的8个操作指令来进行内存之间的交互,如下:
read读取主内存的值,并传输至工作内存。
load将read的变量值存放到工作内存。
use将工作内存的变量值,传递给执行引擎。
assign执行引擎对变量进行赋值。
store工作内存将变量传输到主内存。
write主内存将工作内存传递过来的变量进行存储。
lock用作主内存变量,它把一个变量在内存里标识为一个线程独占状态。
unlock用作主内存变量,它对被锁定的变量进行解锁。
工作内存和主内存间的指令操作交互,如下图所示:
指令规则
read 和 load、store和write必须成对出现
assign操作,工作内存变量改变后必须刷回主内存
同一时间只能运行一个线程对变量进行lock,当前线程lock可重入,unlock次数必须等于lock的次数,该变量才能解锁。
对一个变量lock后,会清空该线程工作内存变量的值,重新执行load或者assign操作初始化工作内存中变量的值。
unlock前,必须将变量同步到主内存(store/write操作)。
重排序
在没有正确同步的情况下,即使要推断最简单的并发程序的行为也很困难。代码如下:
public class PossibleReordering {
static int x = 0, y = 0;
static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();
other.start();
one.join();other.join();
System.out.println(“(” + x + “,” + y + “)”);
}
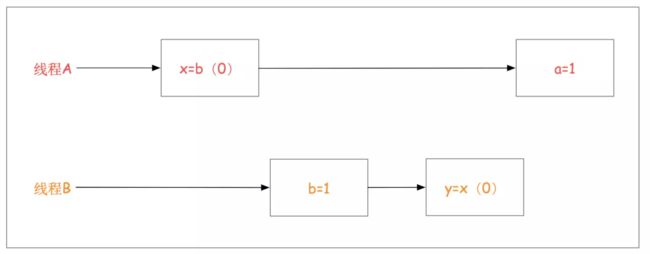
很容易想象PossibleReordering的输出结果是(1,0)或(0,1)或(1:1)的,__但奇怪的是__还可以输出(0,0)。
由于每个线程中的各个操作之间不存在数据依赖性,因此这些操作可以乱序执行。下图给出了一种可能由重排序导致的交替执行方式,在这种情况中会输出(0,0)。
Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图所示:

在执行程序时,为了提高性能,编译器和处理器会对指令做重排序。重排序分3种类型:
编译器优化重排序。编译器在不改变单线程程序语义(as-if-serial semantics)的前提下,可重新安排语句的执行顺序。
指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
先行发生原则(happens-before)
为了提高执行性能,JMM允许编译器和处理器对指令进行重排序。但是Java语言保证了操作间具有一定的有序性,概括起来就是先行发生原则(happens-before)。也就是说,如果两个操作的关系无法被happens-before原则推导,则无法保证它们的顺序性,有可能发生重排序。happens-before原则包括:
程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
锁定规则:一个unlock操作先行发生于后面对同一个锁的lock操作。
volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作
线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
线程终结规则:线程中的所有操作都先行发生于对此线程的终止检测
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
对象终结规则:一个对象的初始化完成先行发生于它的finalize()方法的开始
传递规则:如果操作A先行发生于操作B,操作B先行发生于操作C,则有A先行发生于操作C。
实际上,这些规则是由编译器重排序规则和处理器内存屏障插入策略来实现的。
内存屏障
内存屏障是一条CPU指令,用于控制特定条件下的重排序和内存可见性问题。即任何指令都不能与内存屏障指令重排序。
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
处理器对重排序的支持

从上面可以看到不同的处理器架构对重排序的支持也是不一样(其它处理器架构暂不罗列),所以不同的平台JMM的内存屏障施加也略有不同,具体来说,比如 X86 对Load1Load2不支持重排序,那么你就没有必要施加LoadLoad屏障。
volatile的内存语义
volatile关键字用来保证数据可见性,防止指令重排的效果。包括JUC里AQS Lock的底层实现也是基于volatitle来实现。
volatile写的内存语义:当写一个volatile变量的时候,JMM会把该线程对应的本地内存变量值刷新到主内存。
volatile读的内存语义:当读一个volatile变量的时候,JMM会把线程本次内存置为无效。线程接下来将从主内存中读取共享变量(也就是重新从主内存获取值,更新运行内存中的本地变量)。
final的内存语义
final修饰的称作域,对于final域,编译器和处理器要遵守两个重排序规则
写规则:在构造函数内对一个final域的写入,与随后把这个被构造的对象的引用赋值给一个引用变量,这两个操作不可重排序。
JMM禁止编译器把final域的写重排序到构造函数之外, 编译器会在final域写入的后面插入StoreStore屏障,该规则可以保证在对象引用为任意线程可见之前,对象的final域已经被正确初始化,而普通域无法保障。
读规则:初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作。编译器会在读final域操作的前面插入一个LoadLoad屏障。
类库Happens-Before
由于Happens-Before的排序功能很强,因此有时候可以“借助”现有机制的可见性属性。这需要将Happens-Before的程序顺序规则与其他某个顺序规则(通常是监视器锁规则或者volatile变量规则)结合起来,从而对某个未被锁保护的变量的访问操作进行排序。由类库担保的其他happens-before排序包括:
将一个元素放入线程安全容器happens-before于另一个线程从容器中获取元素。
执行CountDownLatch中的倒计时happens-before于线程从闭锁(latch)的await中返回。
释放一个许可证Semaphorehappens-before于从同一Semaphore里获得一个许可。
Future表现的任务所发生的动作happens-before于另一个线程成功地从Future.get中返回。
向Executor提交一个Runnable或Callable happens-before于开始执行任务。
一个线程到达CyclicBarrier或Exchanger happens-before于相同关卡(barrier)或Exchange点中的其他线程被释放。如果CyclicBarrier使用一个关卡(barrier)动作,到达关卡happens-before于关卡动作,依照次序,关卡动作happens-before于线程从关卡中释放。