知识点
- scikit-learn 对于线性回归提供了比较多的类库,这些类库都可以用来做线性回归分析。
- 我们也可以使用scikit-learn的线性回归函数,而不是从头开始实现这些算法。 我们将scikit-learn的线性回归算法应用于编程作业1.1的数据,并看看它的表现。
- 一般来说,只要觉得数据有线性关系,LinearRegression类是我们的首选。如果发现拟合或者预测的不好,再考虑用其他的线性回归库。如果是学习线性回归,推荐先从这个类开始第一步的研究。
- LinearRegression 的使用非常简单,主要分为两步:
- 使用 fit(x_train,y_train) 对训练集x, y进行训练。
- 使用 predict(x_test) 训练得到的估计器对输入为 x_test 的集合进行预测。( (x_test) 可以是测试集,也可以是需要预测的数据)
过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
path = 'D:\BaiduNetdiskDownload\data_sets\ex1data1.txt'
# pd.read_csv 将 TXT 文件读入并转化为数据框形式
# names 添加列名
# header 用指定的行来作为标题(表头),若原来无标题则设为 none
# 用到 Pandas 里面的 head( ) 函数读取数据(只能读取前五行)
data = pd.read_csv(path,header=None,names=['Population','Profit'])
data.head()
# 在训练集中插入一列1(其实是x0=1),方便我们可以使用向量化的解决方案来计算代价和梯度。
data.insert(0, 'Ones', 1)
# set X(training set), y(target variable)
# 设置训练集X,和目标变量y的值
cols = data.shape[1] # 获取列数
X = data.iloc[:,0:cols-1] # 输入向量X为前cols-1列
y = data.iloc[:,cols-1:cols] # 目标变量y为最后一列
# 代价函数是应该是 numpy 矩阵,所以我们需要转换X和Y,然后才能使用它们。 我们还需要初始化 theta 。
X = np.array(X.values)
y = np.array(y.values)
theta = np.array([0,0])
核心代码:
from sklearn import linear_model
# 需要导入LinearRegression类,并将之实例化,并采用fit()方法已验证这些训练数据。
model = linear_model.LinearRegression()
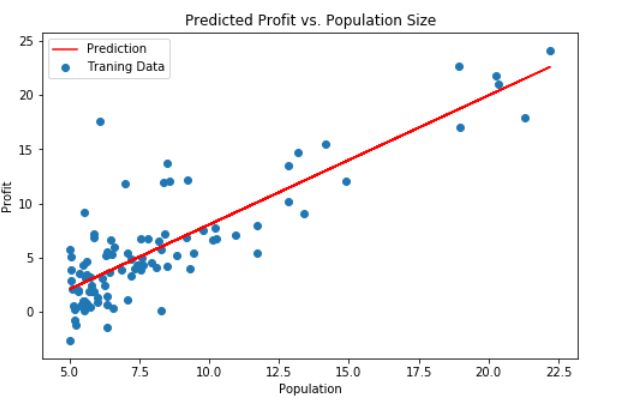
model.fit(X, y) # fit(X, y)对训练集X, y进行训练scikit-learn model的预测表现:
x = np.array(X[:, 1])
f = model.predict(X).flatten() # .flatten() 默认按行的方向降维
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
参考资料
python_sklearn机器学习算法系列之LinearRegression线性回归
吴恩达机器学习作业Python实现(一):线性回归
scikit-learn 线性回归算法库小结