对于初学大数据的萌新来说,初次接触Hadoop伪分布式搭建的同学可能是一脸萌笔的,那么这一次小编就手把手的教大家在centos7下搭建Hadoop伪分布式。
底层环境: VMware Workstation 15.0,centos7
SSH工具: xshell
软件包: hadoop-2.7.6.tar.gz jdk-8u201-linux-x64.tar.gz
由于对于大数据的学习初期的同学,对于centos的安装应该非常熟练,故在这里不详述,这里我们开始说具体的步骤:
这里给出大家一个思维导图,方便大家对于伪分布式搭建的理解。
思维导图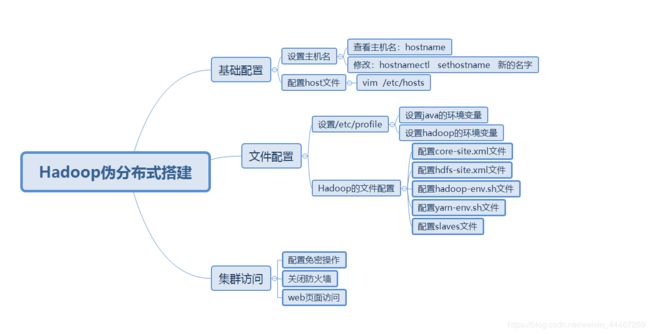
第一步:网络配置
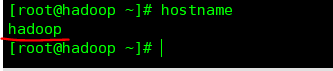
(1)查询主机名
查询命令:
hostname
修改命令:
hostnamectl set-hostname 新的名字
示例图片 :
(2) 查询IP 地址
查询命令:
ip add
注释:
ip add 适用于centos7及以后的版本;
ifconfig 适用于centos6及其以前的版本;
那么问题来了,我们怎么知道那个是我们的IP地址呢?
当然,小编,在这里给大家准备了具体的实例图片:

图例解释:
ip add 就是我们上文提到的查询IP地址的命令;
172.17.54.7 就是我们需要的IP地址。
(3)设置/etc/hosts 文件
使用vim ,编辑/etc/hosts 文件;
相信大家对于编辑文件都是信手拈来,那么我们看看具体哪个是/etc/hosts 文件呢?
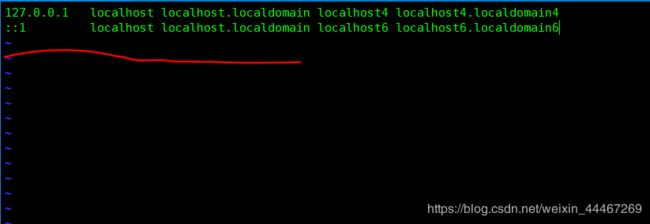
没错,这就是传说中的/etc/hosts 文件.
在这里我们需要把我们查到的具体ip 地址输入到我们的第三行,也就是红线的地方;
背后我们需要加上空格输入自己的主机名;
举个栗子就是:192.168.255.230 你的主机名
(二)环境变量的配置
我们使用xshell将我的hadoop和jdk上传到目录下后,解压。就可以开始配置环境变量了,我们在环境变量配置这一块有很多个地
方,比如说/etc/profile和~/.bashrc。这两个地方都是可以配置环境变量的。
为了方便我们的后期的使用,我们这里将hadoop和jdk进行了改名,因为他们的名字非常的长,不容易记忆。
所以我们需要对它进行简单化操作,我们将其改名为hadoop和jdk1.8,方便我们的后期的配置,
为后文埋下伏笔。
这里我们先看看具体的图片,环境变量的文件到底是何方神圣:

没错,这就是传说中的环境变量。
在这里我们需要设置我们的jdk和hadoop的环境变量。
在小编红线圈起来的地方,我来给大家具体详解一下我们需要输入的内容。
export JAVA_HOME=你的jdk所在的路径精确到jdk1.8
// 此处我们设置Java的home
export HADOOP_HOME=你的hadoop所在的路径精确到我们改名后的hadoop
// 此处我们设置hadoop的home
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
// 此处我们将我们设置好的两个jdk和hadoop的home导入环境变量
// ------/bin 这个目录下存放的是常用的环境变量。
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
// 此处我们具体设置我们hadoop常用的命令,也将他导入进来。
exportPATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_COMMON_LIB_NATIVE_DIR:$PATH
// 此处我们将所有的配置都导入环境变量之中。
配到这里我们距离成功已经很近了,这是后我们需要重启环境变量才能开始使用
source /etc/profile
// 重启环境变量
如果重启环境变量,没有报错。我们就可以开始查看我们是否配置成功了
查看jdk的版本号
java -version
那么我们怎么知道是不是对的·呢?
小编在这里给大家准备了具体的示例图片:

如果查询到的版本号和你下载的版本好相符,那么我们的环境变量就大功告成了!!
这样的话我们的配置差不多就走了二分之一了,接下来我们具体看Hadoop的配置如何走呢?
环境变量测试成功
(三)Hadoop的配置
对于Hadoop的文件配置,我们需要配置大约有五个文件,分别是:
(1) core-site.xml (2)hdfs-site.xml (3)hadoop-env.sh (4)yarn-env.sh (5)slaves
(1)core-site.xml
首先,给大家看看具体core-site.xml文件的具体内容:

然后我们开始上手编辑内容,切记我们多有的内容都必须写在
这里写我们编辑的内容
那么我们需要写什么配置信息呢?
这里我们需要写上我们的配置信息先给大家看看模板:
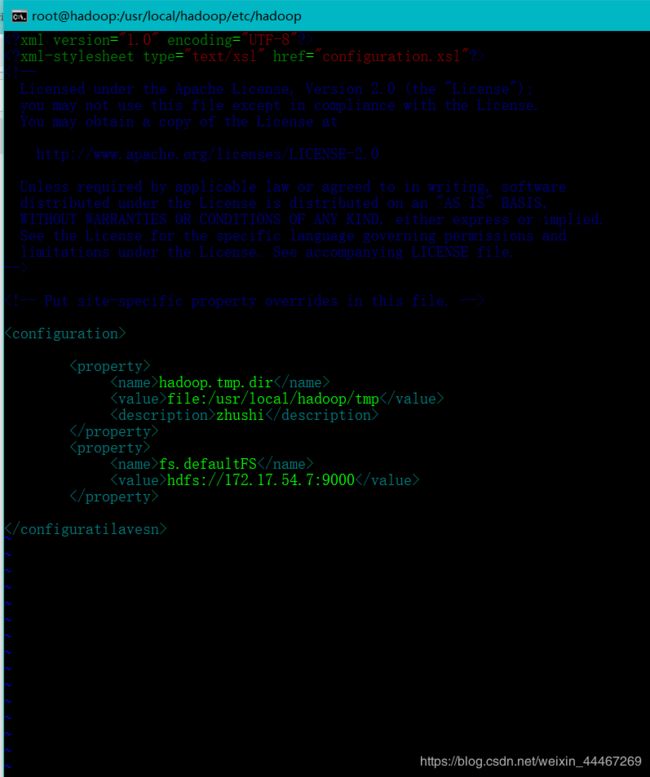
那么下来我们具体说一下这些代码都是啥意思
hadoop.tmp.dir // 设置存储name,data文件的存放文件file:/usr/local/hadoop/tmp // 设置此文件的绝对路径zhushi //添加注释,可有可无fs.defaultFS // 设置访问此集群的端口hdfs://hadoop:9000 //设置具体的IP,具体的端口,此处可以写自己的主机名
(2) hdfs-site.xml
接下来我们具体设置hdfs-site.xml文件:
同样的道理我们需要在
这里写我们编辑的内容
这里我也给出大家一个模板:
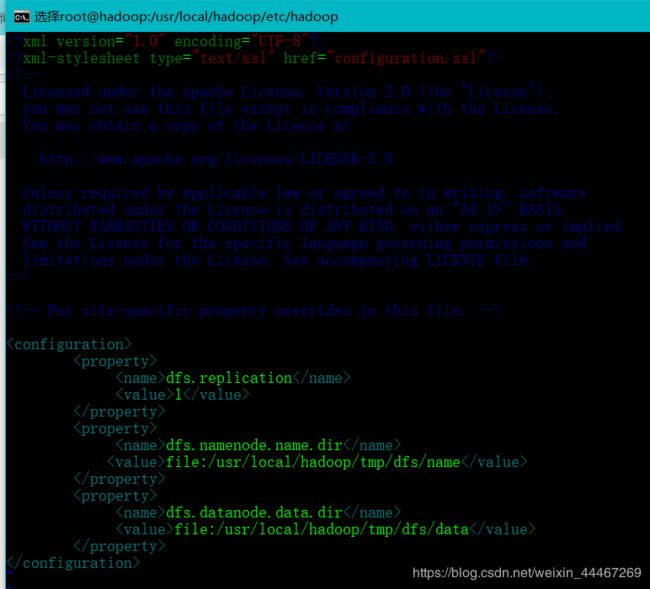
作为第一次发文章的我考虑到大家对这个不是很了解,继续给大家讲讲具体的内容
dfs.replication //需要设置的数据块1 // 这里伪分布式为1dfs.namenode.name.dir // 设置namenode的存放文件file:/usr/local/hadoop/tmp/dfs/name //namenode文件存放的绝对路径dfs.datanode.data.dir // 设置datanode的存放文件file:/usr/local/hadoop/tmp/dfs/data // 设置datanode文件存放的绝对路径
(3) hadoop-env.sh
为了保证文件的正确性,这是具体的文件图片:
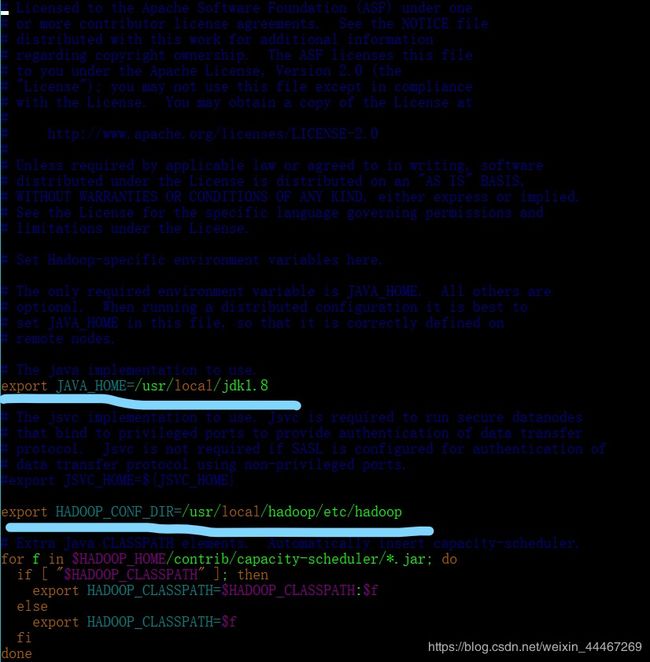
export JAVA_HOME=/你的jdk存放路径 可以参考你的环境变量的路径
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=/你改名后的hadoop文件的存放路径/etc/hadoop // 用来寻找你的hadoop的配置文件
(4) yarn-env.sh
这里的yarn-env.sh文件配置非常的简单,我们距离成功共可以说是近在咫尺了。
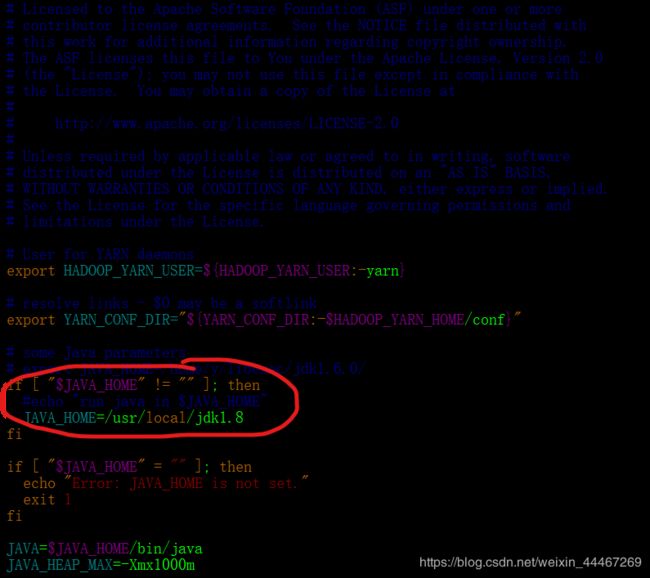
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/conf}"
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/local/jdk1.8 // 这一行是我们需要配置的,我们j这里需要加入jdk的文件存放的路径;
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
(5) slaves
这一块我们需要插入具体的主机名,就是我们刚才的写在/etc/hosts里,IP地址之后的名字。

(四)配置免密操作
执行如下命令:
ssh-keygen -t rsa // 进行免密操作
发送密钥到指定文件夹
ssh-copy-id -i .ssh/id_rsa.pub 用户名字@192.168.x.xxx
(五)格式化hdfs
### 格式化命令
hdfs namenode -format
(六)集群成功与否校验
start-all.sh // 启动hdfs

start-yarn.sh // 启动守护进程

最后、我们使用jps查看自己的节点,这里给大家配上图片
jps 查看集群节点
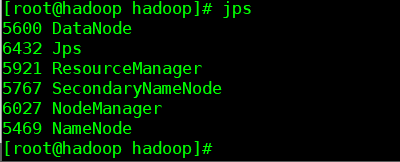
没错,如果到了这里,你成功了,你就非常牛逼了,你就是万中无一的建站奇才,升职加薪,走上人生巅峰,
指日可待。
# (七)集群web访问
如果你希望通过web浏览器访问集群的华,那我们小编就来教你怎么做
(1)关闭防火墙
systemctl stop firewalld.service
(2)关闭开机自启
systemctl disable firewalld.service
(3)输入你的ip地址加端口号
http://hostname:50070
这样给大家看看最后的结果:

如果是这样:那么我们访问差不多就成功了,确认是否有对应数据,没有的话,就是存在问题,继续检查自己的代码数据,这是第一次写博客,如果有什么问题,请大家指正,有什么问题,大家可以在下方留言评论。谢谢大家